

Classified variable clustering method based on attribute weight similarity
A clustering method and a technology for classifying variables, applied in special data processing applications, instruments, electrical digital data processing, etc., to achieve the effects of low time and space complexity, high efficiency, and high accuracy of clustering results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

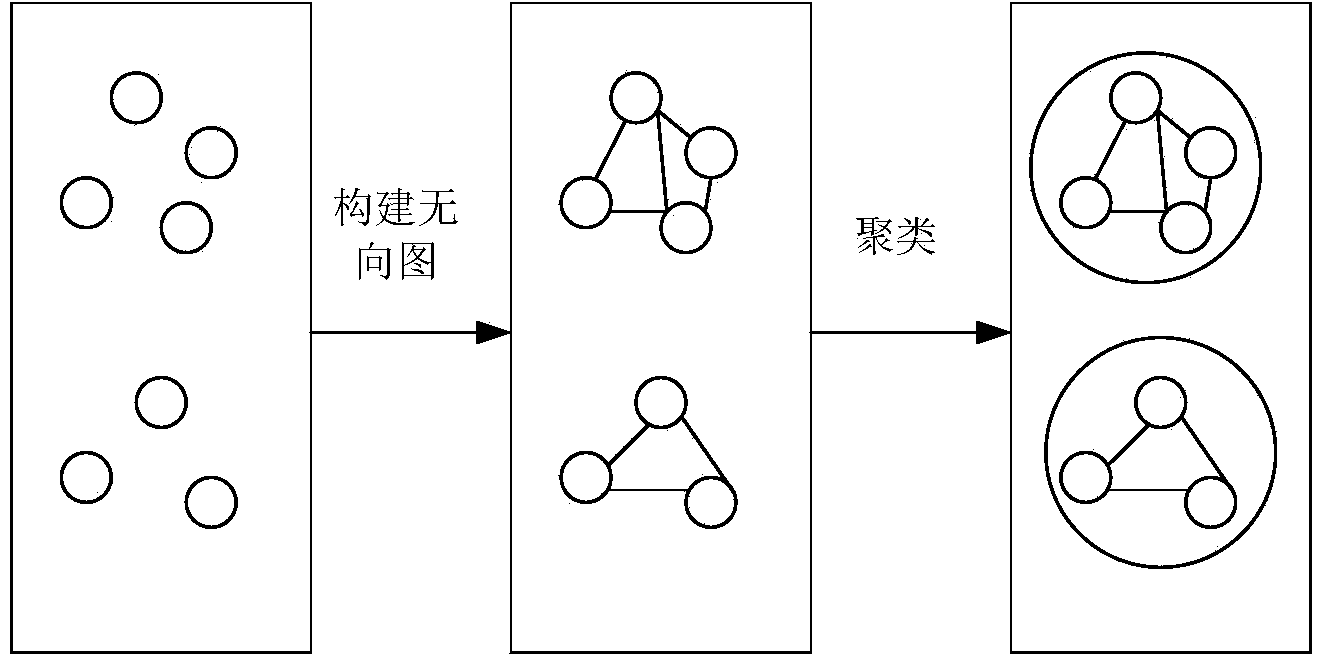
Examples
Embodiment 1
[0051] In this embodiment, the mushroom (mushroom) data set is selected for testing. The mushroom data set contains a total of 8124 types of mushroom information, including 4208 types of poisonous mushrooms and 3916 types of non-toxic mushrooms. This dataset can be downloaded from the UCI official website. Implement ROCK, Squeezer, DNNS and the clustering method (CABAS) of the present invention with Java. The operating system of the experimental environment is Windows7version6.1.7600, and the CPU is Core TM i3-2310M2.1GHz, memory is 4G. For ROCK, Squeezer and the clustering method (CABAS) of the present invention, parameters need to be given, each method is run multiple times, and the optimal result of different parameters is obtained. For DNNS, it is sufficient to end when the cohesion metric function suddenly decreases.
[0052] Implementation steps:
[0053] 1) Apply formula (1) to calculate the similarity between each data point in the mushroom data set. Table 3 is...
Embodiment 2
[0069] In this embodiment, a Hayes-Roth data set is selected for testing. The Hayes dataset contains a total of 132 records. This data set can be downloaded from the official website of UCI, and it is still clustered by several methods in Example 1 in Java language.
