

Method and device for updating data in distributed storage system
A distributed storage and data update technology, applied in the field of distributed systems, can solve problems such as inability to guarantee data consistency of multiple copies, increase overhead, etc., to achieve the effect of solving data consistency, improving efficiency, and ensuring reading performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
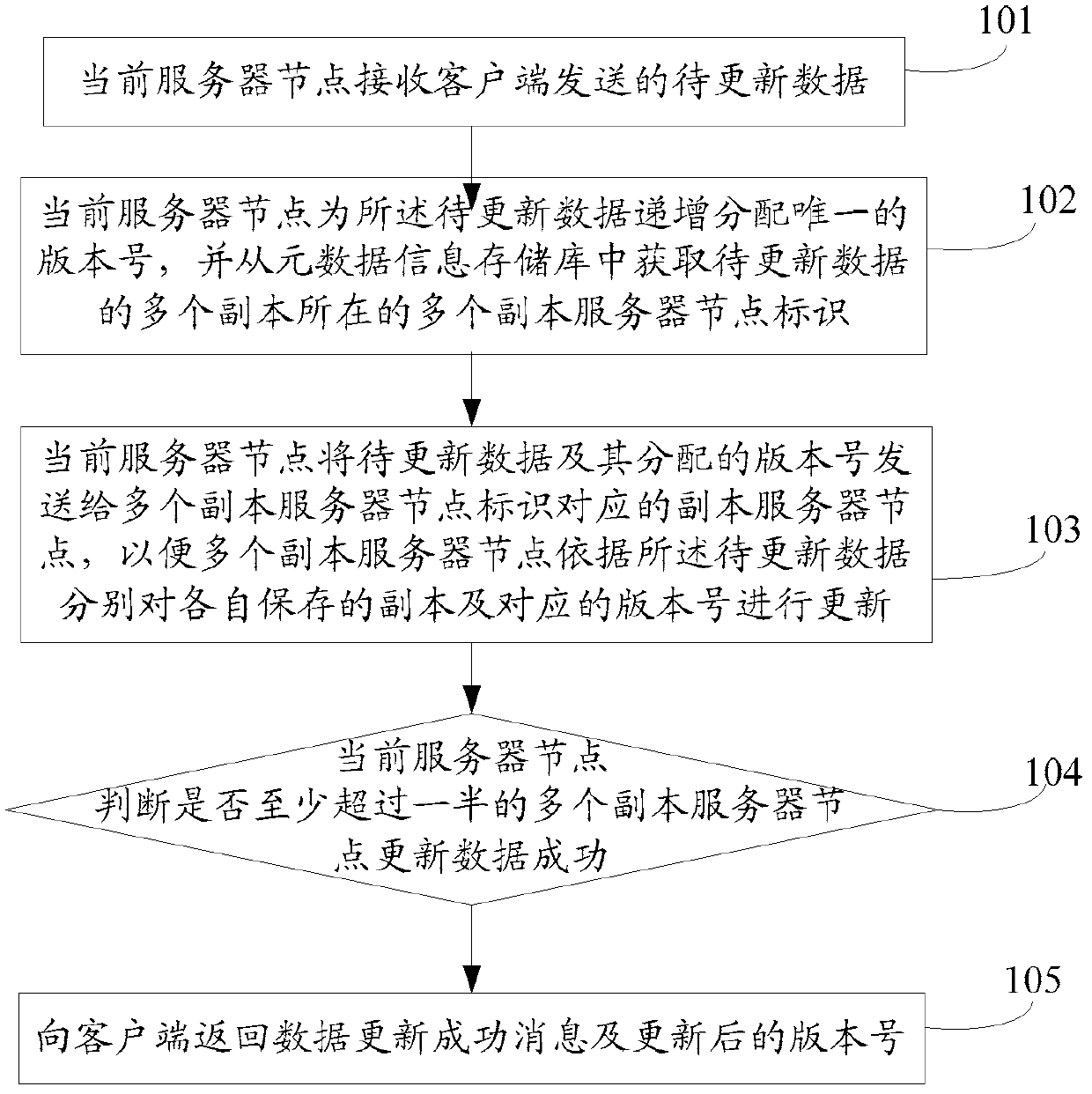
[0051] see figure 1 as shown, figure 1 It is a flow chart of Embodiment 1 of the data update method in the distributed storage system disclosed in the embodiment of the present invention. In this embodiment, the method may include:
[0052] Step 101: the current server node receives the data to be updated sent by the client.
[0053]The client first sends the data to be updated to a server node in the distributed storage system. For example, user information is stored on each server node in the distributed storage system, and if the user information needs to be changed, the client Send new user information to one of the server nodes, that is, the data to be updated, and the server node that receives the new user information is the current server node.
