Data classification identifier determination method, device, electronic equipment and storage medium
A data classification and determination method technology, applied in the computer field, can solve the problems of inability to label data, high time cost, large amount of data, etc., and achieve the effect of improving convenience and efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
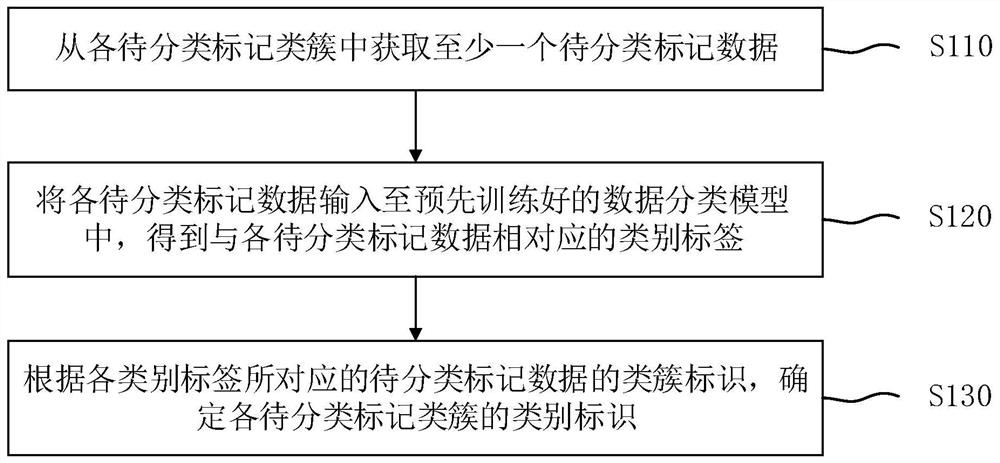
[0027] figure 1 It is a schematic flow chart of a method for determining a data classification identifier provided by Embodiment 1 of the present invention. This embodiment is applicable to the situation of classifying hundreds of millions of data, and the method can be executed by a data classification identifier determination device , the apparatus may be implemented in the form of software and / or hardware, and the hardware may be an electronic device, such as a mobile terminal or a PC.
[0028] Before introducing the technical solution, an example description may be given to the application scenario. In medical scenarios, hundreds of millions of data can be generated every day. Some data categories in these data are the same, and some data categories are different. Optionally, if it is medical data, the medical data may include data corresponding to different disease types, and the disease levels corresponding to different disease types are different. Exemplarily, the di...
Embodiment 2
[0062] As an optional embodiment of the above embodiment, figure 2 It is a schematic flowchart of a method for determining a data classification identifier provided in Embodiment 2 of the present invention. see figure 2 , to obtain unlabeled sample data, that is, to obtain unlabeled labeled data to be classified. Using existing data clustering methods, the labeled data to be classified is clustered into M clusters. According to the preset total amount of data, stratified sampling is performed on each labeled cluster to obtain at least one labeled data to be classified. That is, to cluster the unlabeled samples N, because it is big data, store and calculate it on the cloud computing platform Hadoop, use spark-based K-means, hierarchical clustering and other clustering algorithms to divide the unlabeled samples into m clusters, and the number of samples in each cluster is Ni, where i=1,2,...,m. 3. Perform stratified sampling for each cluster Ni, draw p% samples, take the c...
Embodiment 3
[0066] image 3 A schematic structural diagram of a device for determining a data classification identifier provided by Embodiment 3 of the present invention, the device includes: a data determination module 310 , a category label determination module 320 and a category identifier determination module 330 .
[0067] Among them, the data determination module 310 is used to obtain at least one label data to be classified from each label cluster to be classified; the category label determination module 320 is used to input each label data to be classified into a pre-trained data classification model, Obtain the category label corresponding to each labeled data to be classified; wherein the data classification model is trained based on the training data and the category label corresponding to the training data; the category identification determination module 330 is used for according to each category label The corresponding cluster identifiers of the labeled data to be classified...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More