

Multi-dimensional training method and device of support vector machine
A technology of support vector machine and training method, which is applied in the field of multi-dimensional training method and device of support vector machine, can solve problems such as difficult to mine data relationship or connection, low analysis accuracy, complex operation, etc., and achieve improved classification and analysis Ability to improve the effect of linear separability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


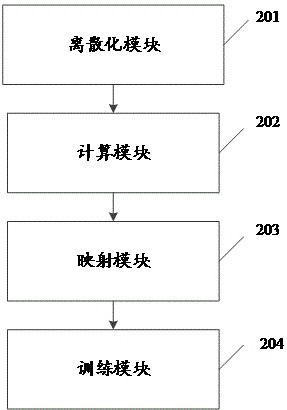
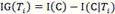
Examples
Embodiment Construction
[0073]The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
[0074] The current commonly used training methods have the following technical problems: because the training data requires the user to manually adjust the relationship between each data, the operation is complicated, and SVM can only be trained through the data relationship input by the user, it is difficult to mine data in different dimensions relationship or connection, the accuracy of the analysis after training is low, which does not meet the actual use requirem...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More