Multimodal image processing method and system based on Transform network and hypersphere space learning
A multi-modal image and processing method technology, applied in the field of deep learning, can solve problems such as unreasonable application settings and limited performance of the basic network structure, improve the ability of modeling and aligning multi-modal distributions, and achieve zero-sample spanning Modal retrieval, the effect of eliminating the problem of modality difference
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
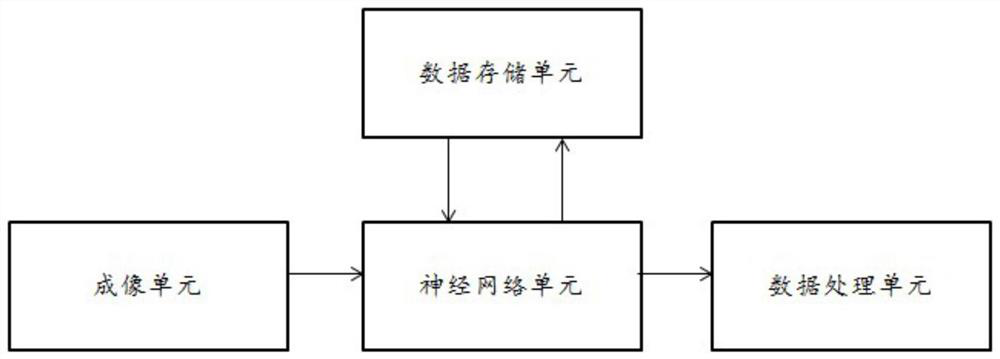
[0025] Such as figure 1 As shown, the present invention is a multimodal image processing method based on Transformer network and hypersphere space learning, including steps S1 to S5.
[0026] S1: Obtain the pre-trained Transformer network model, and fine-tune the pre-trained Transformer network model in a self-supervised manner based on the image data of each modality to obtain the teacher model.
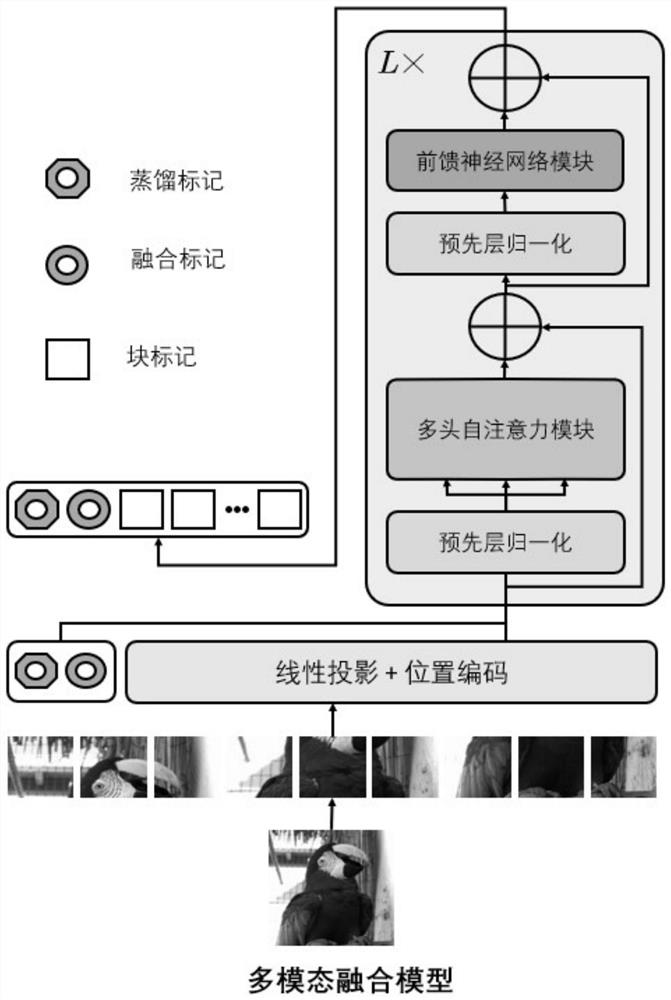
[0027] The Transformer network was first proposed in the field of natural language processing, with serialized text data as input. Recently, the Transformer network structure has been improved to handle image data and perform well in the field of computer vision. Such as image 3 (Ignoring the fusion mark and distillation mark), the Transformer network structure consists of L layers of multi-head self-attention modules alternately and feed-forward neural network modules, where each module contains pre-layer normalization and residual connections. It cuts each image into a series ...
Embodiment 2
[0062] In this embodiment, on the basis of embodiment 1, experimental verification is carried out. In this embodiment, three mainstream datasets in the field of zero-sample cross-modal retrieval are used as training and testing datasets, namely Sketchy, TU-Berlin, and QuickDraw. They both contain data and labels for photo modality and sketch modality for zero-shot photo-sketch retrieval task. Specifically, Sketchy is initially composed of 75,471 sketches and 12,500 photos in 125 categories, and there is a pairing relationship between sketches and images. Since then, Sketchy's photo collection has been expanded to 73,002. TU-Berlin consists of 20,000 sketches and 204,489 photos of 250 categories, so the number of sketches and photos is seriously unbalanced, and the abstraction of sketches is high; QuickDraw is the largest of the three datasets, consisting of 110 categories Consisting of 330,000 sketches and 204,000 photos, the sketches are the most abstract.
[0063] For Ske...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com