Large-scale data analysis method based on DBSCAN algorithm
A technology of large-scale data and analysis methods, applied in the field of large-scale data analysis based on the DBSCAN algorithm, can solve the problems of large time consumption of the partition process, complex distribution, unstable partition effect and performance, and reduce idle waiting time. , the effect of reducing traffic
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0031] The technical scheme of the present invention is further described below in conjunction with the accompanying drawings of the description:
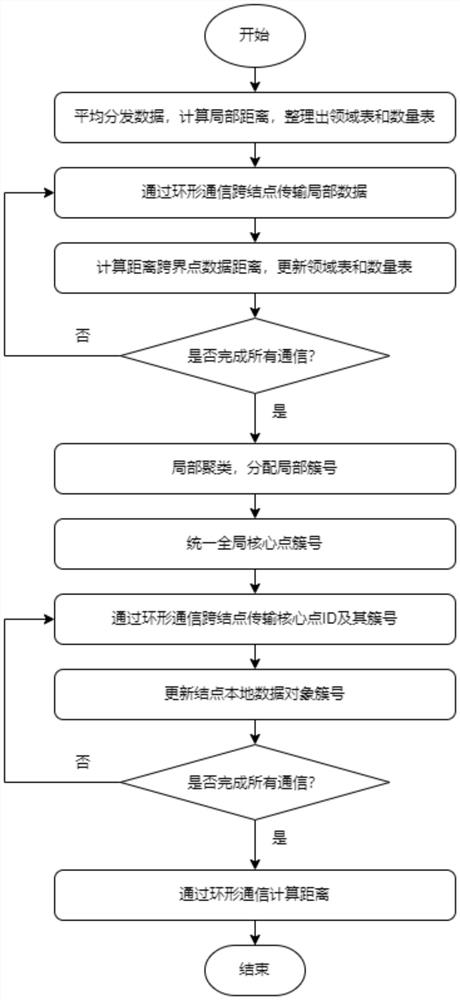
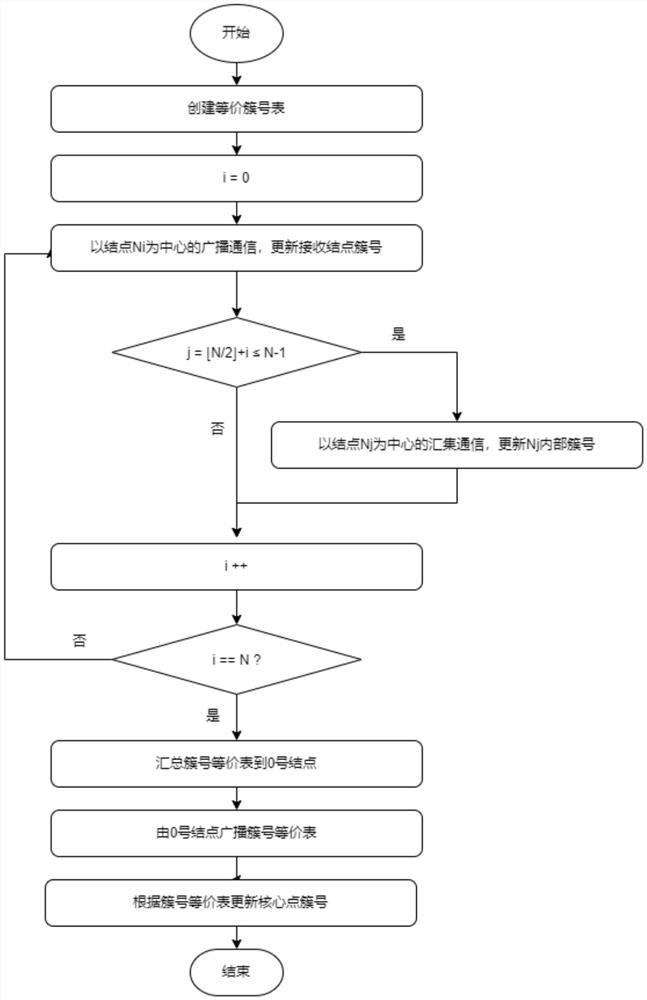
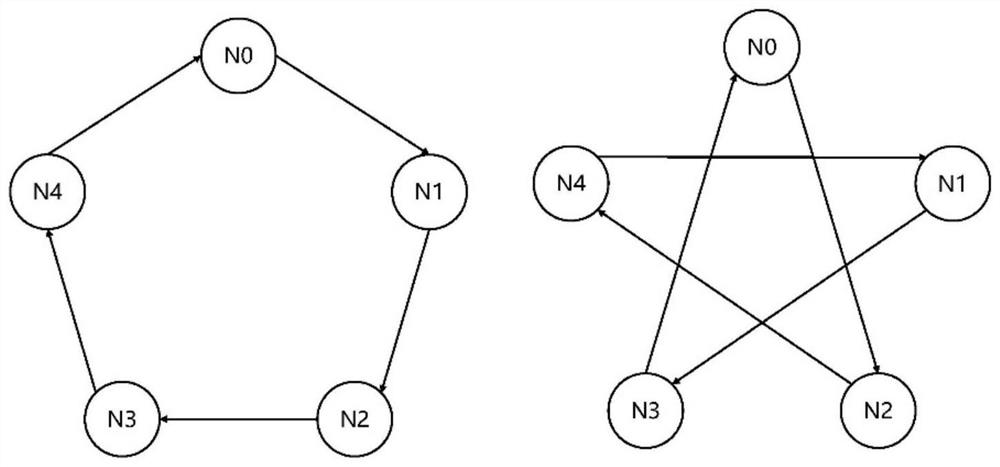
[0032] This embodiment discloses a distributed DBSCAN algorithm for large-scale computing clusters. The algorithm calculates an adjacency list through ring communication, broadcasts and synchronizes the cluster number of core points in turn, and updates the cluster number of boundary points through reverse ring communication. The mathematically equivalent distributed clustering algorithm of DBSCAN algorithm makes full use of the physical memory and communication bandwidth of the computer, and balances the workload of each computing node, so that the clustering analysis of high-latitude large-scale data sets can be completed in an effective time. .
[0033] like figure 1 As shown, the method of this embodiment specifically includes the following steps:
[0034] Step (1): Calculate the adjacency list through ring communication
[...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com