

Mass non-independent small file associated storage method based on Hadoop
A technology of associative storage and small files, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of large-scale non-independent small file storage and low reading efficiency, so as to reduce load and improve storage efficiency , reducing the effect of interaction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0051] The present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments.
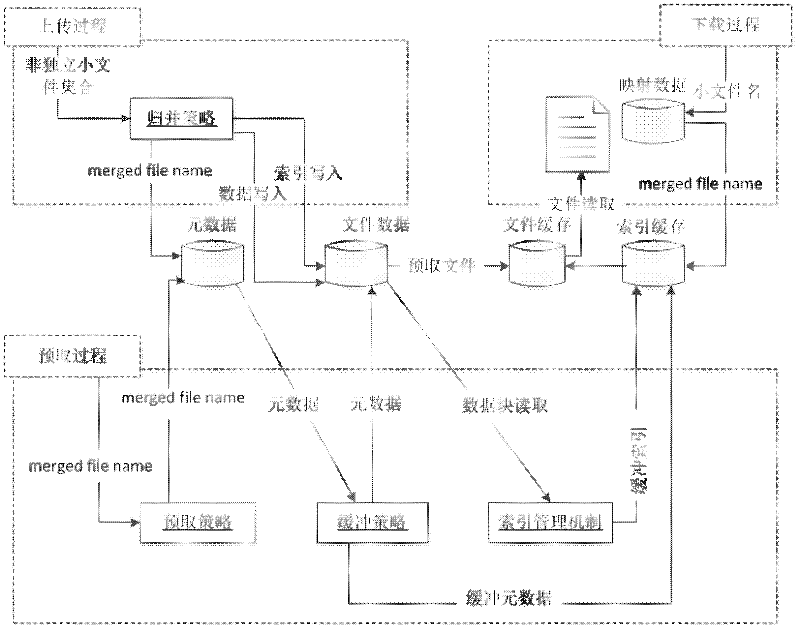
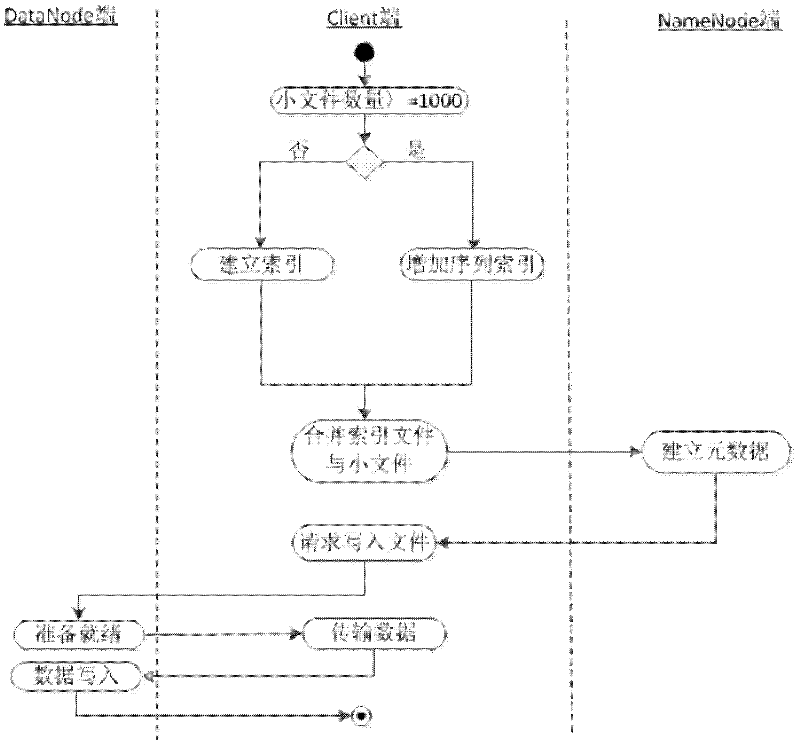
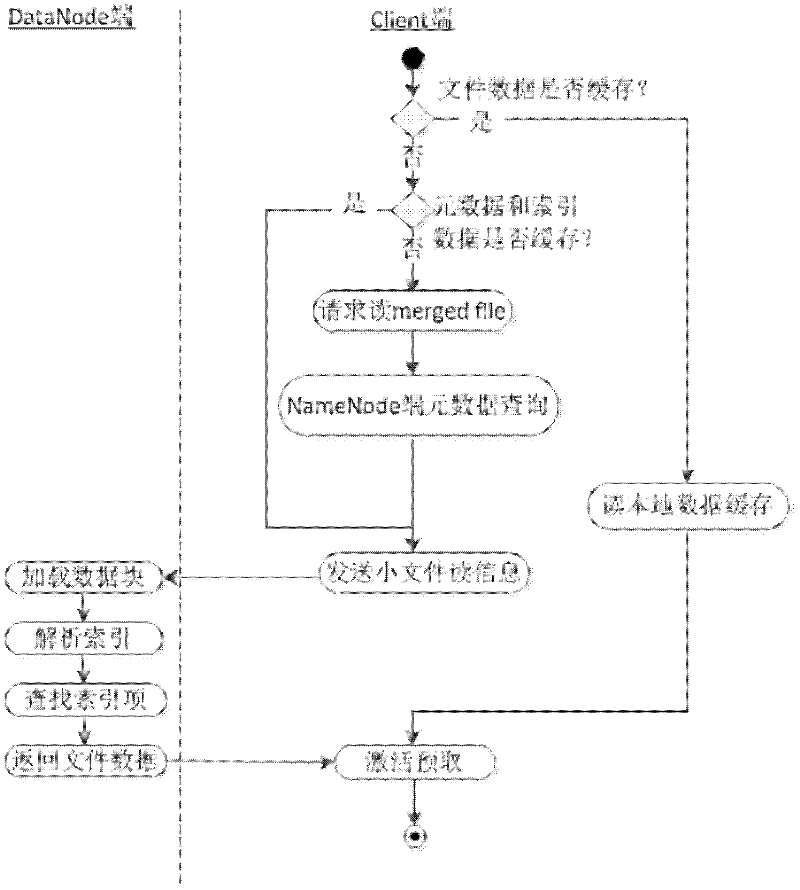
[0052] Based on Hadoop's massive non-independent small file associative storage method, some large files are first divided into many small files for storage and reading. These small files are part of the large file, called non-independent small files, which belong to a certain All non-independent small files of a large file are merged into one file, called a merged file; then a local index is established for each merged file, and the local index file is stored together with the file entity on the DataNode of the Hadoop file system when uploading ; Then, when reading non-independent small files, use metadata cache, local index file prefetching and associated file prefetching to improve file reading efficiency.
[0053] DataNode side local index management technology is to create a local index file for each merged file, record the starting posit...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More