Trojan horse scanning method and system
A scanning method and scanning system technology, applied in the direction of platform integrity maintenance, etc., can solve problems such as unusable implementation methods and lack of flexibility, and achieve the effects of avoiding excessive storage data, increasing scanning speed, and ensuring security
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
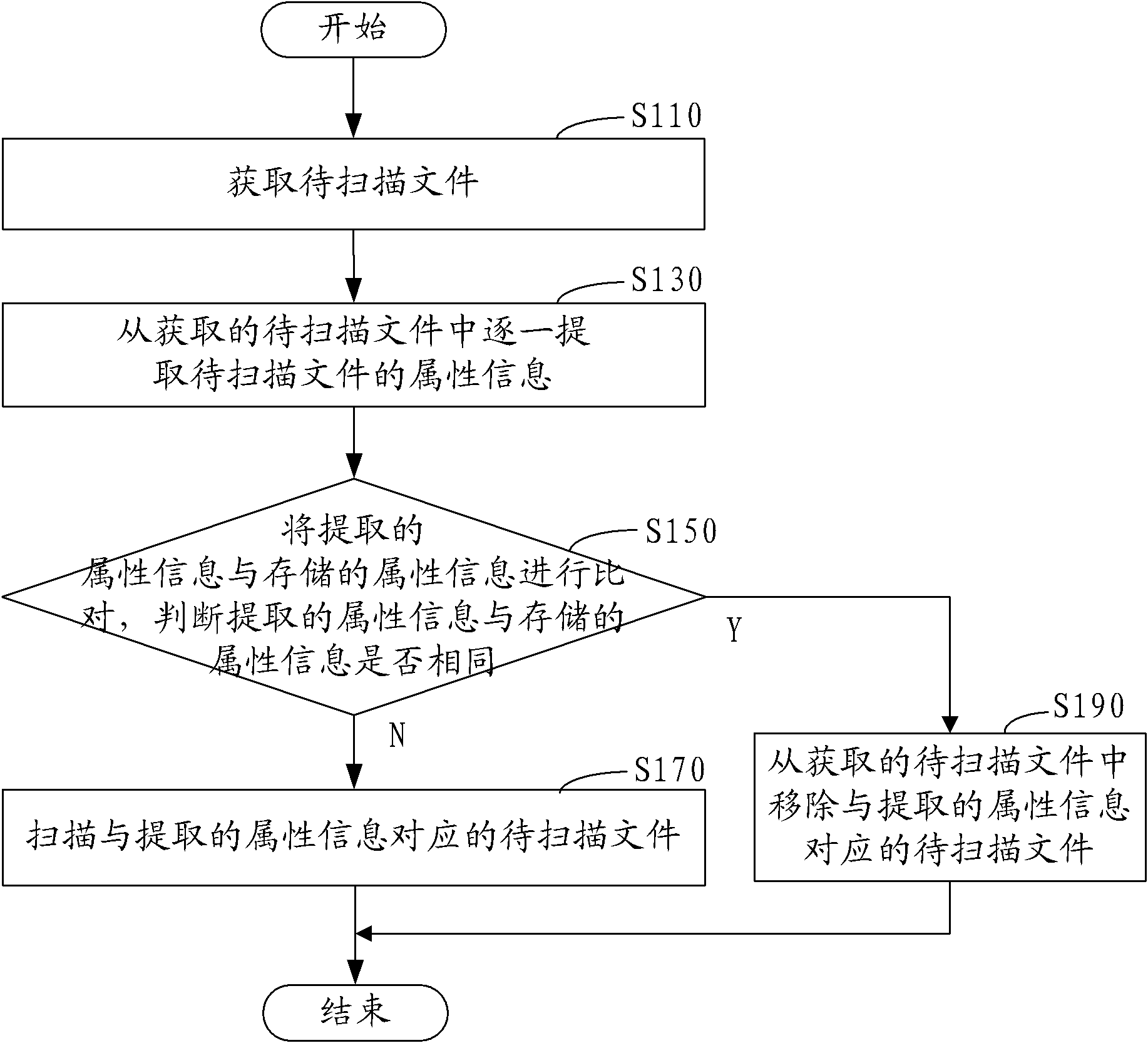
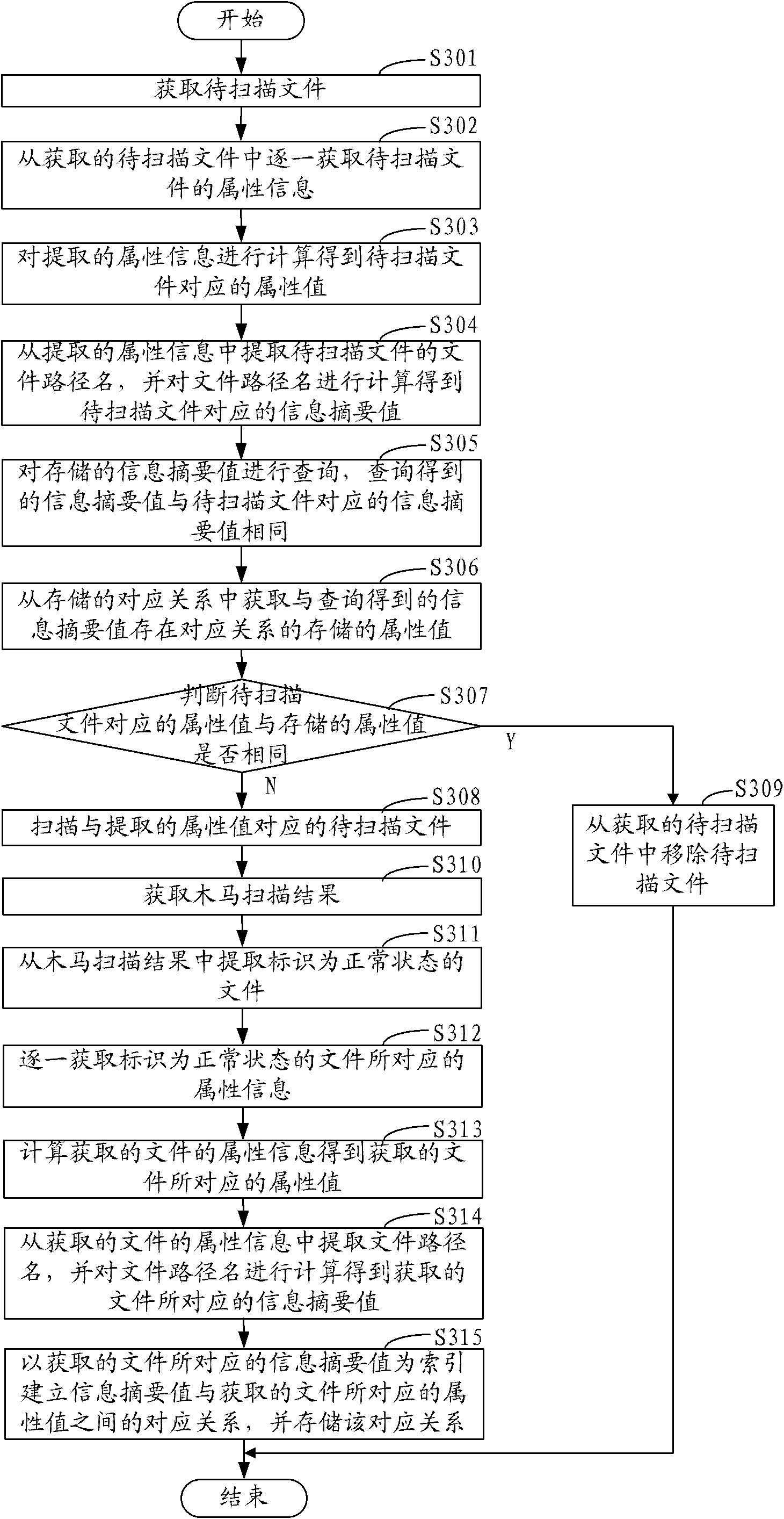
[0067] figure 1 The method flow of file scanning in an embodiment is shown, including the following steps:
[0068] Step S110, obtaining the file to be scanned.
