Crack identification method based on deep learning
A technology of crack identification and deep learning, applied in the field of crack identification based on deep learning, can solve the problems of poor recognition efficiency, accuracy and adaptability, and achieve the effect of solving the shortage of training set data samples and improving recognition efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



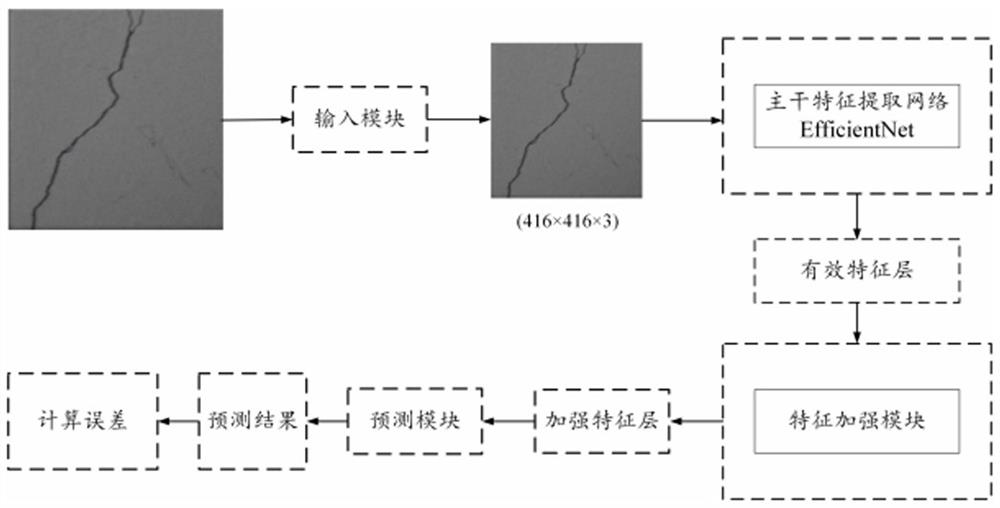
Examples
Embodiment Construction
[0058] The application will be described in detail below in conjunction with the accompanying drawings.
[0059] Embodiments of the present application are described below through specific examples, and those skilled in the art can easily understand other advantages and effects of the present application from the content disclosed in this specification. Apparently, the described embodiments are only some of the embodiments of this application, not all of them. The present application can also be implemented or applied through other different specific implementation modes, and various modifications or changes can be made to the details in this specification based on different viewpoints and applications without departing from the spirit of the present application. It should be noted that, in the case of no conflict, the following embodiments and features in the embodiments can be combined with each other. Based on the embodiments in this application, all other embodiments obta...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com