

Multi-key-word matching method for rapidly analyzing content
A technology of keyword matching and content analysis, which is applied in the field of content analysis, can solve problems such as the inability to realize continuous multi-byte jumps in the text matching window, and achieve the effect of speeding up text scanning
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
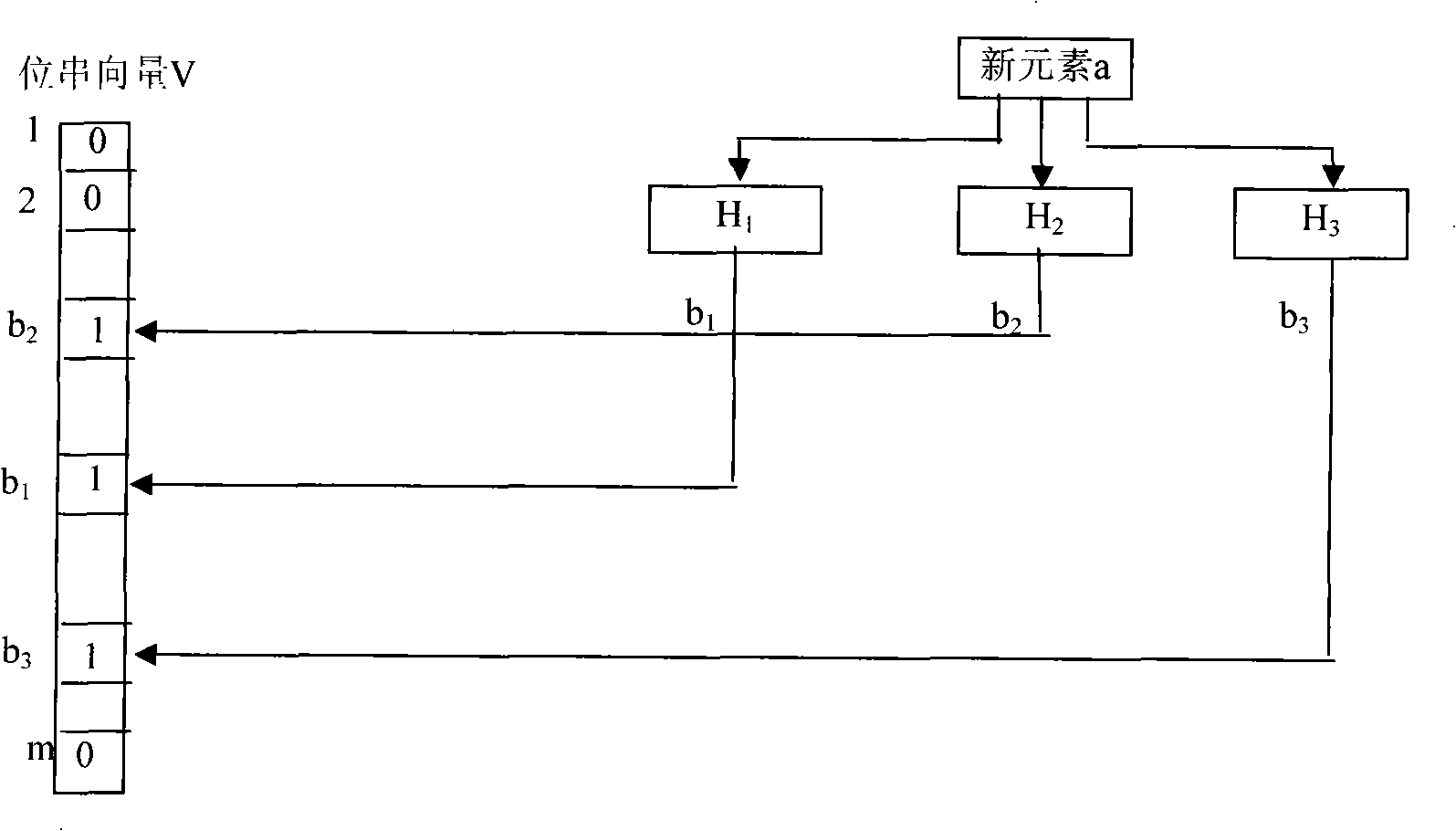
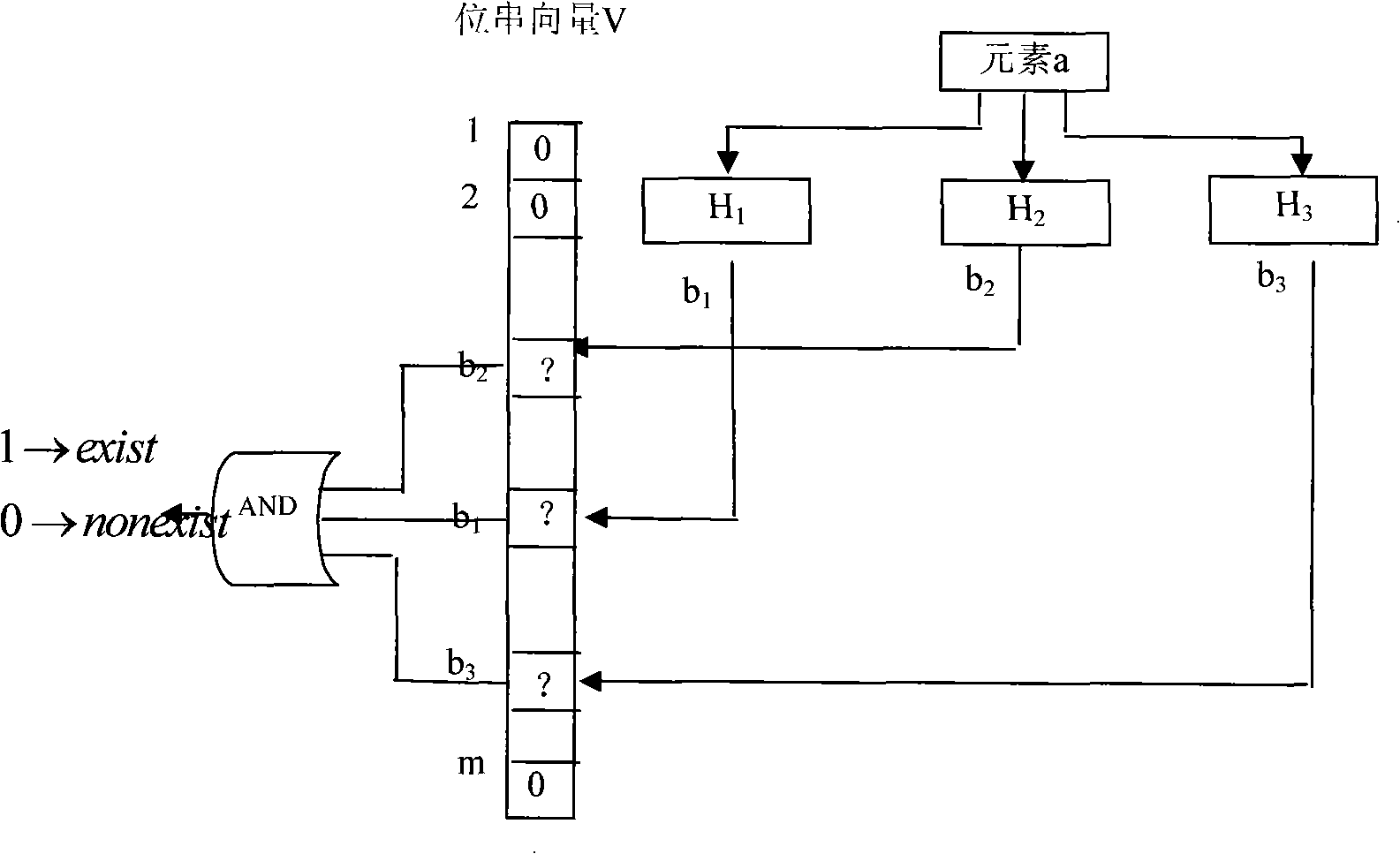
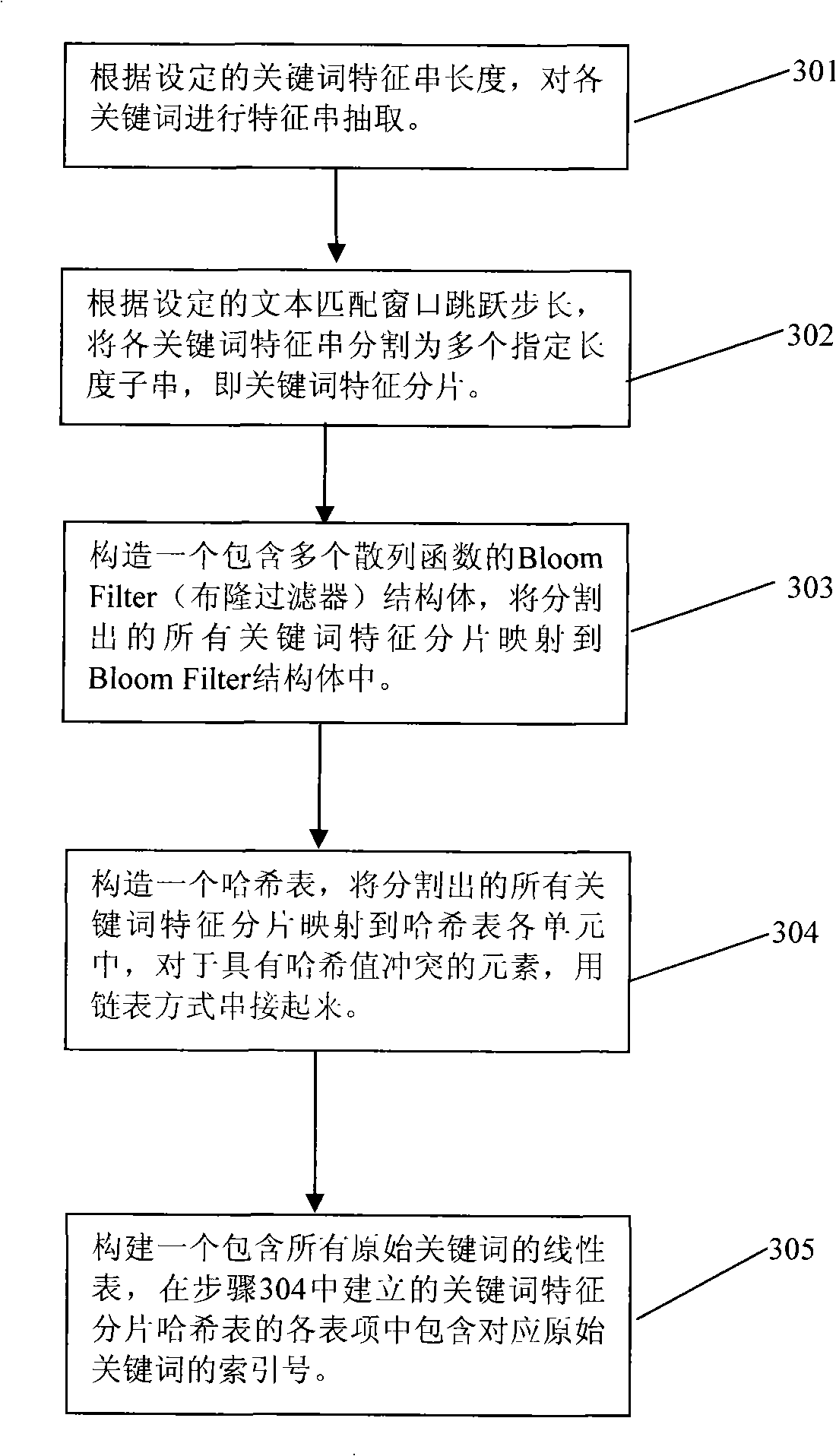
[0042] Suppose there are K original keywords to be searched, expressed as P={P 1 , P 2 ,...,P k}. In practical applications, the lengths of the original keywords to be searched are not equal. In order to facilitate the parallel matching of multiple keywords, the present invention needs to cut all keywords to equal length, that is, to select a keyword substring length value W, and for each original keyword P in the set P i , cut it into a keyword substring M of W byte length i . This cropped keyword substring M of W byte length i It is called the original keyword feature string. By extracting each keyword feature string M i The composed set is the set M of keyword