[0070] Implementation steps:
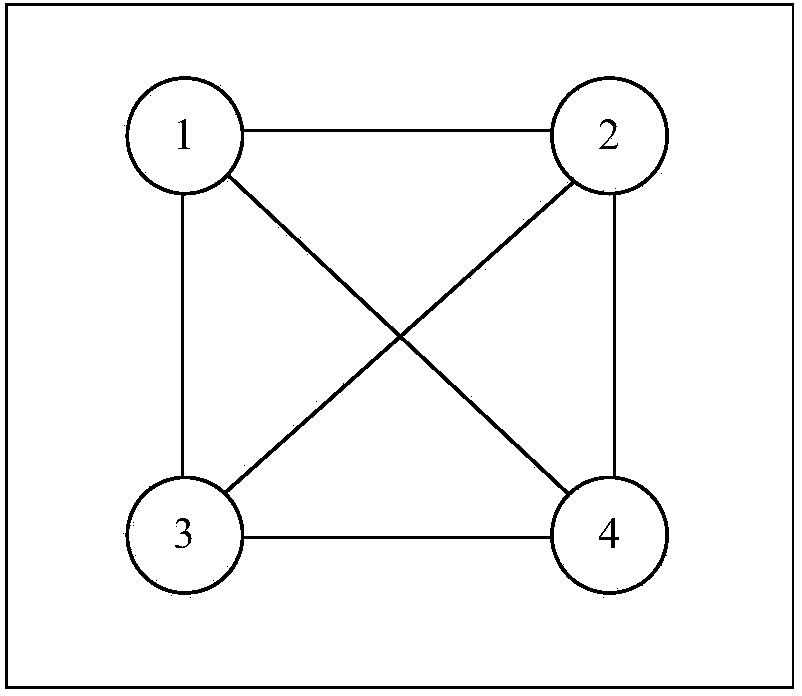
[0071] 1) Apply formula (1) to calculate the similarity between each data point in the Hayes-Roth data set. Table 7 is the five attribute values of two data points extracted from the mushroom (mushroom) data set, and Table 8 is the corresponding weight of each attribute |V 1 |. The function in formula (1) The resulting values are: 2, 1, 0, 2, 0. Therefore, Sim(1,2)=5 / 7=0.7142.
[0072] Table 7 Two data points in the Hayes dataset
[0073]
[0074] Table 8 The weight of each attribute in the Hayes dataset
[0075]
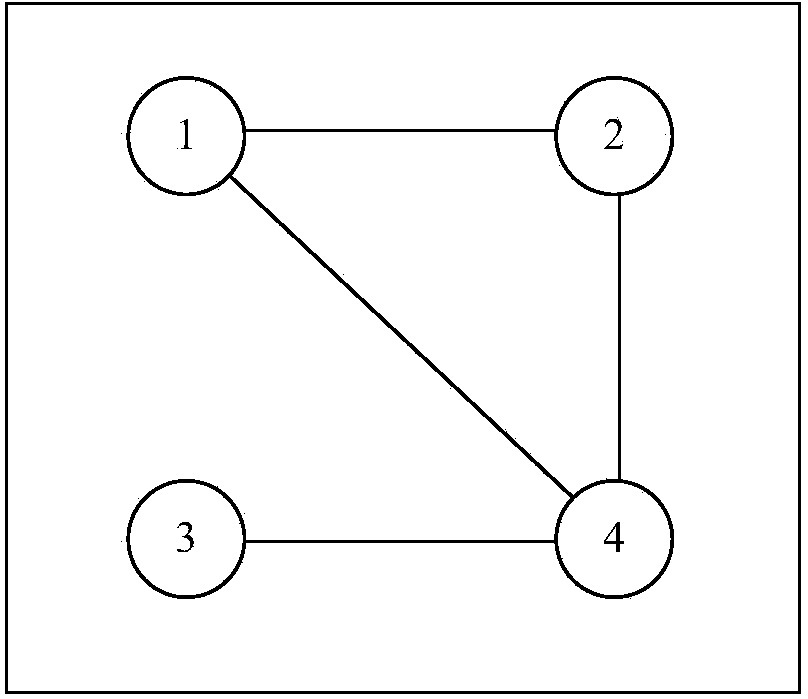
[0076] 2) Construct an undirected graph, and use each data point in the Hayes-Roth data set as a node in the graph. If the similarity between two data ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More