

Data redundancy and file operation methods based on Hadoop distributed file system (HDFS)
A distributed file and data redundancy technology, applied in the field of file system storage and management, can solve the problems of file reading and file writing efficiency and performance loss, waste of system resources, etc. The effect of reducing the failure rate and shortening the time spent
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0049] The invention will be described in further detail below in conjunction with the accompanying drawings.
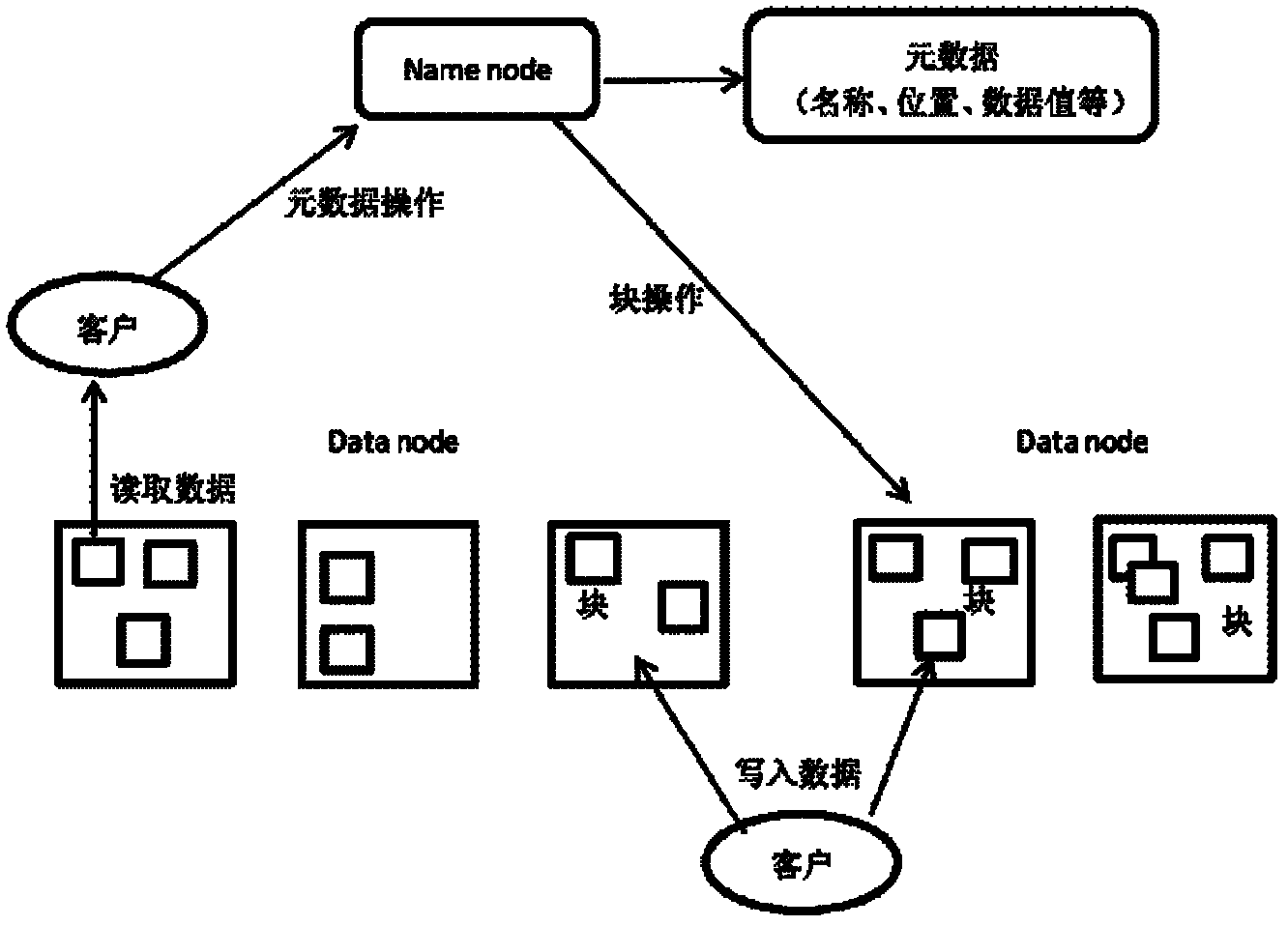
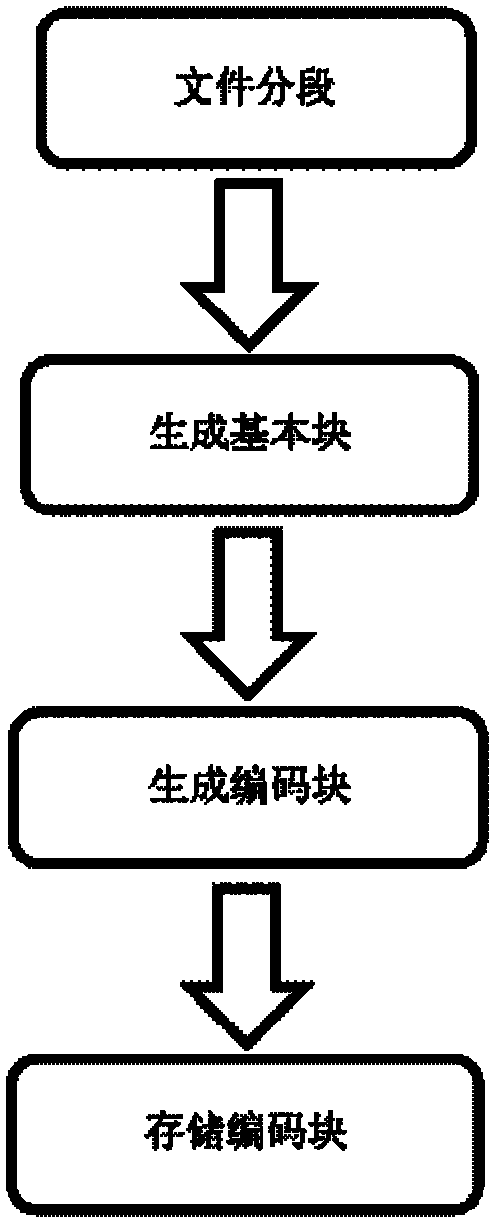
[0050] refer to figure 2 , the specific steps of data redundancy in the present invention are as follows:
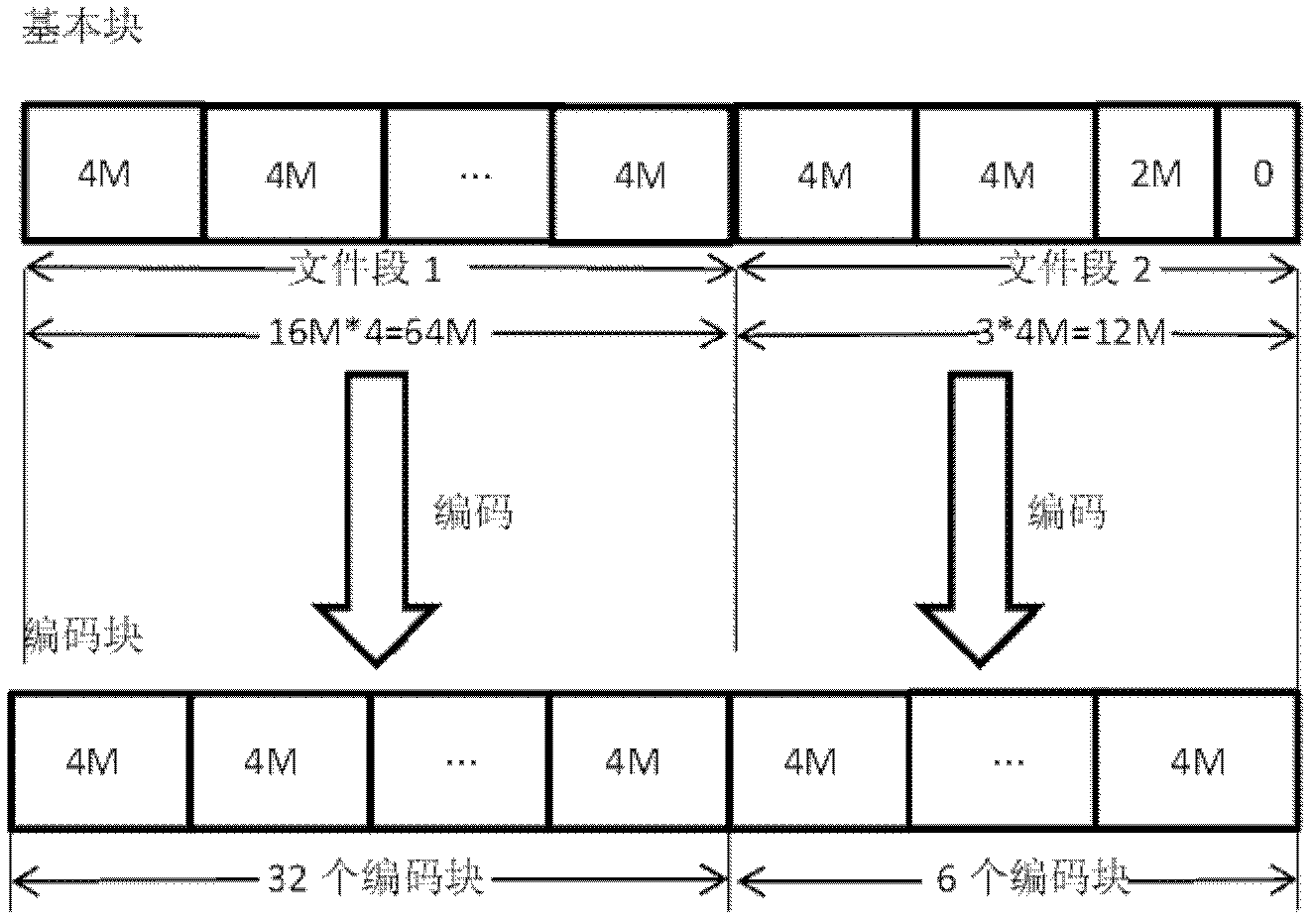
[0051] Step 1: Segment the file. The size of the file segment is based on the number of basic blocks. By default, each file segment consists of 16 basic blocks, and the size of each basic block is 4MB. Therefore, the data length of each file segment It is 64MB, if the end of the file segment data less than 64MB is filled with 0. For the case of non-fixed-length file segments, such as image 3 , the file length is 74MB, and it can only be divided into two file segments. File segment 1 is divided into 16 basic blocks of 4MB, and file segment 2 is divided into three basic blocks of 4MB. The files in the first two basic blocks come from the file, and the latter Only 2MB of data in a basic block comes from the original file, and the following data is filled with...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More