feature strings. Note that when selecting the length of the keyword feature string, the value of W cannot be greater than the length of the shortest keyword in the original keyword set. The simplest clipping method is to take the W byte prefix or suffix of each keyword as the keyword feature string of the ori...
Embodiment approach
[0061] When implementing the present invention, the step A1 of the preprocessing stage A described in the present invention can adopt the following preferred implementation mode: for keyword set P={P 1 , P 2 ,...,P k} in each keyword P i , the extracted keyword feature string M i is the keyword substring with the least number of occurrences in the entire keyword set.
[0062] The following method can be used to make the extracted keyword feature string M i is the keyword substring with the least number of occurrences in the entire keyword set:
[0063] a) Establish a hash table for storing all possible keyword substrings with a length of W;
[0064] b) for any length n i The original keyword P i , can be divided into (n i-W) keyword substrings with a length of W, for each segmented keyword substring, first determine whether it is in the keyword substring hash table: if not in the hash table, create a new key Word substring entry, and the counter value is set to 1; if ...
Embodiment 2
[0071] The entire technical solution of the present invention will be further described below through an embodiment.
[0072] Suppose the keyword set is P={abcdefg, abcopq, wyzopq}, and the text to be matched is bcgilmnom.
[0073] According to the pretreatment process of the inventive method as follows:
[0074] First, the length of the keyword feature string is determined and the keyword feature string corresponding to each keyword is cut out. Here, the keyword length is selected to be 3 bytes, and the characteristic strings of each keyword are selected according to the principle of least occurrence of keyword substrings, and finally the set of keyword characteristic strings is M={bcd, cop, wyz}.
[0075] Then, set the jumping step of the text matching window and determine the set of keyword feature slices. Here, the skipping step of the text matching window is selected as 2 bytes, so the corresponding keyword feature fragment set K={bc, cd, co, op, wy, yz} can be obtained...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More