Coded text generation method and device based on adversarial training and electronic equipment
A technology of electronic equipment and training methods, applied in the field of data processing, can solve problems such as reducing the robustness of the model, and achieve the effect of improving comprehension ability and coding efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

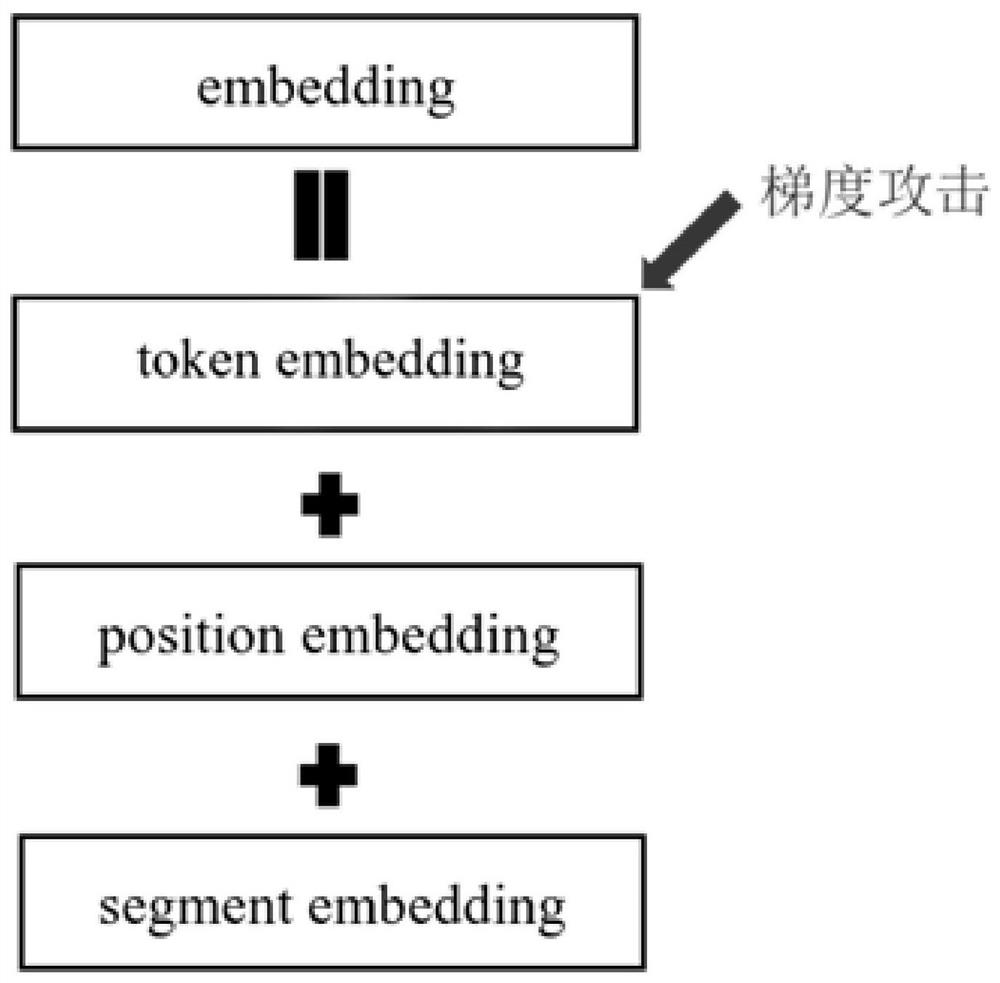
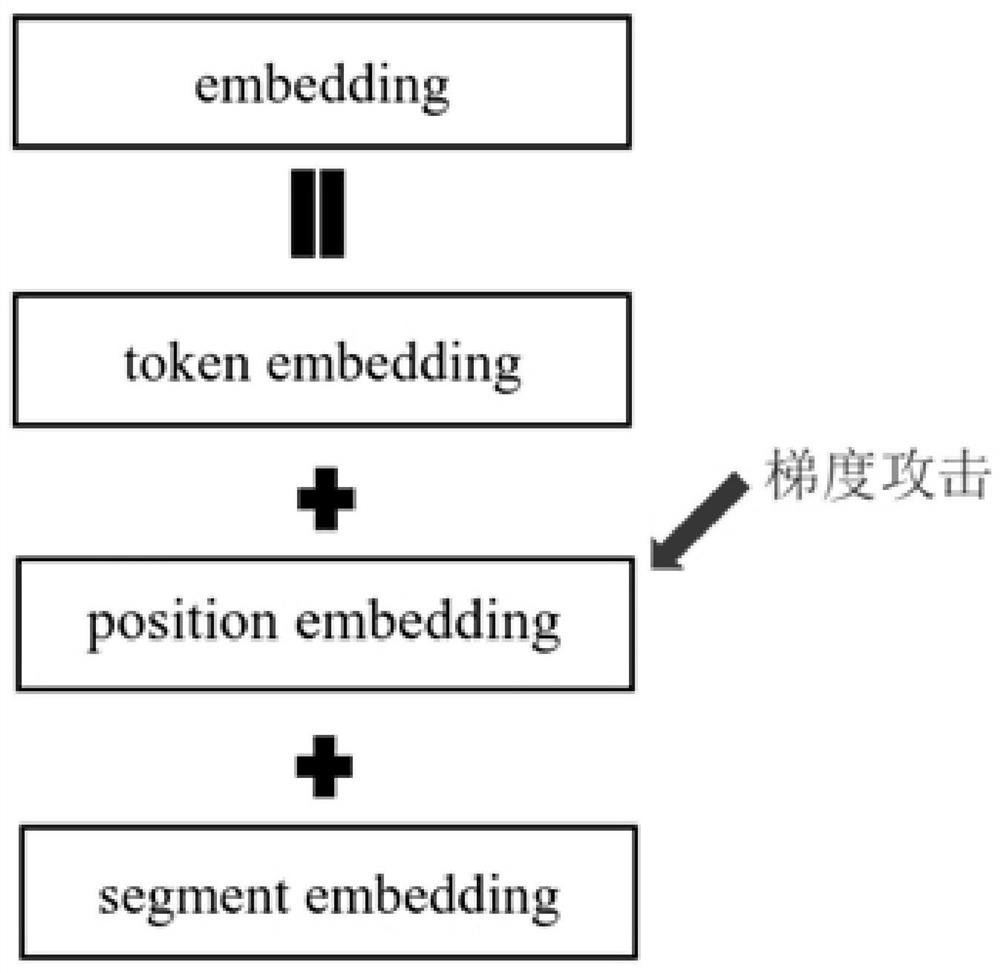
Examples
Embodiment Construction
[0047] In order to make the objectives, technical solutions and effects of the present invention clearer and clearer, the present invention will be described in further detail below. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
