

A system and method for processing multi-stage distributed task scheduling
A technology of distributed task and scheduling method, which is applied in the system field of multi-stage distributed task scheduling, and can solve problems such as not reflecting the idea of phased processing of complex transactions, high overhead, and inability to implement sub-stage rollback and redo, etc. Achieve efficient and reliable processing, no aftereffect, and reduce costs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
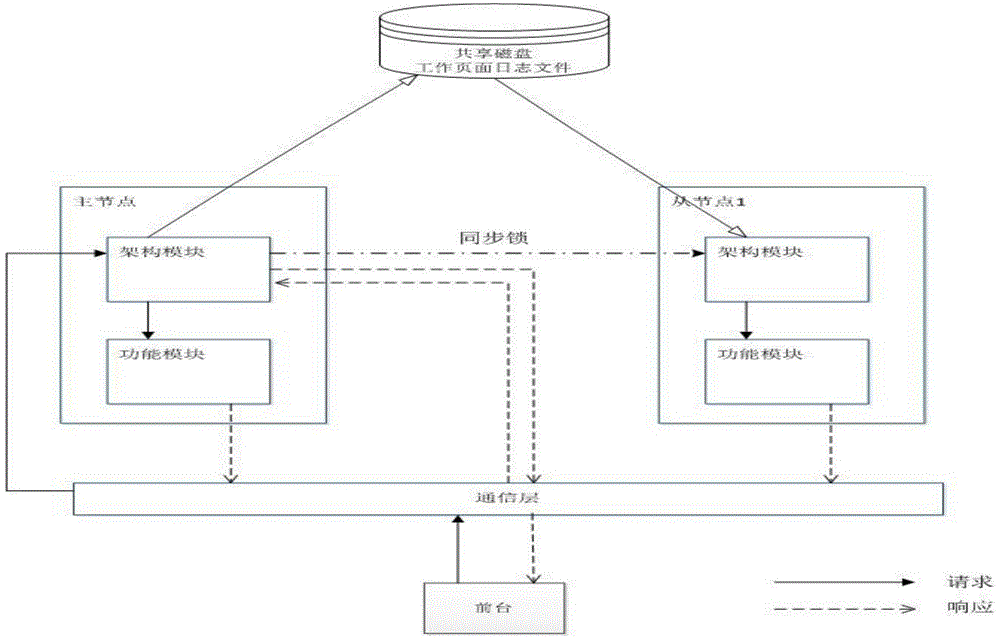
[0033] Such as figure 1 as shown, figure 1 It is a schematic diagram of the system deployment method for processing multi-stage distributed task scheduling. In the figure, a cluster composed of two hosts is taken as an example. Synchronization locks are used between cluster nodes to support functions such as master node election and inter-node control message triggering. All The transactions sent from the front desk are routed to the architecture module of the master node through the communication layer. The architecture module of the master node records the transaction data into the working page log file of the shared disk, and triggers the replay of the working page log file by the slave node architecture module through a synchronization lock , the architecture module of the master-slave node will send its own transaction request to the function module of the local machine for processing, and the response information processed by the function module will be summarized to the...
Embodiment 2
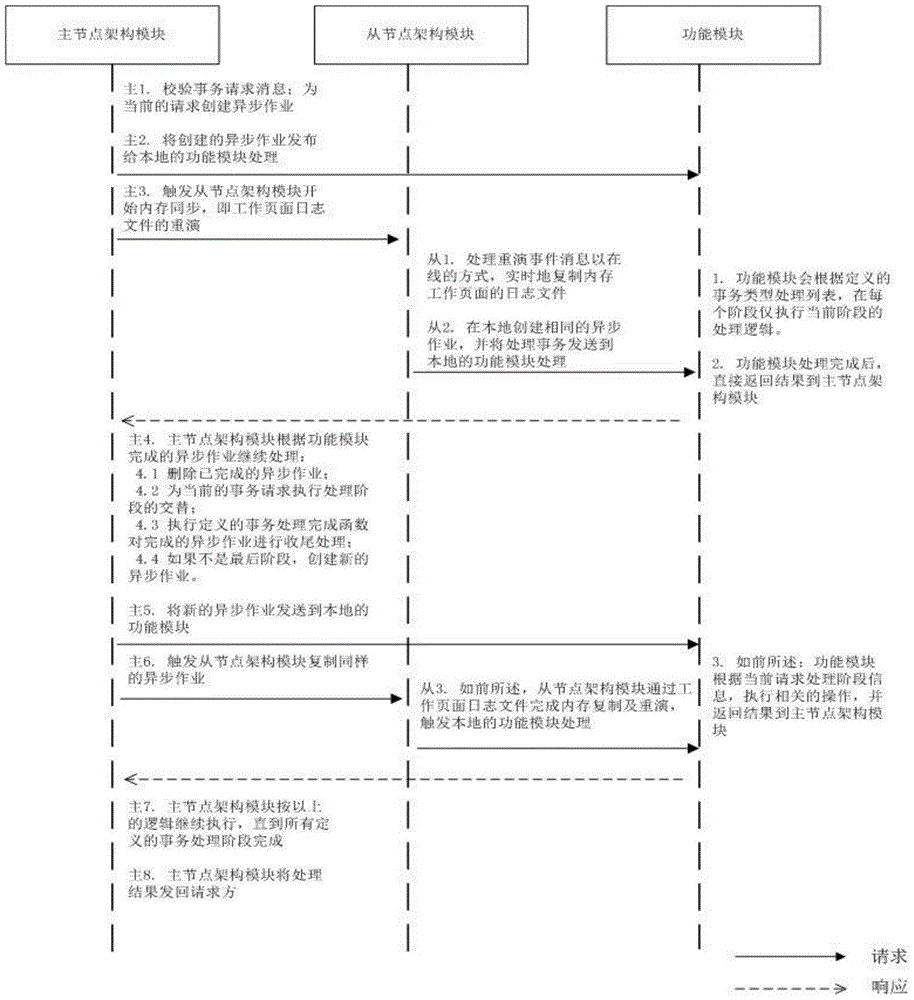
