

Method and system for accurately extracting webpage content
A web page content and precise extraction technology, applied in the Internet field, can solve the problems of time-consuming adjustment, difficult maintenance, and difficult system maintenance, etc., and achieve the effect of reducing maintenance costs and improving development efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
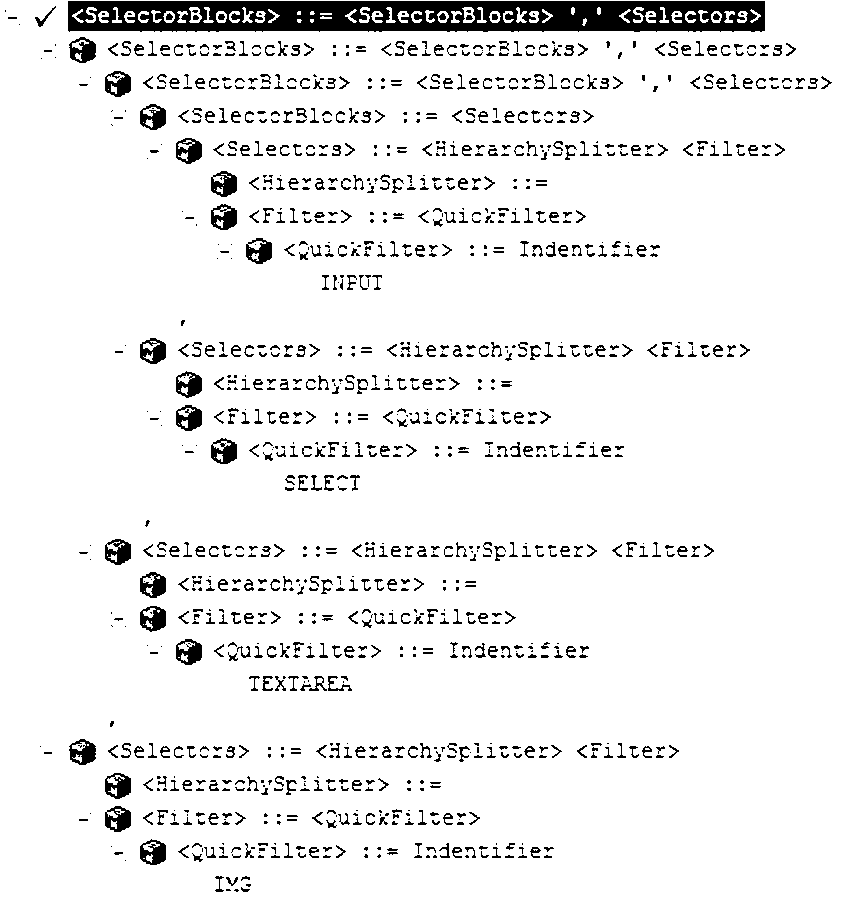
[0068] When the user input command is "INPUT, SELECT, TEXTAREA, IMG", it means to find all INPUT, SELECT, TEXTAREA, IMG tags in the page.
[0069] Through lexical analysis, the system will form such image 3 The complete, unoptimized expression tree is shown.
[0070] while in syntax table The block is defined as follows:
[0071] ::= ','
[0072] |
[0073] its meaning means one or more Composed of commas "," between separated.
[0074] Before optimization, the nodes presented in the syntax tree are nested, which can be expressed as follows:
[0075] INPUT,SELECT,TEXTAREA,IMG=(INPUT,SELECT,TEXTAREA)+(IMG)
[0076] INPUT, SELECT, TEXTAREA = (INPUT, SELECT) + (TEXTAREA)
[0077] INPUT,SELECT=(INPUT)+(SELECT)
[0078] SELECT=(SELECT)
[0079] The above format is not conducive to grammatical analysis, and the nodes need to be optimized into the following optimized expression tree that is conducive to grammatical analysis:
[0080] INPUT,SE...
Embodiment 2
[0097] When the user enters the expression "DIV.a>IMG.b[alt]", the meaning is to first find the DIV tag with the style name a in the page, and then filter out the child elements with the style name b, and Contains the IMG tag with the alt attribute.
[0098] Through lexical analysis, the system will construct as Figure 5 The complete, unoptimized expression tree is shown.
[0099] in the grammar table The block is defined as follows:
[0100] ::=
[0101] |
[0102] ::='>'|'+'|'~'|
[0103] its meaning means is composed of one or more It consists of three layers separated by layer separators, which are ">", "+", and "~". When parsing the jQuery syntax, another separator is one or more blank characters. In this case, it is necessary to judge whether the node contains blank characters, and keep them if they exist, otherwise they will be removed.
[0104] For the above nodes can be optimized as Image 6 As shown in the schematic diagram, the op...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More