

High concurrency data storage method and device
一种数据存储、数据的技术,应用在数据处理领域,能够解决数据库链接多、服务器宕机、占用资源多等问题,达到提升存储效率、避免宕机的效果
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
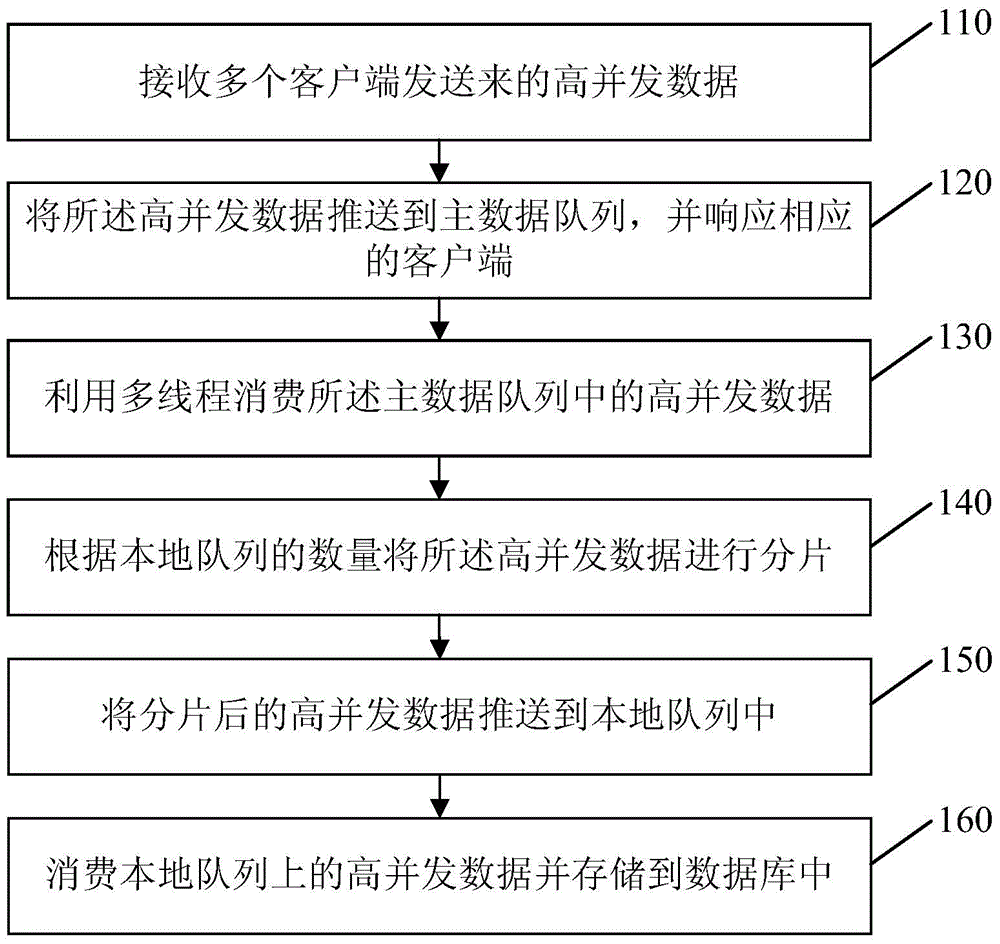
[0026] figure 1 It is a flow chart of the high-concurrency data storage method provided by Embodiment 1 of the present invention. This embodiment is applicable to the storage of high-concurrency data. The method can be executed by the server, and specifically includes the following steps:
[0027] Step 110, receiving high-concurrency data sent by multiple clients.
[0028] Among them, high concurrency refers to a relatively large number of visits at a certain moment. The server receives requests from multiple clients, and many clients request at the same time to form highly concurrent data.
[0029] Step 120, push the high-concurrency data to the main data queue, and respond to the corresponding client.
[0030] Among them, the data queue adopts distributed MQ (Message Queue, message queue), which can support distributed expansion, and can also make the framework highly available, and still have relatively objective performance when processing big data. Among them, ActiveMQ...
Embodiment 2
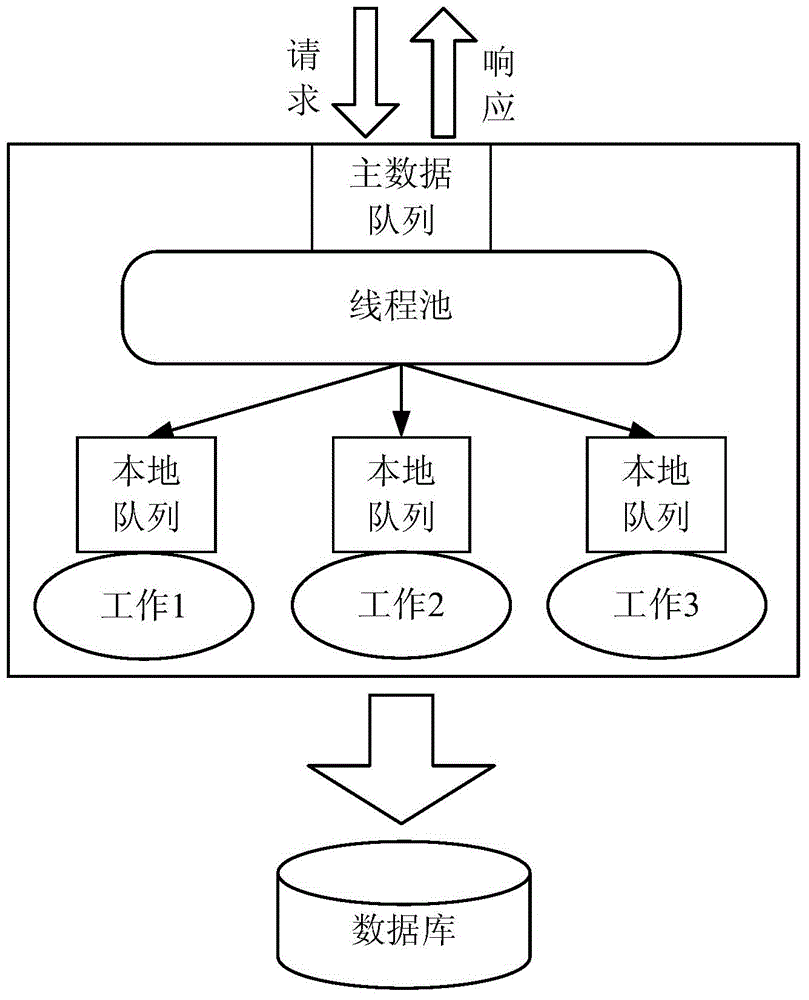
[0054] figure 2 It is an architectural design diagram of the high-concurrency data storage method provided by Embodiment 2 of the present invention. Such as figure 2 As shown, the main data queue is the main entry queue for all data. When the data is pushed to the queue, the result will be returned immediately to improve the response speed; the thread pool (Thread Pool) provides multi-threaded data processing and pushes the data to the corresponding The local queue can improve the consumption speed of messages, and at the same time, it can also use the characteristics of MQ to persist data and prevent data loss; the local queue is used to store data after fragmentation and prevent data loss after fragmentation; work (Work )1, Work 2, and Work 3 can independently control the amount of captured data and the time interval for capturing data by timing / instantly consuming data, processing the data and storing it in the database.