[0035] figure 2 It is a flowchart of the cooperative work of the master-slave node architecture module and its functional modules during the multi-stage processing of transaction requests. As shown in the figure, all transaction requests are first processed by the master node architecture module, and the master node architecture module completes the necessary calibration. After verifying the work, create an asynchronous job for the transaction request and send the asynchronous transaction job to the function module for execution. After that, the master node architecture module immediately triggers the slave node architecture module to replay the work page log file, and the slave node architecture module is based on the log The data recorded in the file creates the same transaction asynchronous job and request data locally, and sends the job request to the local function module for processing. The function module of each node receives the transaction request through an asynchro...
Embodiment 3
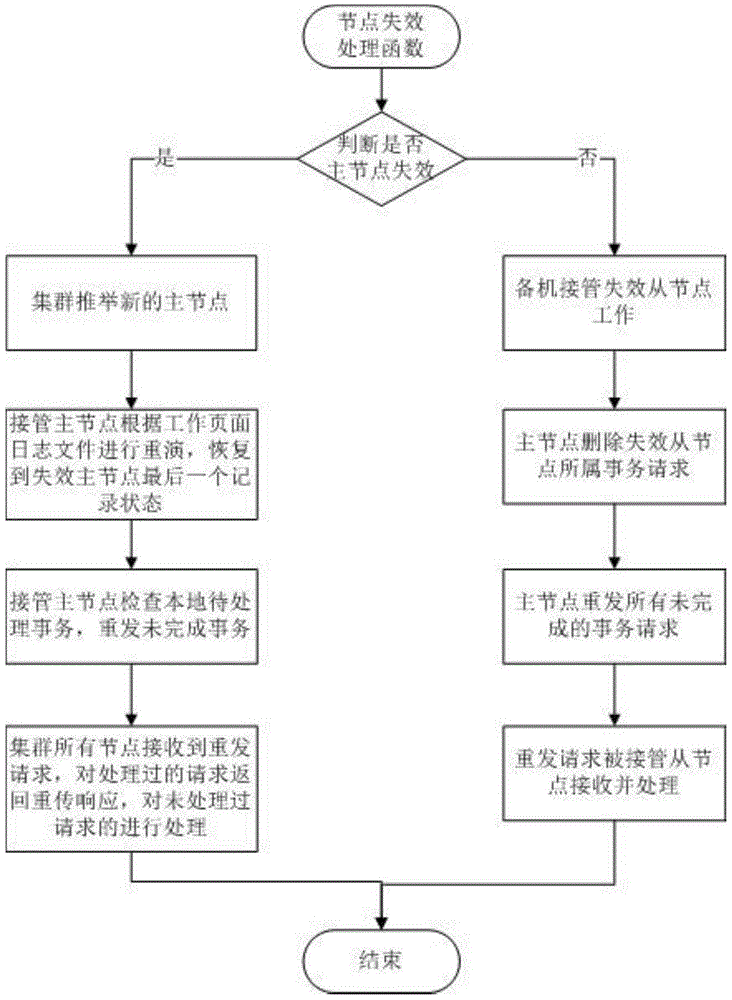
[0039] image 3 This is the flow chart of the takeover process of the standby machine for node failure in the cluster. If a node fails and exits in the cluster, the synchronization message lock between the cluster nodes will trigger a node exit event on all nodes, and the remaining nodes in the cluster will respond to the event. If the master node fails, the newly elected master node will replay according to the working page log file recorded by the failed master node on the shared disk, restore to the same state as the last record of the failed master node, and then continue to take over the task processing; if If the slave node fails, the standby machine will directly take over the work of the failed slave node, and the master node will resend unfinished transactions to the slave node for processing. This mechanism ensures that multi-stage distributed complex transactions can still be processed correctly even when the master node fails. .
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More