

Synthesizing method of personalized singing voice
A synthesis method and speech technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problems of high recording difficulty, difficult control, lack of applied research, etc., and achieve the effect of improving scalability and entertainment
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
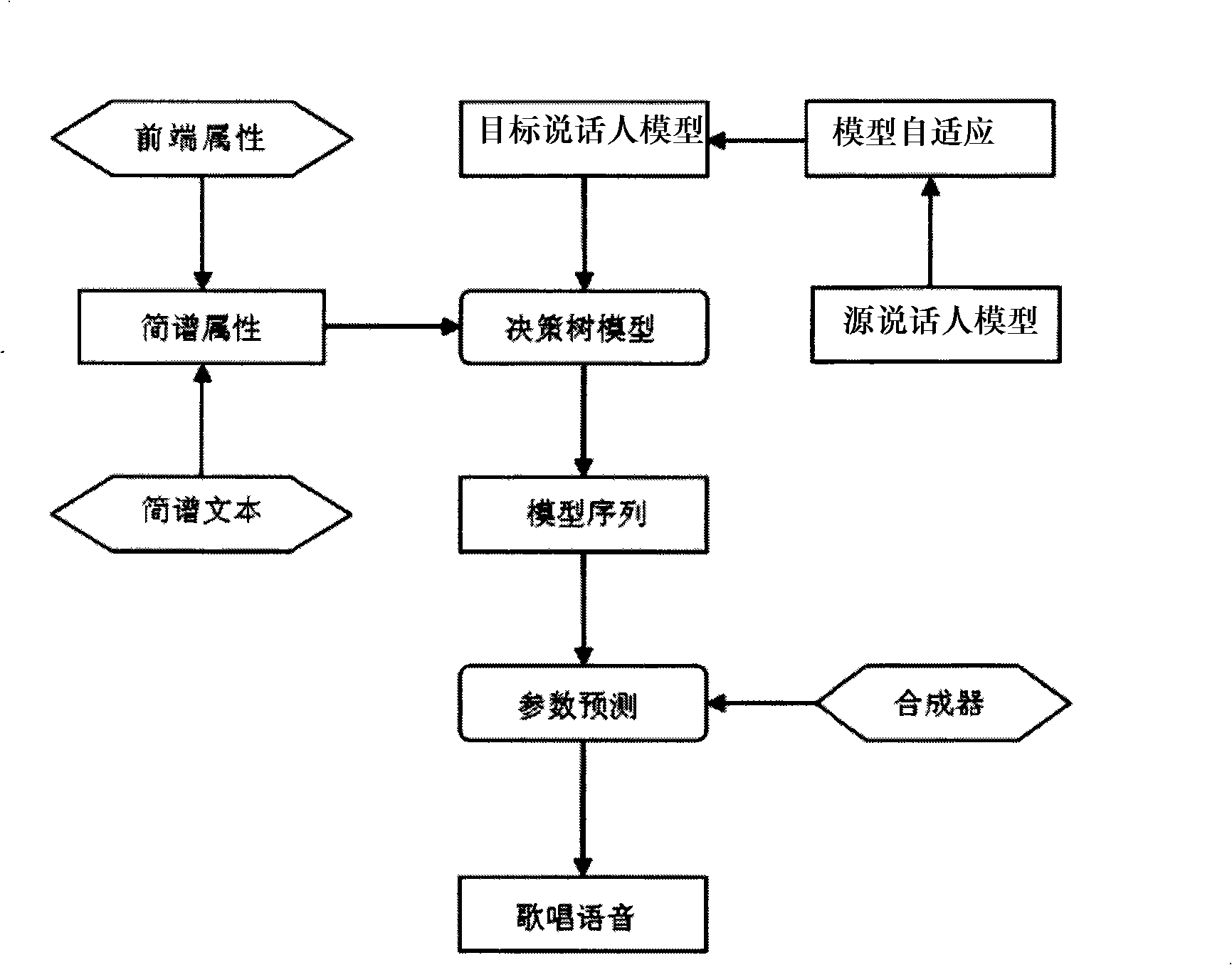
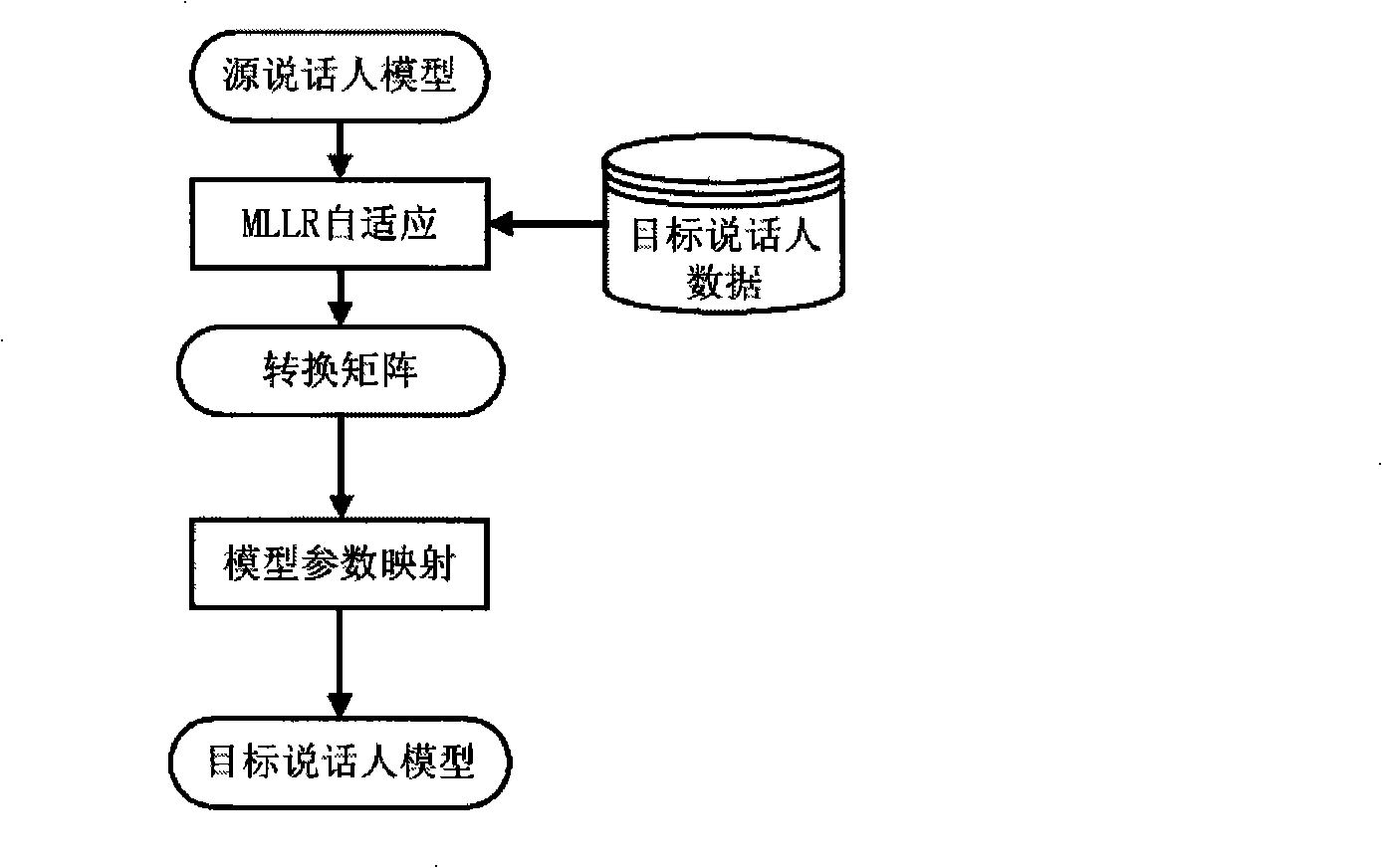
[0022] See attached figure 1 , 2 shown.
[0023] 1. Trainable speech synthesis, this invention is based on a trainable speech synthesis method. This method uses the Hidden Markov Model (HMM) to model the parameters of three aspects of the speech signal during the training phase. The parameters of these three aspects are: fundamental frequency, duration and line spectrum frequency coefficient LSF; all models are in A hidden Markov model is used to train the model on a speech library; the size of the speech library is generally about 1000 sentences (1.5~2 hours of recording volume), and the hidden Markov model with three parameters is obtained through training; while in the synthesis stage, according to the context-related attributes obtained by text analysis of the input text, according to these attributes, the clustering decision tree of the time length, fundamental frequency and spectral parameters are respectively made decisions, and the corresponding model sequence is obt...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More