[0048] The embodiments of the present invention are described below with reference to the accompanying drawings.
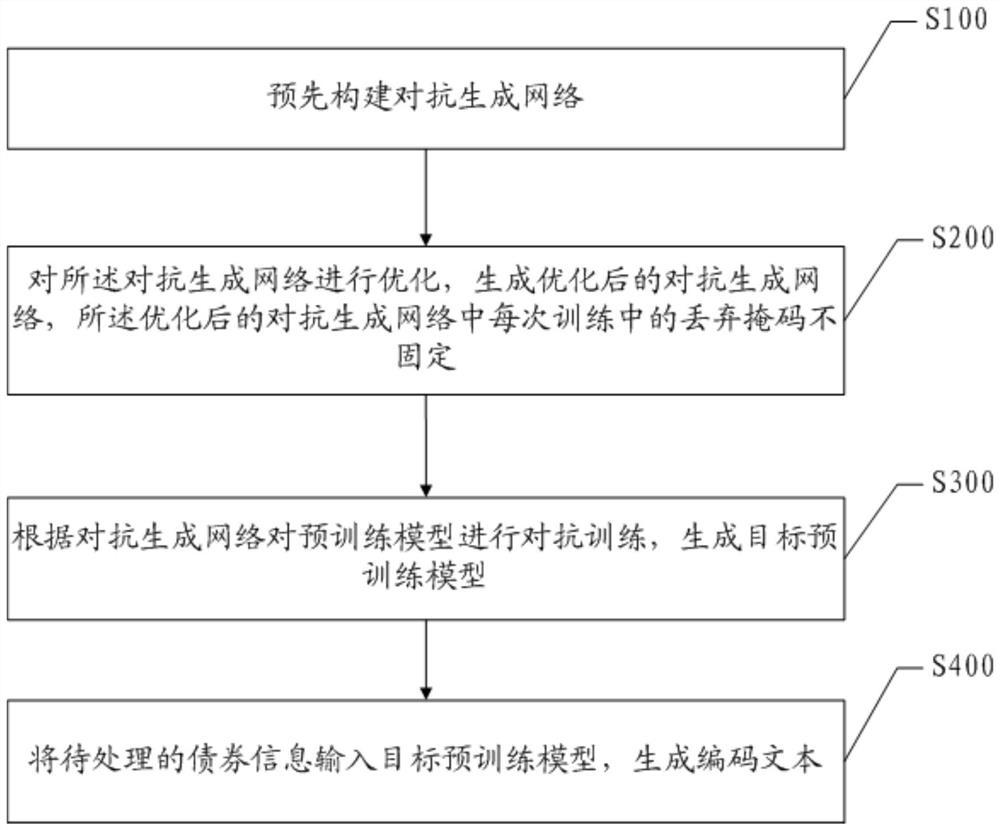
[0049] In view of the above problems, an embodiment of the present invention provides a method for generating encoded text based on adversarial training, please refer to figure 1 , figure 1 This is a flow chart of a preferred embodiment of a method for generating encoded text based on adversarial training of the present invention. like figure 1 shown, it includes:
[0050] Step S100, constructing an adversarial generation network in advance;
[0051] Step S200, optimizing the confrontation generation network to generate a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More