

Cluster implementation method and system
An implementation method and clustering technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of low processing efficiency and the inability to achieve clustering processing of massive data, so as to speed up the calculation speed and solve the problem of clustering. The effect of low processing and processing efficiency and shortening of waiting time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0037] The clustering implementation method and system provided by the embodiments of the present invention will be described in detail below with reference to the accompanying drawings.
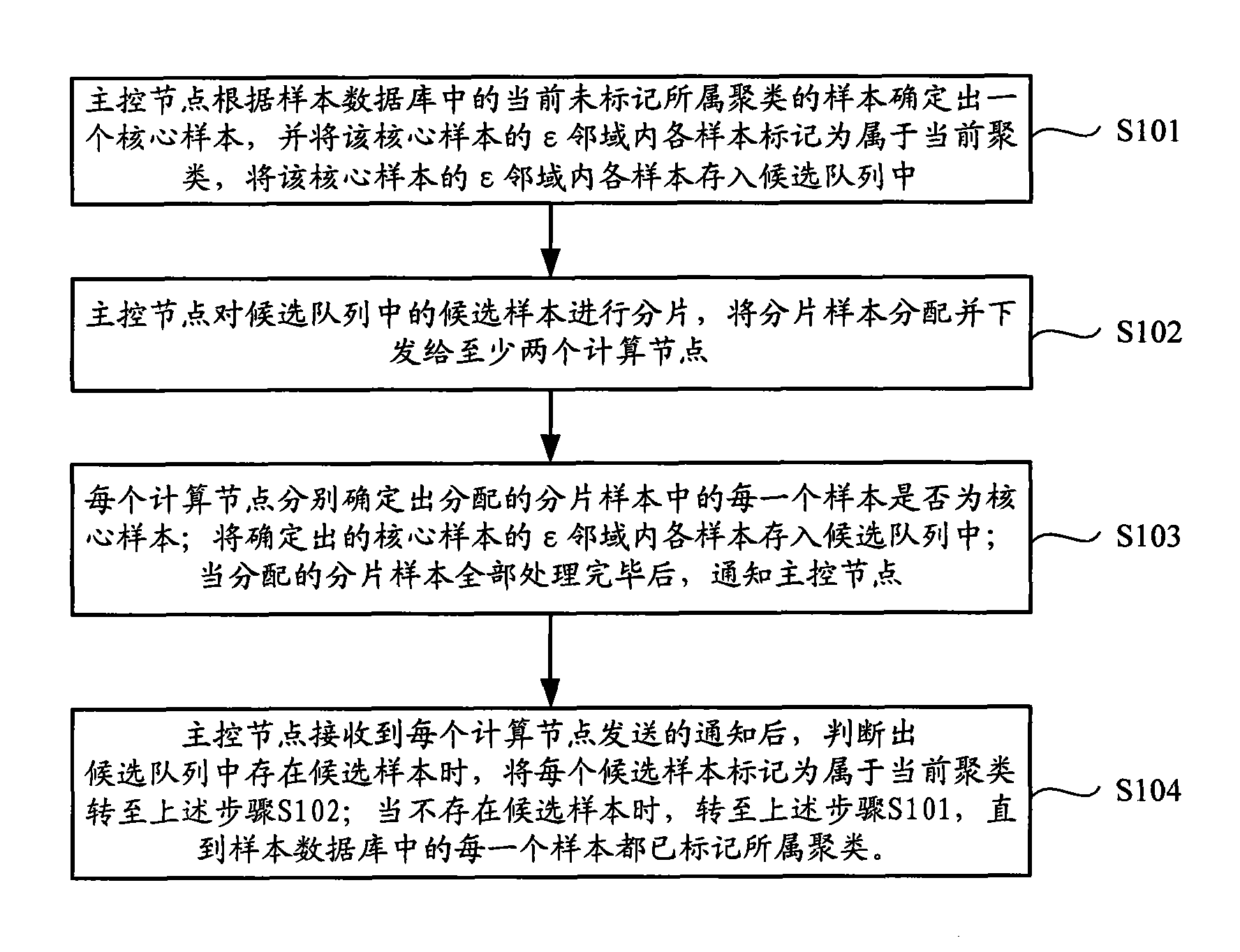
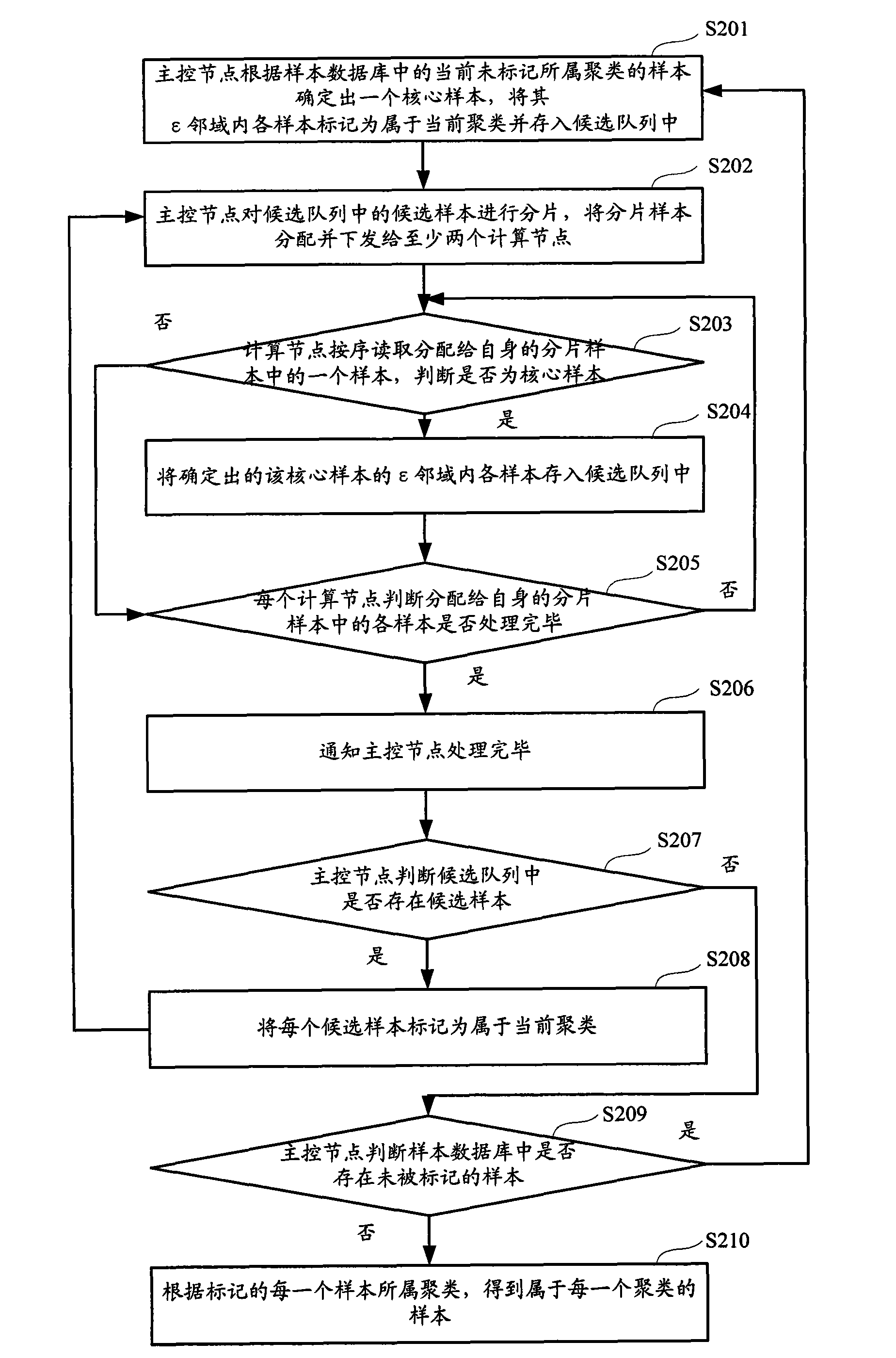
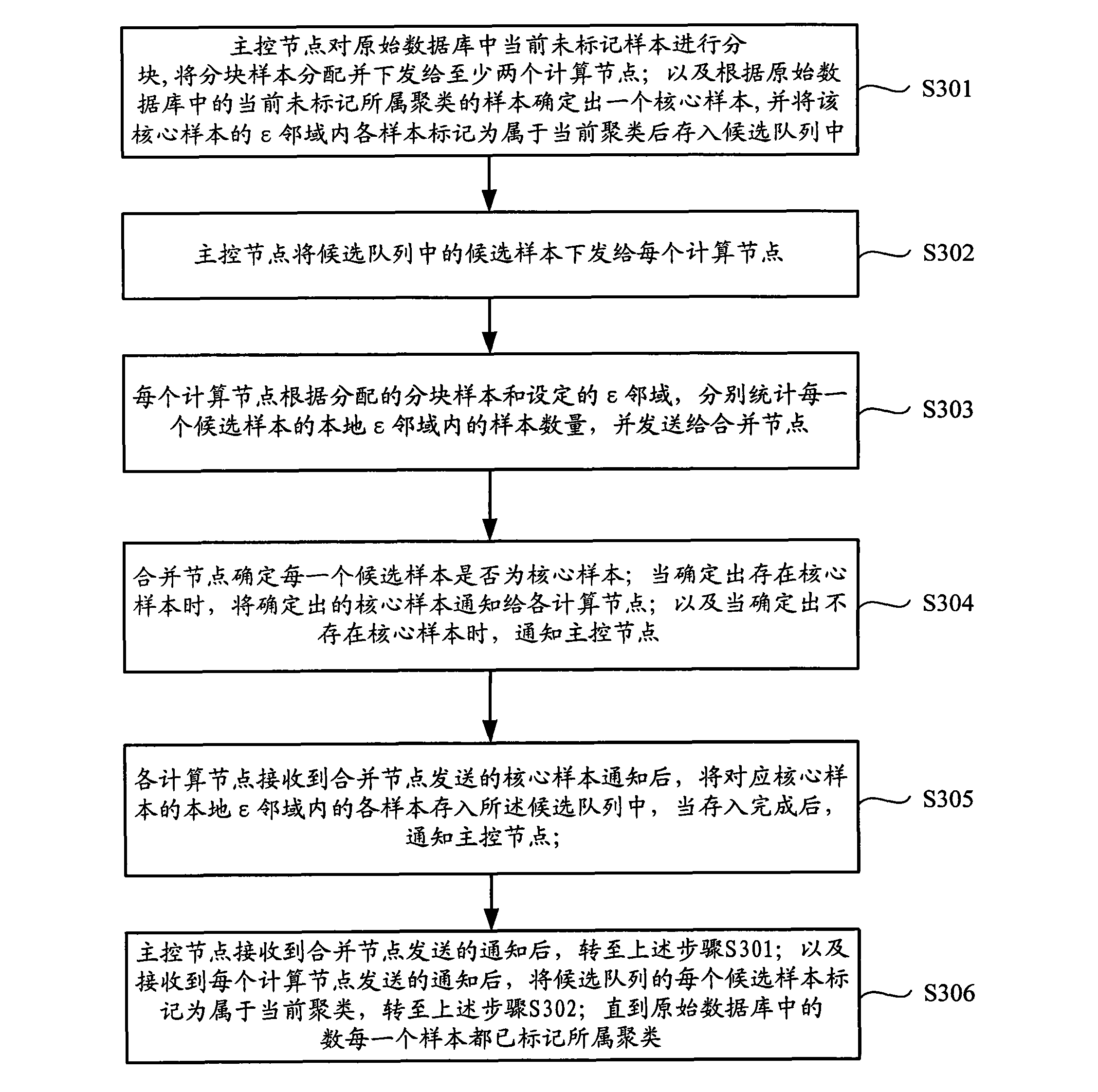
[0038] see figure 1 , is a flow chart of a clustering implementation method provided by an embodiment of the present invention, including the following steps:
[0039]Step S101, the master control node determines a core sample according to the samples in the sample database that are currently unmarked to belong to the cluster, and marks each sample in the ε neighborhood of the core sample as belonging to the current cluster, and the ε neighbor of the core sample Each sample in the domain is stored in the candidate queue.
[0040] Step S102, the master control node fragments the candidate samples in the candidate queue, distributes and issues the fragmented samples to at least two computing nodes.
[0041] Step S103, each calculation node respectively determines whether each sample in the a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More