

A background refresh method based on spark-sql big data processing platform
A technology of big data processing and background, applied in electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of waste of control node resources, low query and import efficiency, performance discount, etc., to improve the utilization rate of system resources , the effect of increasing the query time and shortening the query time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
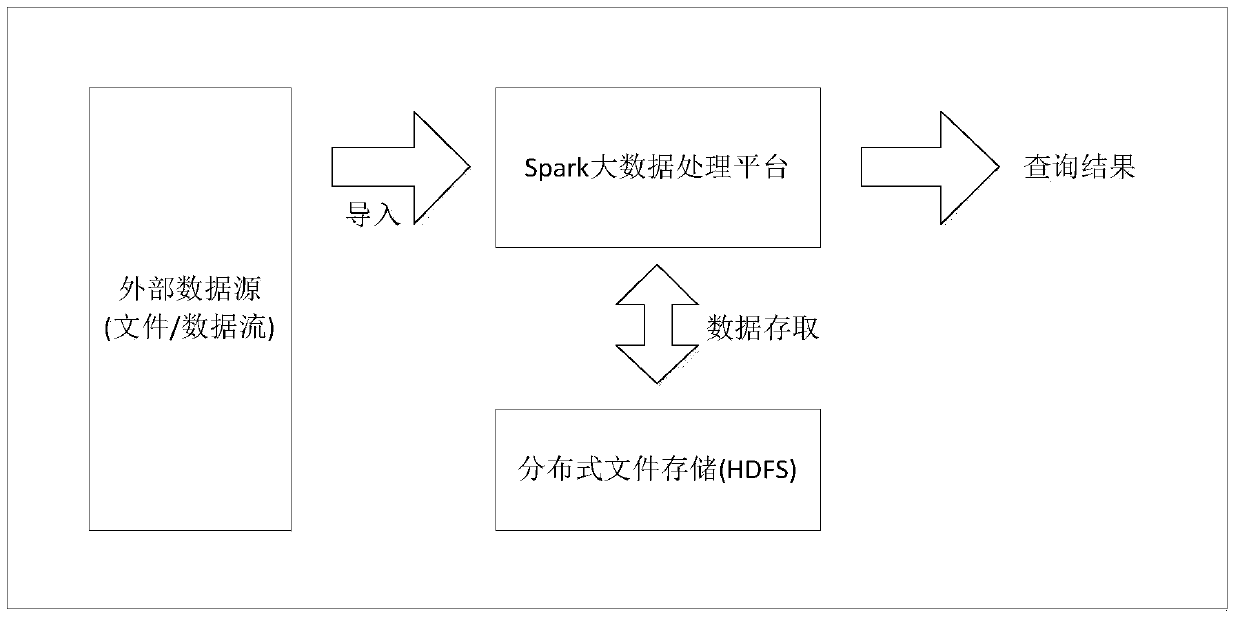
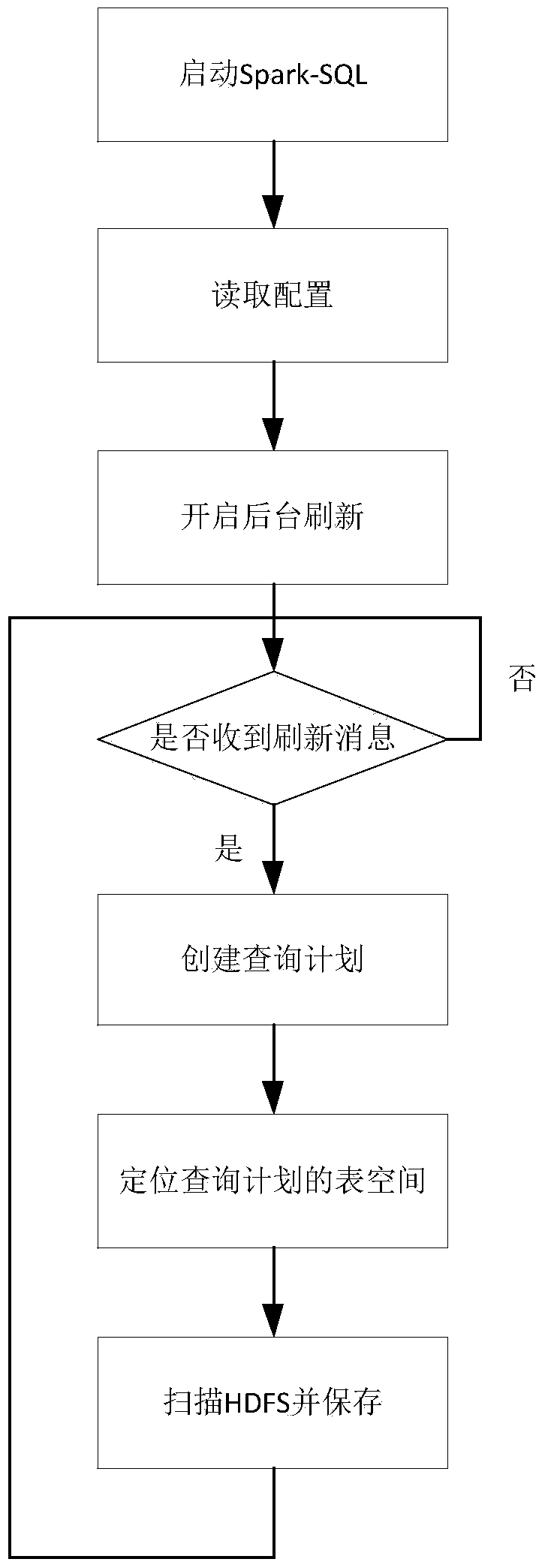
[0042] Such as figure 2 and image 3 As shown, the background refresh method based on the Spark-SQL big data processing platform in this embodiment is to create a refresh process in the entry function of Spark-SQL and set a timing refresh mechanism to regularly scan the specified table space file directory of the distributed file system HDFS structure, as a preference, the refresh result is stored in the memory to support the query request of the table data.
