

Improvement-based KNN (K Nearest Neighbor) text classification method
A text classification and text technology, which is applied in text database clustering/classification, unstructured text data retrieval, special data processing applications, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
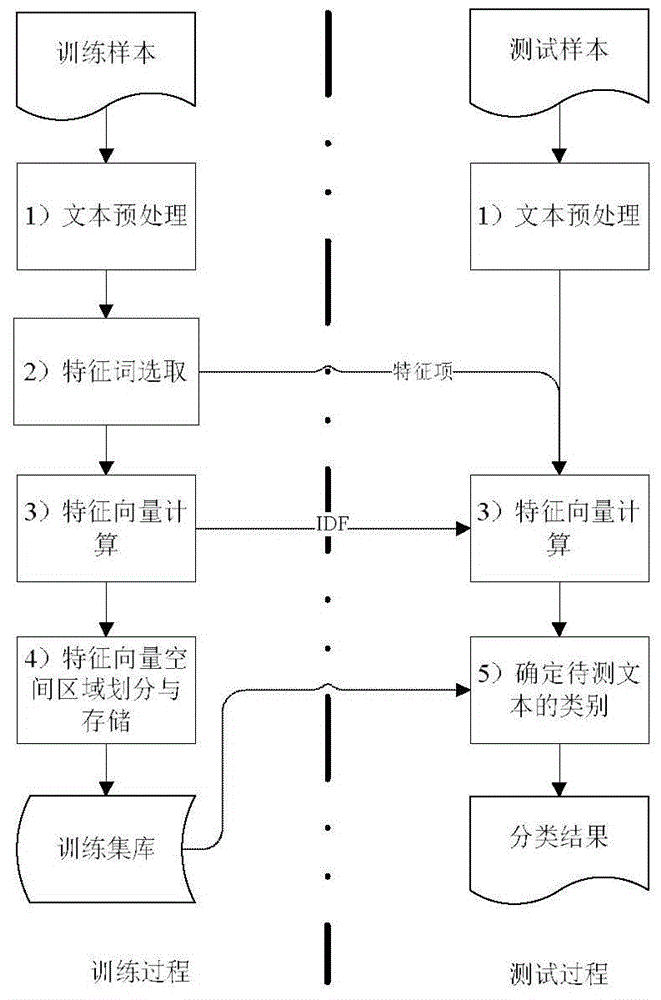
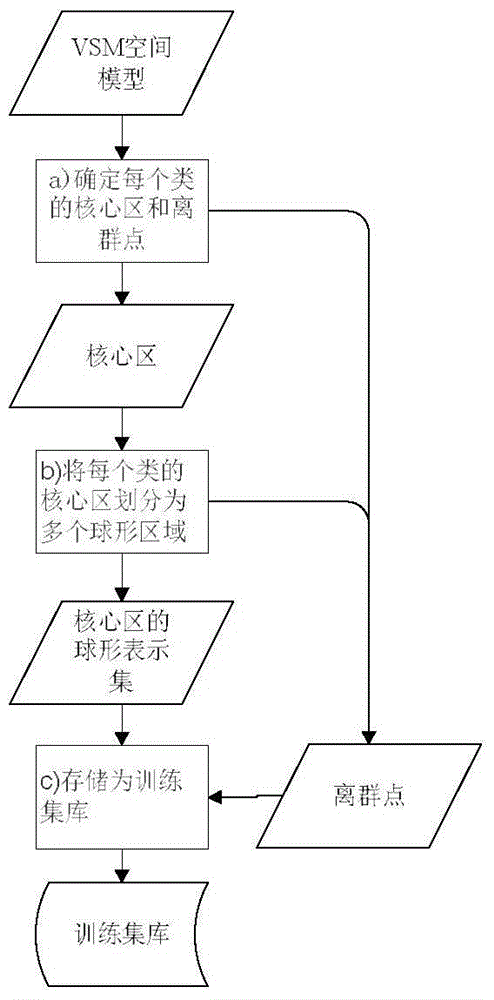
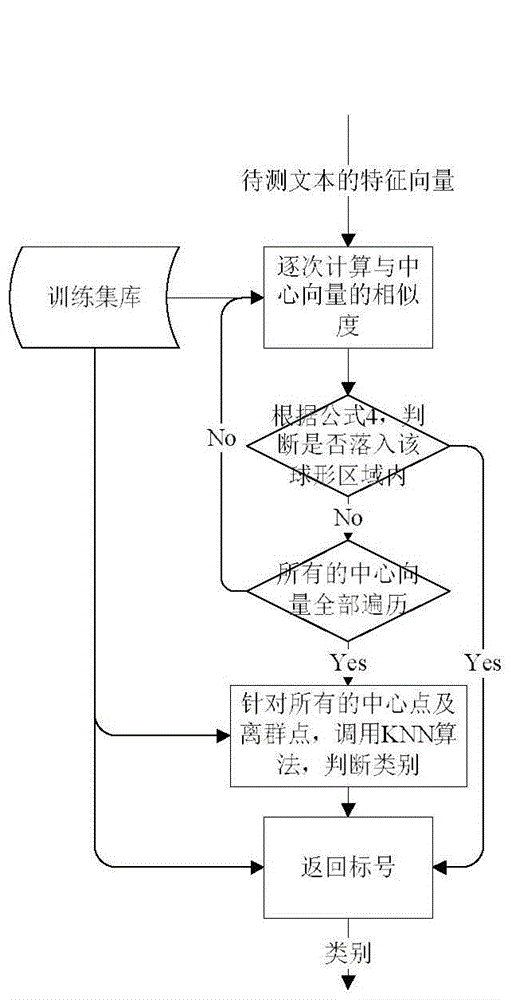
[0056] The invention proposes an improved KNN-based text classification algorithm, which is applied in the review process of software requirements and design documents (especially software reliability review). The algorithm first preprocesses the training text and builds a feature vector space model, including word segmentation (this algorithm uses a general word segmentation method that combines statistical word segmentation and a dictionary for word segmentation), and removes stop words (stop words refer to some in the file set) Words with a high frequency of occurrence and obviously no or little contribution to the classification task. Function words such as adverbs, pronouns, articles, prepositions, and conjunctions that appear in the file set that do not represent actual semantics belong to the category of stop words), feature Word extraction (the purpose is to select words that are helpful for classification, and reduce the dimension, using the chi-square test method, see...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More