

Denormalization strategy selection method based on frequent item set mining algorithm
A technology of frequent itemset mining and frequent itemsets, which is applied in computing, structured data retrieval, special data processing applications, etc., to achieve the effect of solving performance bottlenecks
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
[0065] Example 1: The denormalization strategy selection method based on the frequent itemset mining algorithm is characterized in that it includes the following steps:
[0066] 1-(a). Obtaining the database log file step: obtaining the database log file to be analyzed;
[0067] 1-(b). Parsing the log step: analyzing the SELECT statement in the log, extracting the table name involved in it, and the field name as the transaction item; then obtaining the transaction record involving cross-table query or only the transaction record of single-table query;
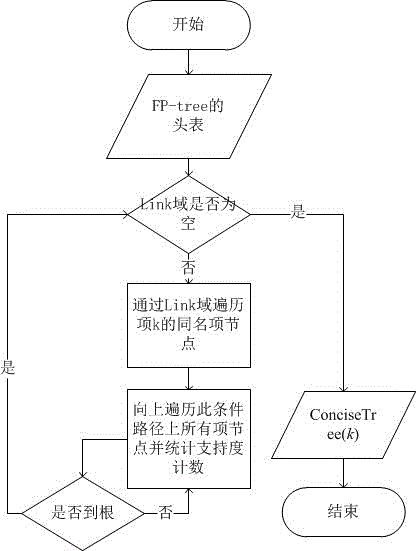
[0068] 1-(c). Data mining step, this step is based on the frequent pattern mining of the simplified prefix tree, which includes three parts in turn:
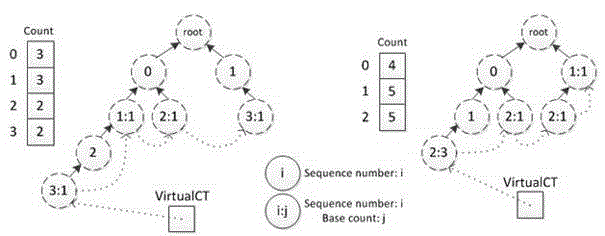
[0069] (c-1). The step of establishing an FP-tree: read the transaction record set, and establish a frequent pattern tree (FP-tree) based on the preset support experience value, and the persistence threshold is determined by analyzing a large number of denormalized examples, is ...
example 2
[0093] Obtain the database log file to be analyzed: Assume a simplified test data set TestSet, as shown in Table 1.
[0094] The default support count threshold is 3.
[0095]
[0096] Table 1: Test dataset TestSet
[0097] Analyze the SELECT statement in the log, extract the table names involved, and use the field names as transaction items: the frequent 1-itemset (or item sequence conversion table) obtained after the test data set TestSet is read into memory, as shown in Table 2 .
[0098] serial number project 0 course.academy_id 1 academy.academy_id 2 course.course_id 3 teacher.teacher_id 4 give_lesson.givelesson_id
[0099] Table 2: Frequent 1-itemset (item sequence conversion table)
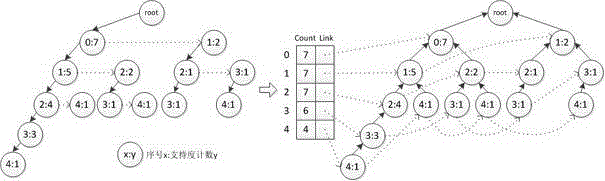
[0100] Such as figure 2 Read the transaction data set into memory, and filter according to the preset support threshold to obtain frequent 1-itemsets;
[0101] Mount all frequent items in the transaction set in the FP-tree;
[0102] Su...
example 3
[0109] Obtain the database log file to be analyzed: Assume a simplified test data set TestSet, as shown in Table 1.
[0110] The default support count threshold is 3.
[0111]
[0112] Table 1: Test dataset TestSet
[0113] Analyze the SELECT statement in the log, extract the table names involved, and use the field names as transaction items: the frequent 1-itemset (or item sequence conversion table) obtained after the test data set TestSet is read into memory, as shown in Table 2 .
[0114] serial number project 0 course.academy_id 1 academy.academy_id 2 course.course_id 3 teacher.teacher_id 4 give_lesson.givelesson_id
[0115] Table 2: Frequent 1-itemset (item sequence conversion table)
[0116] Such as figure 2 Read the transaction data set into memory, and filter according to the preset support threshold to obtain frequent 1-itemsets;
[0117] Mount all frequent items in the transaction set in the FP-tree;
[0118] Su...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More