[0054] Step 102: The current server node incrementally assigns a unique version number to the data to be updated, and obtains identifiers of multiple replica server nodes where multiple replicas of the data to be updated are ...
Embodiment 2
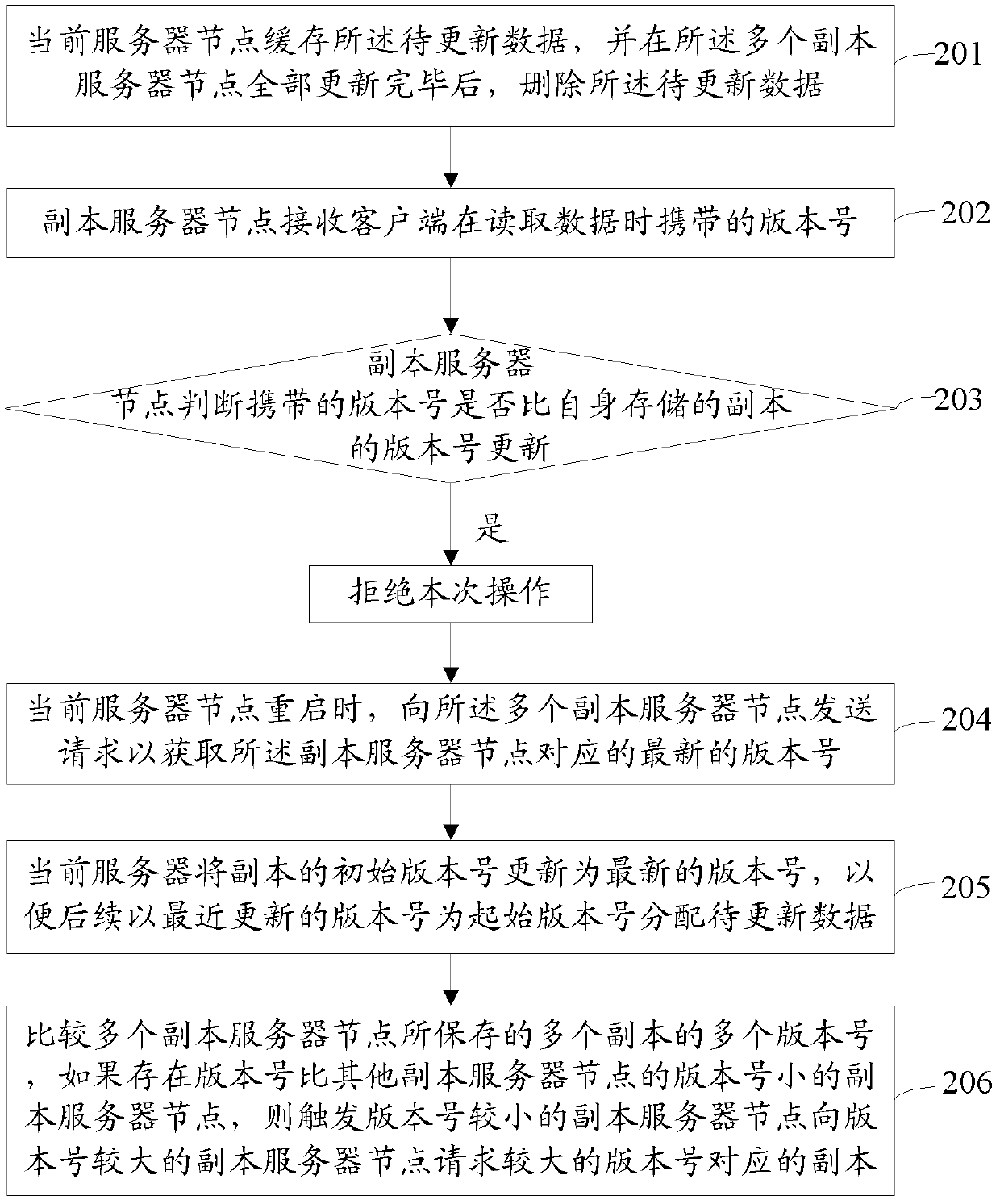
[0067] refer to figure 2 as shown, figure 2 It is the flow chart of Embodiment 2 of the data update method in the distributed storage system disclosed in the embodiment of the present invention. In addition to steps 101-104 in Embodiment 1, after step 104, the method may further include:
[0068] Step 201: The current server node caches the data to be updated, and deletes the data to be updated after all the replica server nodes are updated.
[0069] The current server node first caches the data to be updated, and when the data is successfully updated on all replica server nodes, it can be deleted. In addition, when the current server node has insufficient space, it can also be deleted, so that it can take up less space The storage space of the current server node.
