Offline analysis method for massive data
A technology for off-line analysis and massive data, applied in the field of off-line analysis, can solve problems such as increasing data robustness and cleanliness, achieve the effect of solving the bottleneck of data collection, improving collection efficiency, and improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
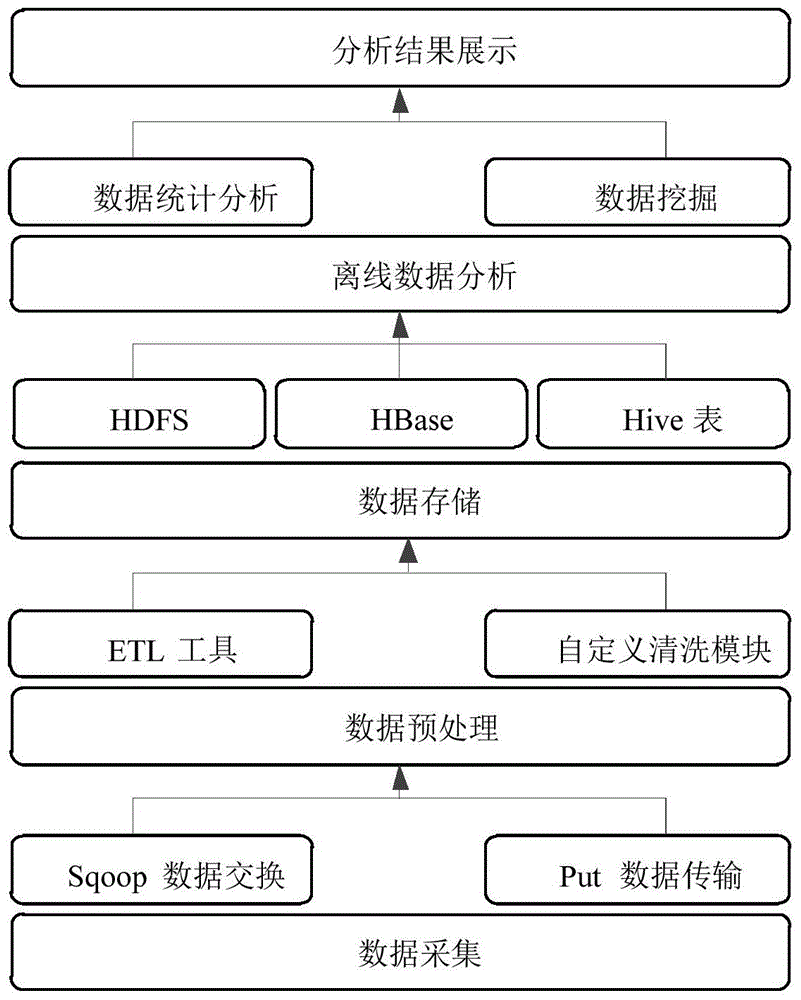
[0042] The present invention utilizes the distributed storage of Hadoop platform cluster mass data and the efficient and fast parallel computing capability, specifically:
[0043] Data acquisition and preprocessing. For different types of electric power big data, a variety of data collection modes can be adopted. For streaming data, the Kafka collection tool is used to aggregate the streaming data to the Kafka cluster, and then stored and processed by HBase. For relational databases, the Sqoop data exchange tool is used, combined with the data cleaning module that can be customized and configured, and the distributed import of relational data to HDFS or HBase is realized through the Map-Reduce distributed computing framework. At the same time, Sqoop provides the incremental import function of data. For large data files, they need to be imported into Hadoop using FTP protocol or localized upload. After the power big data is stored in HDFS, ETL tools can be used to perform da...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More