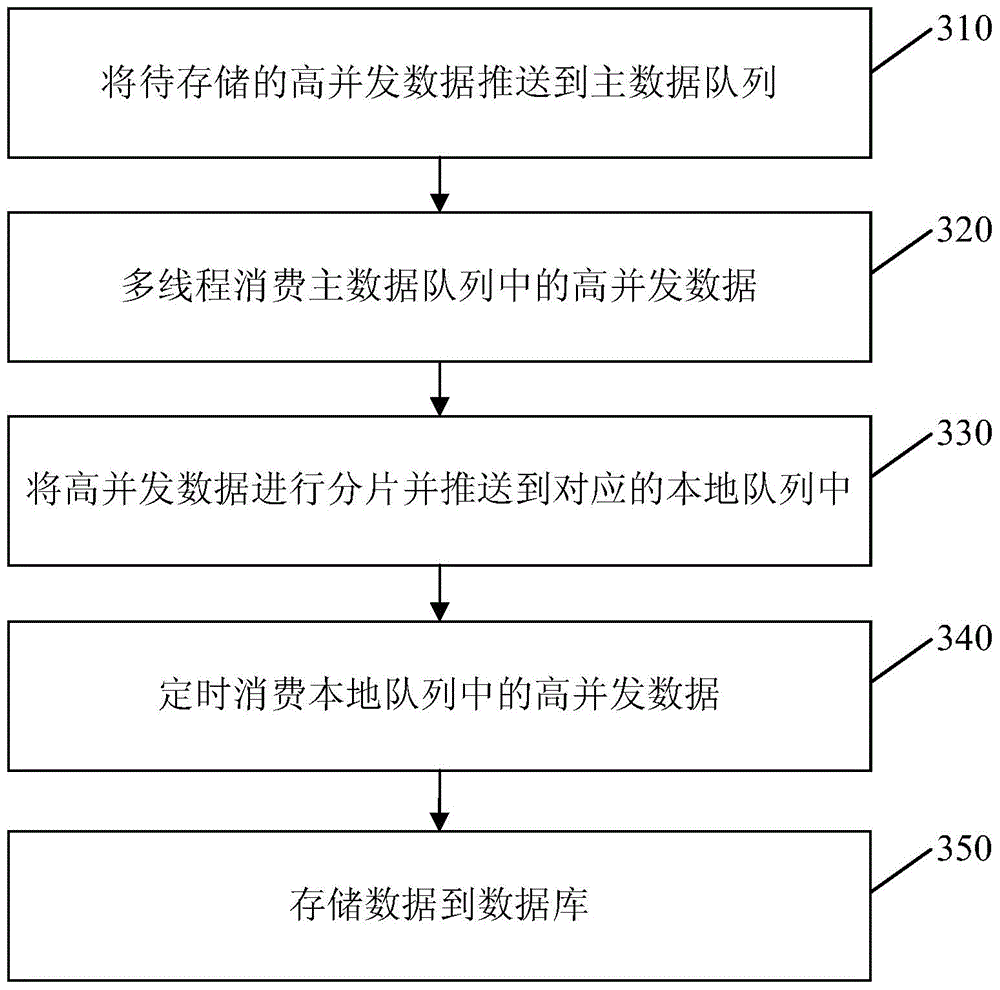
[0055] image 3 It is a flow chart of the high...
Embodiment 3
[0067] Figure 4 is a schematic diagram of a high-concurrency data storage device provided in Embodiment 3 of the present invention. The high-concurrency data storage device provided in this embodiment is used to implement the high-concurrency data storage method provided in Embodiment 1. Such as Figure 4 As shown, the high-concurrency data storage device provided in this embodiment includes: a receiving module 410 , a first push module 420 , a consumption module 430 , a fragmentation module 440 , a second push module 450 and a storage module 460 .
[0068] Among them, the receiving module 410 is used to receive high concurrency data sent by multiple clients; the first push module 420 is used to push the high concurrency data to the main data queue and respond to corresponding clients; the consumption module 430 is used to Utilize multithreading to consume the high concurrency data in the main data queue; the fragmentation module 440 is used to fragment the high concurrency...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More