[0069] In this embodiment, after the scanning engine of the virus scanning and killing software or Trojan horse scanning and killing software is turned on, the files to be scanned are obtained according to the user's operation of selecting the scanning range of files on the scanning and killing interface, and these files are used as files to be scanned. In the process of obtaining the files to be scanned, in order to make the file scanning easy to maintain during the running process, multiple files to be scanned are enumerated according to the set queue length according to the operation of the user to select the scanning range of the file to form an enumeration of a specific length. Raise the queue to wait for scanning.
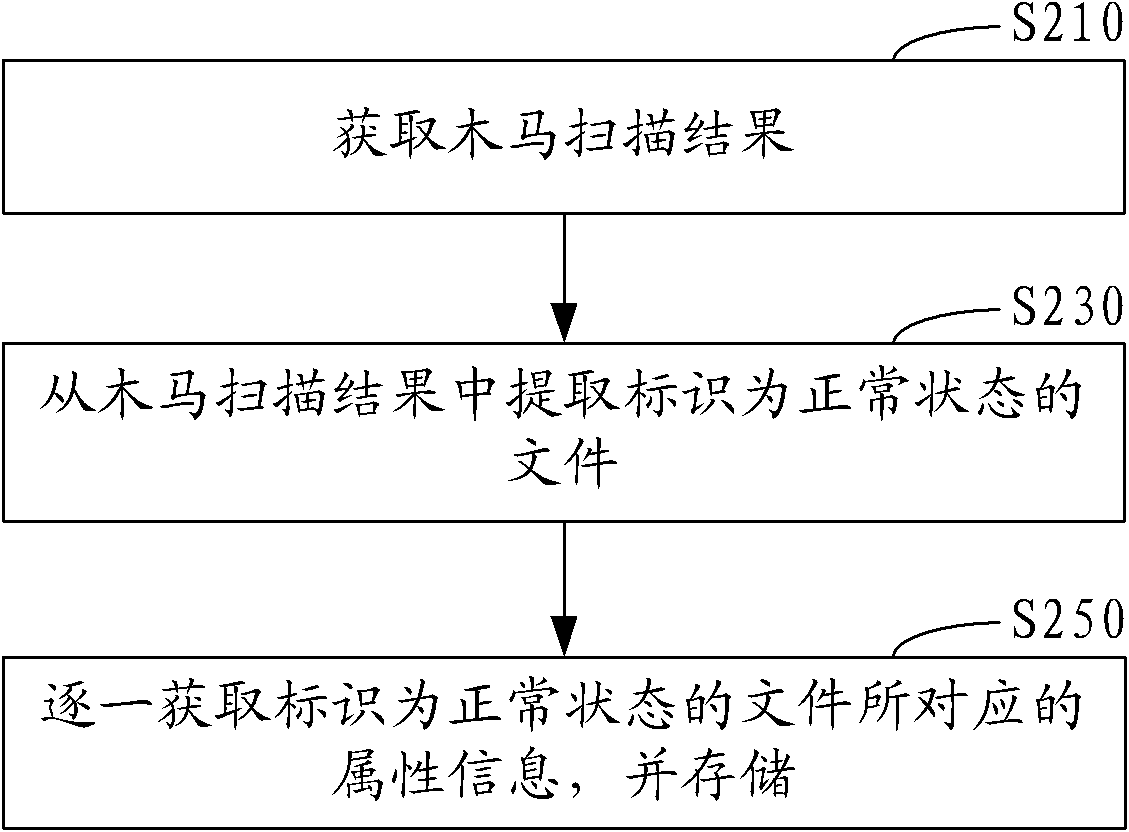
[0070] Step S130, extracting attribute information of the files to be scanned from the acquire...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More