

General text OCR training data generation method and system
A technology of training data and text, applied in the field of text recognition, can solve problems such as large changes in placement angle, poor recognition effect, blurred text, etc., and achieve the effect of ingenious calculation process, fast generation speed, and simple judgment
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0016] Combine below Figure 1 to Figure 5 , the present invention is described in further detail.
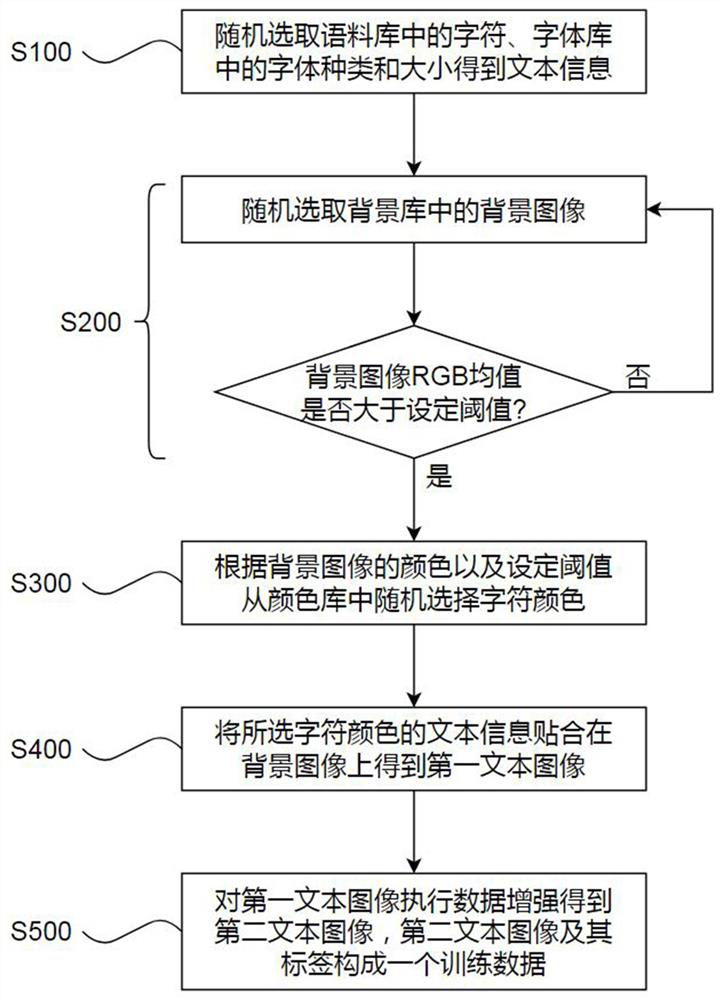
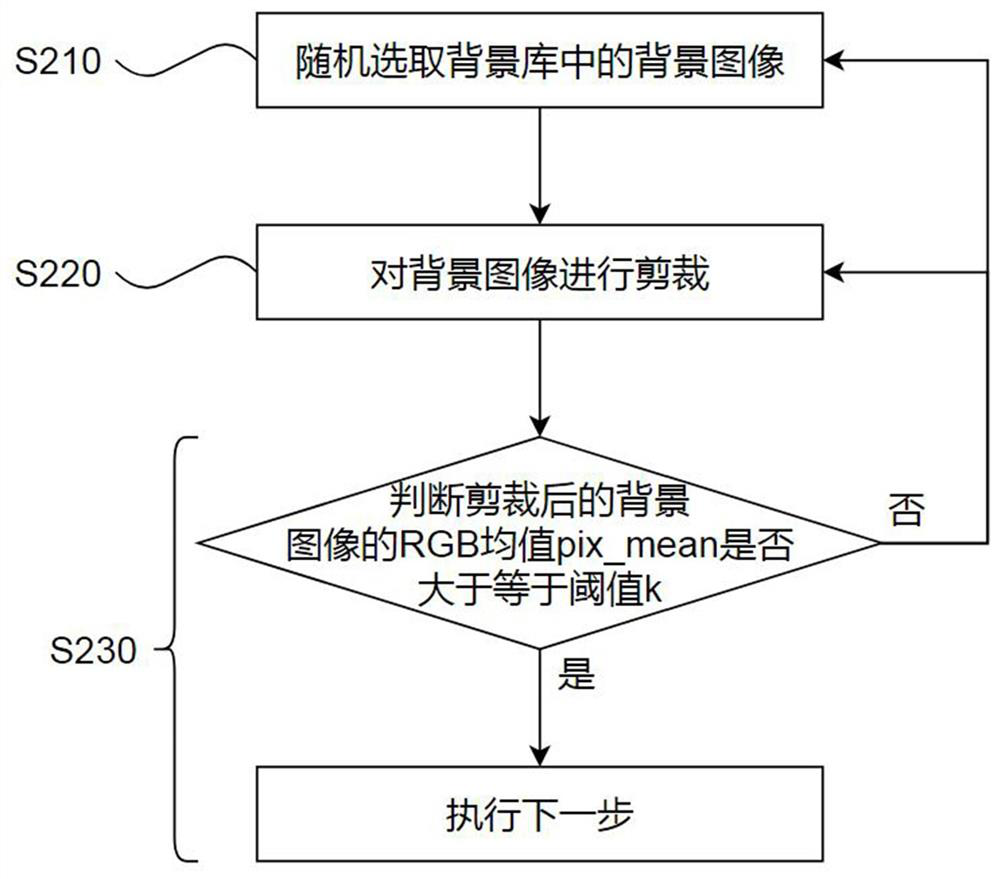
[0017] see figure 1 The invention discloses a training data generation method for general text OCR, comprising the following steps: S100, randomly selecting characters in a corpus, font types and sizes in a font library to obtain text information; S200, randomly selecting a background in a background library image, and determine whether the RGB mean pix_mean of the background image is greater than or equal to the threshold k, , if so, go to the next step, otherwise randomly select the background image again; S300, calculate the value range of the character color according to the RGB mean value pix_mean of the background image , and randomly select the character color font_color that satisfies the value range from the color library; S400, fit the text information on the background image according to the selected character color font_color to obtain the first text image, assu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More