

GMM clustering method for high-dimensional massive data under hadoop framework
A massive data and clustering method technology, applied in the computer field, can solve the problems of low scalability and scalability, not solving the dimensional disaster of large-scale data processing, and unable to effectively deal with massive data, etc., to solve the problem of I/O Bottleneck, the effect of clustering efficiency improvement
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

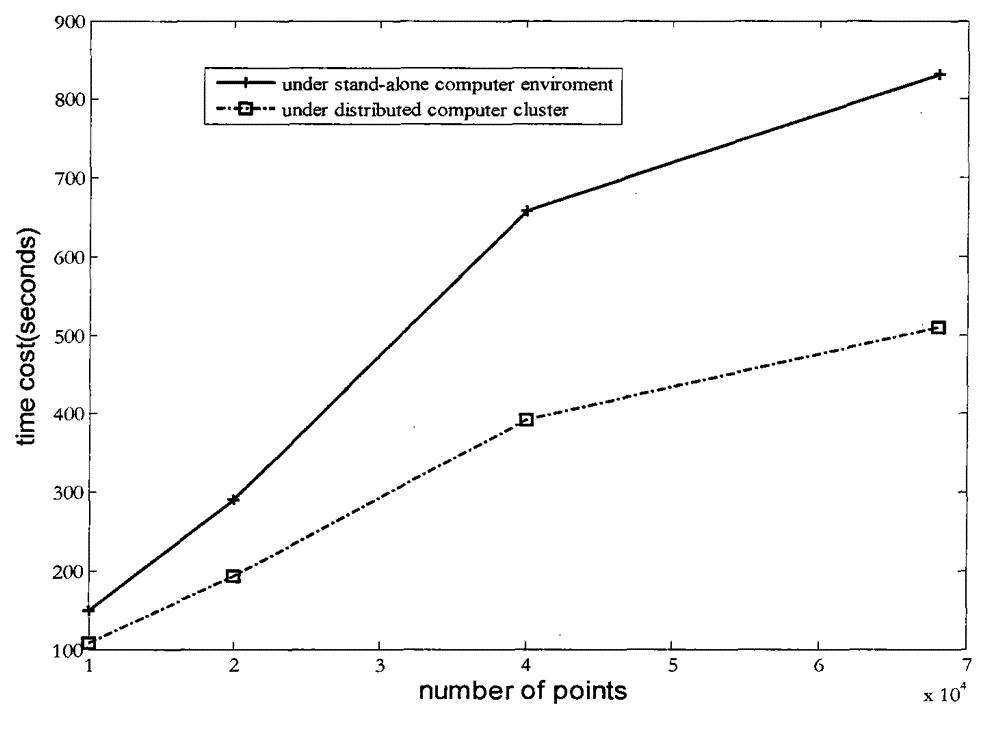
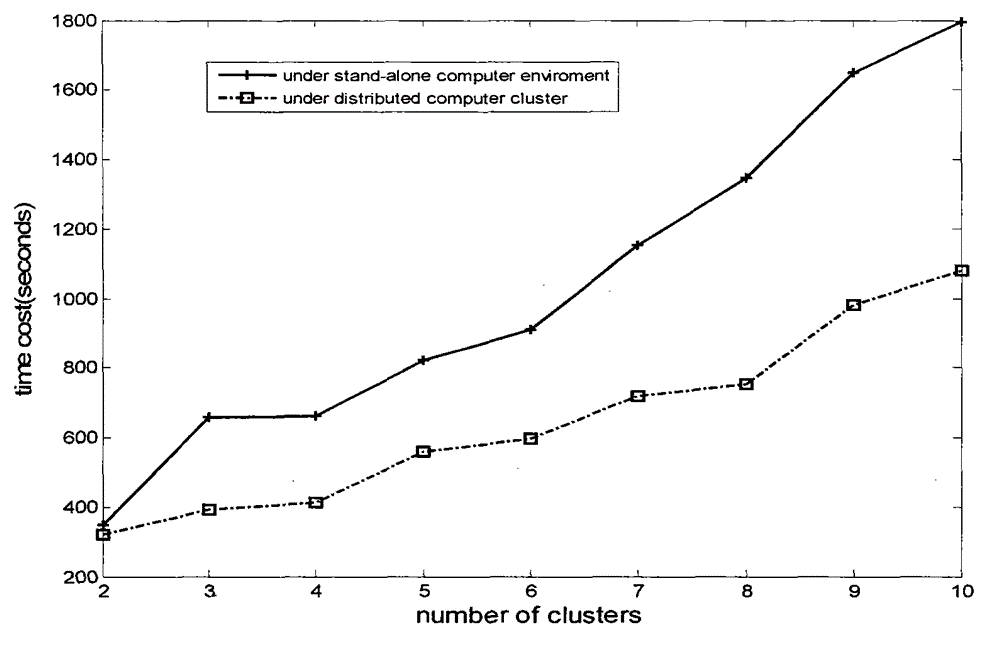
Examples
Embodiment Construction
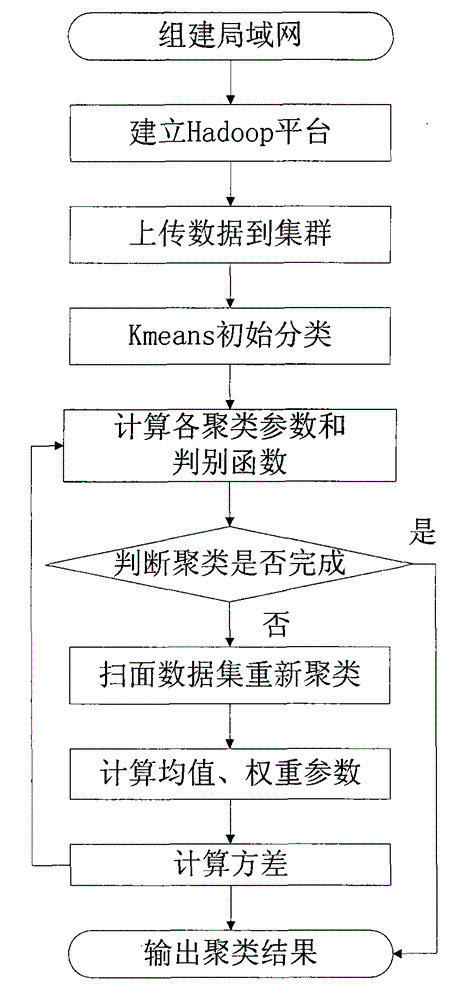
[0053] The present invention will be further described below in conjunction with the accompanying drawings.
[0054] refer to figure 1 , the present invention comprises the following steps:
[0055] Step 1, set up a local area network
[0056] Connect multiple computers to the same LAN, and each computer acts as a node to establish a cluster that can communicate with each other.
[0057] Step 2, build Hadoop platform
[0058] Configure the Hadoop0.20.2 file for each node in the cluster. Through the settings of the attribute parameters dfs.namenode and dfs.datanode in the file, the cluster contains a name node and multiple data nodes; through the attribute parameters mapred.jobtracker and The setting of mapred.tasktracker enables the cluster to include a scheduling node and multiple task nodes, and establishes an open source Hadoop platform.
[0059] The specific steps to establish the Hadoop platform are as follows: first, install the ubuntu10.04 operating system for each ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More