

Method and system for extracting information from a document
a document and information technology, applied in the field of methods and systems, can solve the problems of document processing, high resource consumption, and high resource consumption of manual solutions, and achieve the effect of reducing manual processing costs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0036] As required, detailed embodiments of the present invention are disclosed herein. However, it is to be understood that the disclosed embodiments are merely exemplary of the invention that may be embodied in various and alternative forms. The figures are not necessarily to scale, and some features may be exaggerated or minimized to show details of particular components. Therefore, specific structural and functional details disclosed herein are not to be interpreted as limiting, but merely as a basis for the claims and as a representative basis for teaching one skilled in the art to variously employ the present invention.
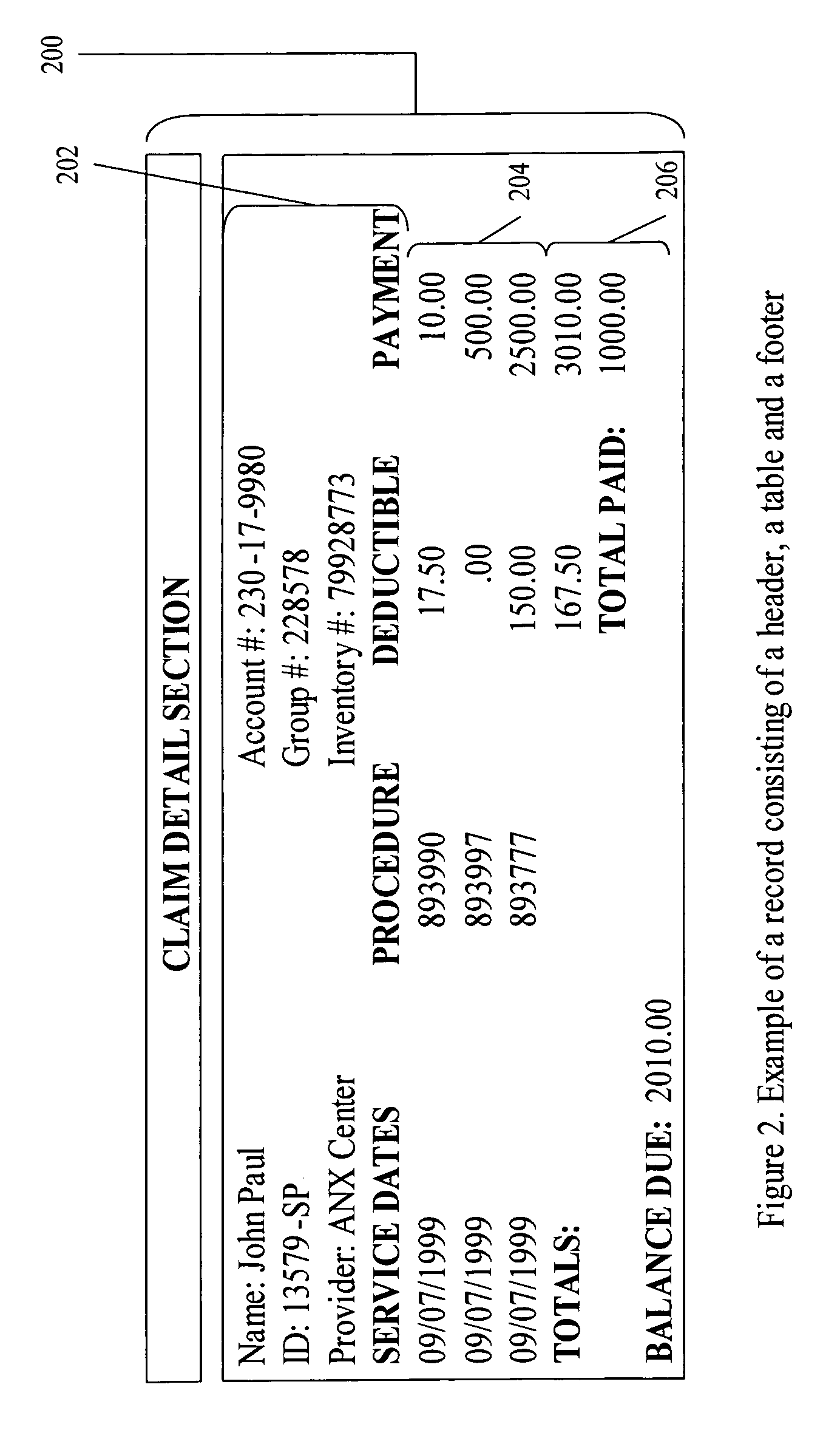
[0037] A wide variety of printed documents exhibit complex data structures including textual or numerical data organized in rows and columns, i.e., tables, along with more general structures, one of which may be broadly characterized as consisting of one or more contextually-related elements including possibly tables, i.e., records. Contextual relationship typi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More