[0043] Add configuration items in hive-site.xml under the conf folder of the Spark installation directory, and you can customize whether the background refresh process is enabled, the refresh interval, and the set of large data tablespaces to be refreshed.
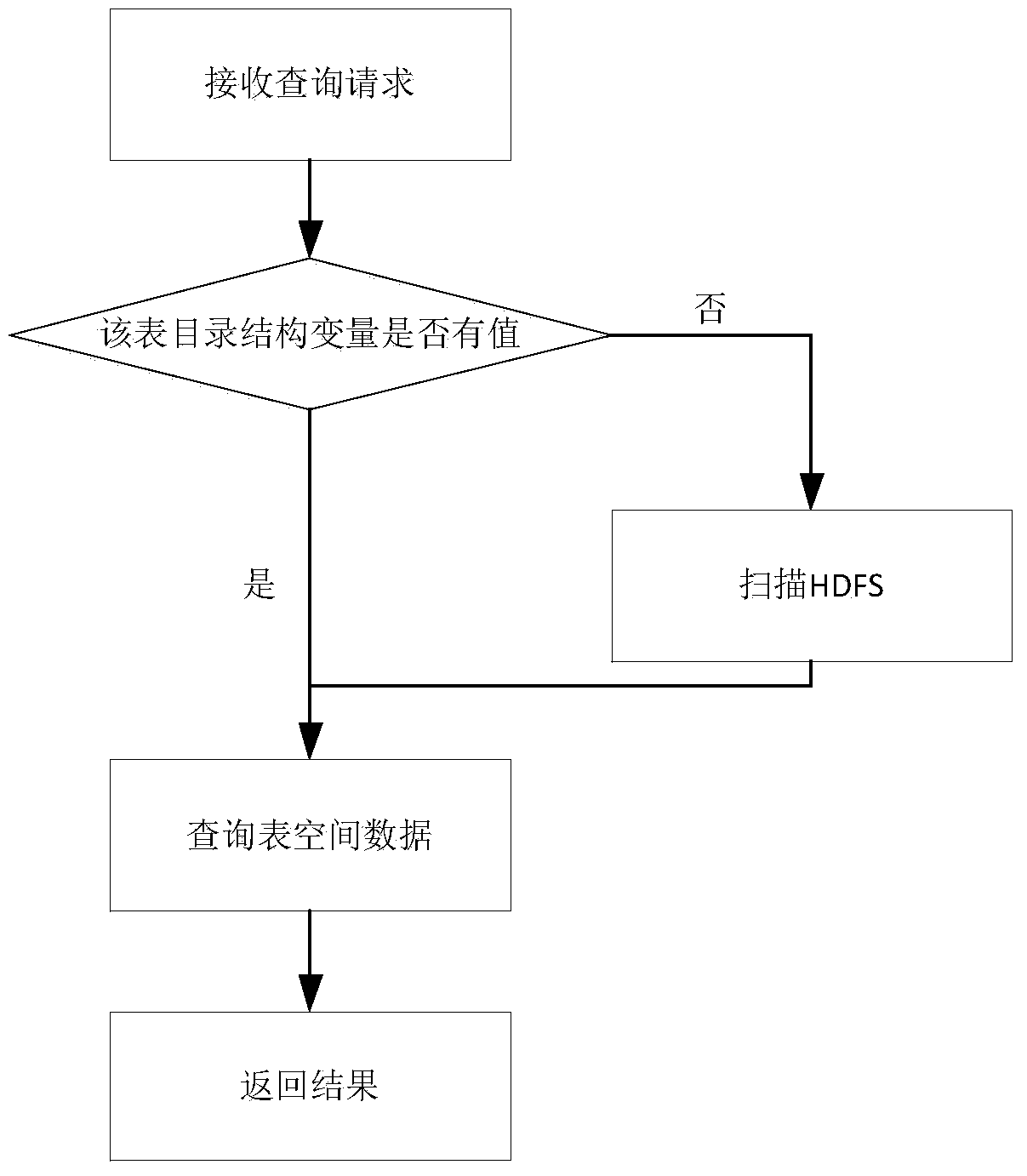
[0044] If the refresh process is enabled, there is no directory structure information of the specified tablespace in the memory before the first refresh of the refresh process is completed. At this time, if Spark-SQL receives a query statement, it uses the original...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More