[0070] It should be noted that, in the embodiment of the present invention, the latest updated data can be additionally cached on at least one replica node, that is, on a certain replica server node, not only ...
Embodiment 3
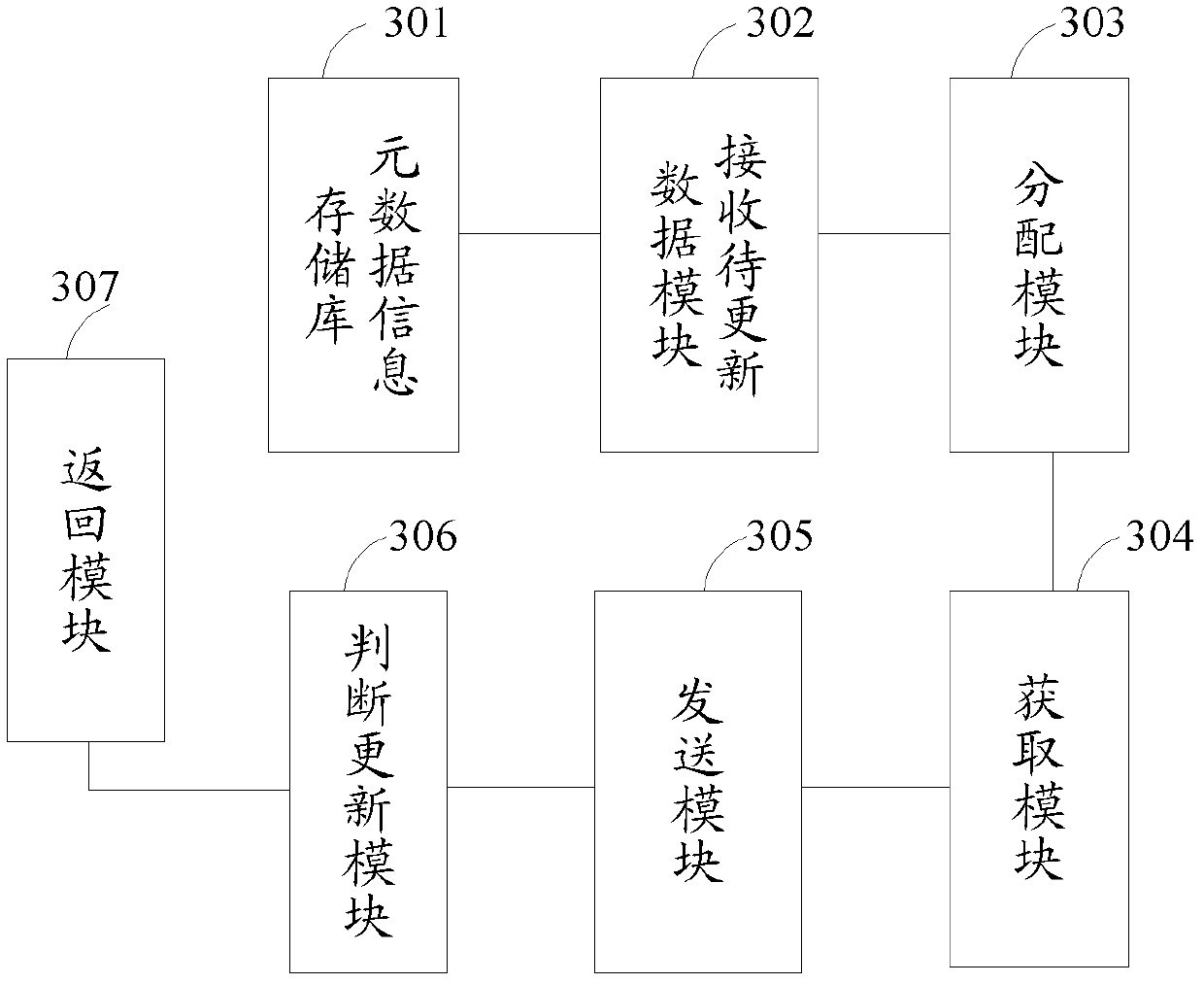
[0085] see image 3 as shown, image 3 It is a schematic structural diagram of Embodiment 1 of the data update device in the distributed storage system disclosed in the embodiment of the present invention. In this embodiment, the device may include:
[0086] The metadata information repository 301 is used to store the identification of each server node in the distributed storage system, the distribution information of the copy in the server node and the status of the copy;
[0087] Receive data to be updated module 302, for receiving the data to be updated sent by the client;
[0088] An allocation module 303, configured to incrementally allocate a unique version number for the data to be updated;
[0089] An obtaining module 304, configured to obtain, from the metadata information repository, identifiers of multiple replica server nodes where multiple replicas of the data to be updated are located;
[0090] The sending module 305 is configured to send the data to be updated ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More