

Streamed data processing method in big data environment
A technology of streaming data and processing methods, which is applied in the field of cloud computing, can solve the problems of lack of effective methods for streaming data processing, and achieve the effects of optimizing parallel processing, refining granularity, and increasing throughput
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
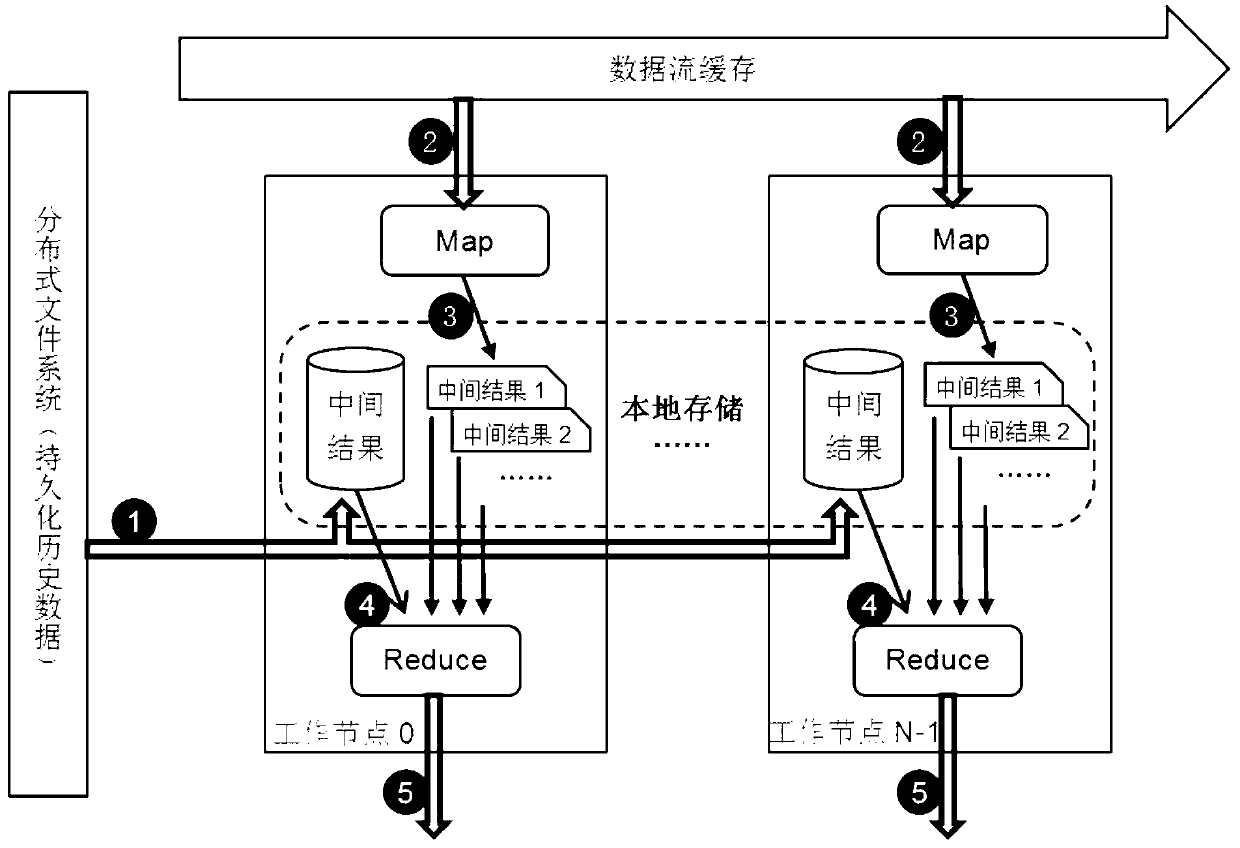
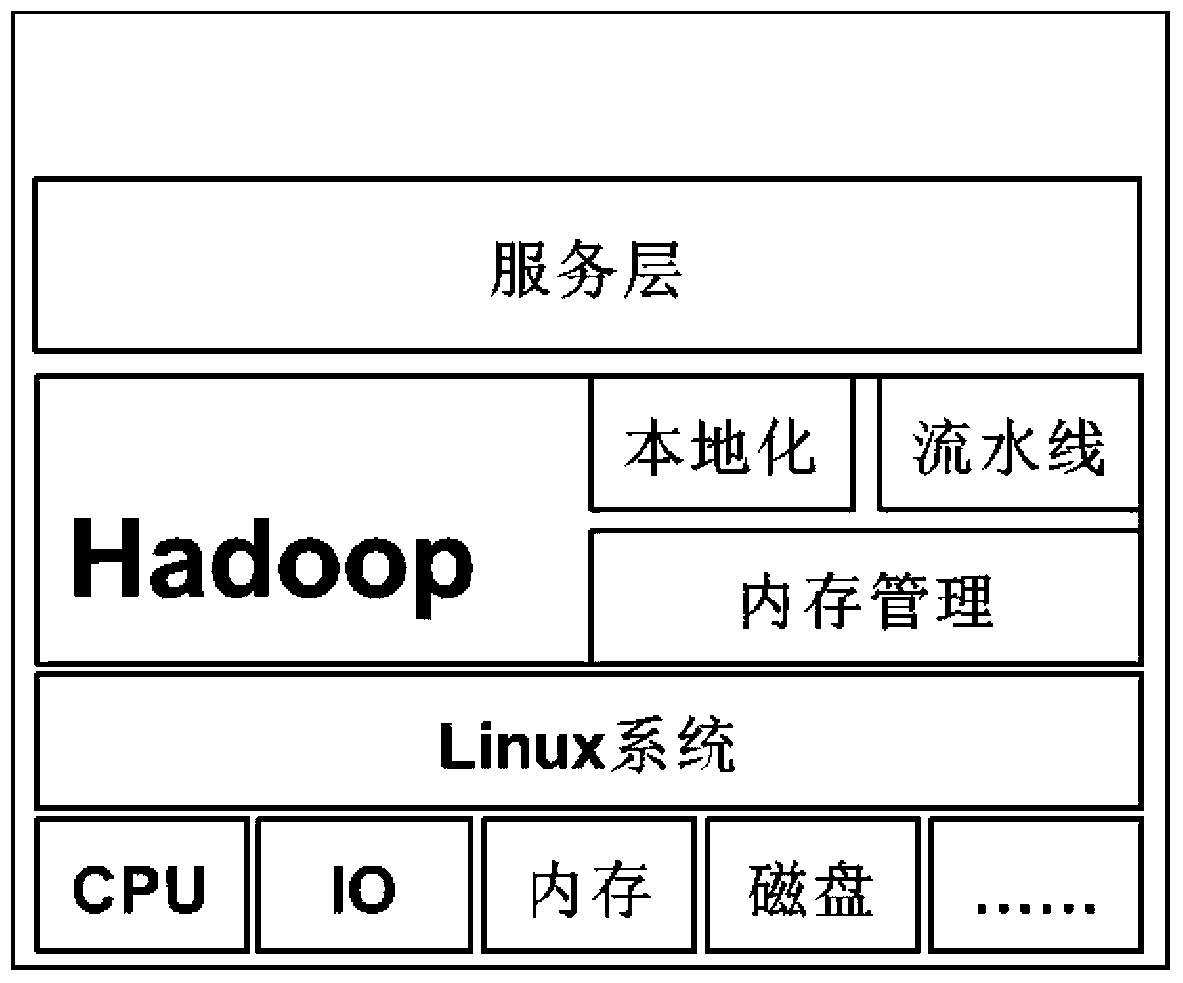
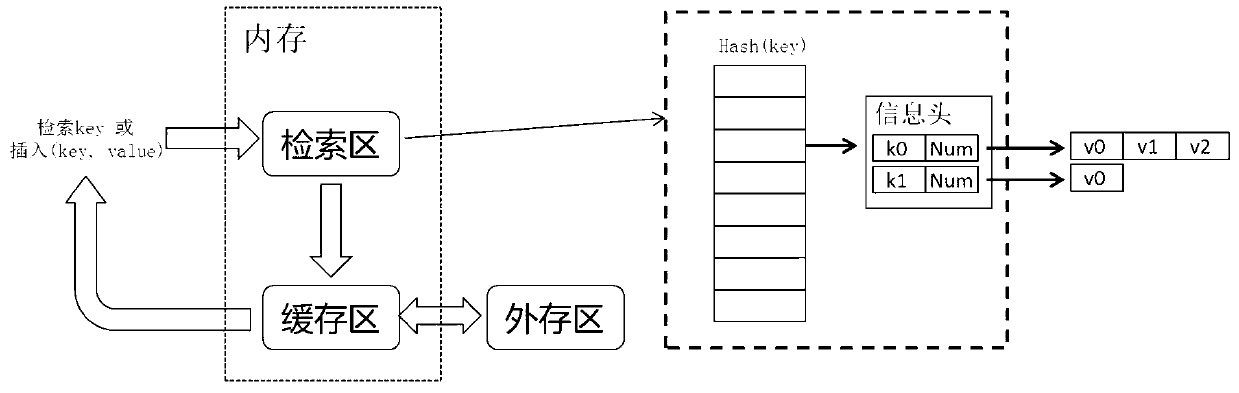
[0031] The streaming data processing in the big data environment is based on the existing Hadoop—a framework that implements MapReduce—and adds three modules to the existing functions to support the processing of streaming data. It is especially suitable for real-time streaming data processing based on a large amount of complex historical data, including data localization module, pipeline scheduling module and memory management module. The specific implementation methods are as follows:
[0032] In the data localization module, the key value interval is generally divided by the Hash function, so that each node can store data without redundancy. In order to ensure the balance of data division, the method based on probability statistics is used to divide the data, so that the data basically obeys the uniform distribution. Perform the following steps:
[0033] Step 1: Randomly collect some historical data or streaming data as samples, sort by keywords, if the keywords are strings...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More