Human body behavior monitoring method and system and storage medium
A human body and behavior technology, applied in a variety of biometric applications, voice analysis, instruments, etc., can solve the problems of wearing sensors to detect danger, inconvenient behavior, etc., to solve the problem of inconvenient detection of dangerous behavior, avoid discomfort, avoid Detect inconvenient effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
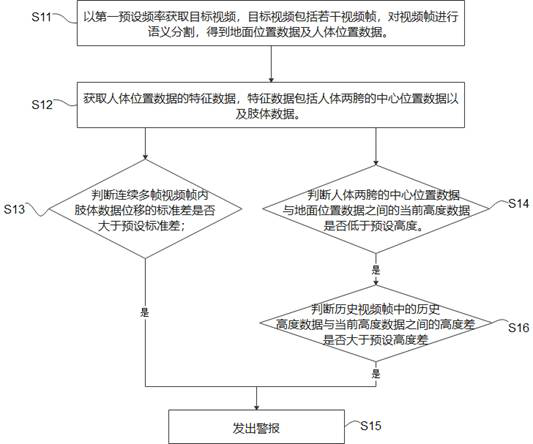
[0048] see figure 1 , which shows the human behavior monitoring method in the first embodiment of the present invention, including steps S11-S16.
[0049] S11. Acquire a target video at a first preset frequency, where the target video includes several video frames, and perform semantic segmentation on the video frames to obtain ground position data and human body position data.
[0050]The human behavior monitoring method in this embodiment can be applied to the monitoring of patients in the hospital and the monitoring of the elderly at home. The camera obtains the real-time behavioral feature video of the ward according to the first preset frequency, and judges whether the ward's real-time behavioral feature conforms to the behavior of falling, convulsing or alarming behavior, so as to alarm and improve the safety of the ward. First, obtain the target video of the supervised person at the first preset frequency, the target video includes the supervised person and the surroun...
Embodiment 2
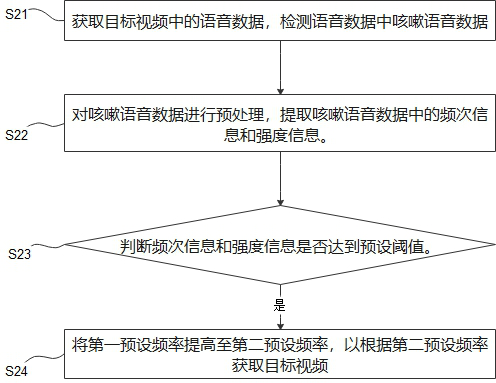
[0079] see figure 2 , shows the human behavior monitoring method in the second embodiment of the present invention, the behavior monitoring method in this embodiment is based on the method in the first embodiment, by detecting the cough voice in the video voice, and then adjusting the obtained video in the first embodiment The preset frequency to adjust the frequency of detection of human behavior features in the video. The method in this embodiment includes steps S21-S24.
[0080] S21. Acquire voice data in the target video, and detect cough voice data in the voice data.
[0081] The voice module set in the camera can be used to obtain the voice data of the guardian, obtain the target video through the camera, the target video includes the voice data of the guardian, and detect whether there is a cough in the voice data through an algorithm, such as through a hidden Markov model ( Hidden Markov Model, HMM) can quickly and accurately identify the cough voice data in the voi...
Embodiment 3
[0101] Another aspect of the present invention also provides a human behavior monitoring system, please refer to image 3 , the block diagram of the human behavior monitoring system in this embodiment is shown, including:
[0102] a semantic segmentation module, configured to acquire a target video at a first preset frequency, where the target video includes several video frames, and perform semantic segmentation on the video frames to obtain ground position data and human body position data;
[0103] a special data extraction module, used to obtain the feature data of the human body position data, the feature data includes the center position data of the two crotch of the human body and the limb data;
[0104] A twitching behavior judgment module, configured to obtain continuous multi-frame video frames of the target video according to the limb data, and determine whether the standard deviation of the displacement of the limb data in the continuous multi-frame video frame is ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More