

Heterogeneous-webpage-oriented data collection and labeling methodwebpage
A technology of data collection and web pages, applied in the direction of network data indexing, network data retrieval, data mining, etc., to achieve high-quality collection, accurate data classification, and increase work efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
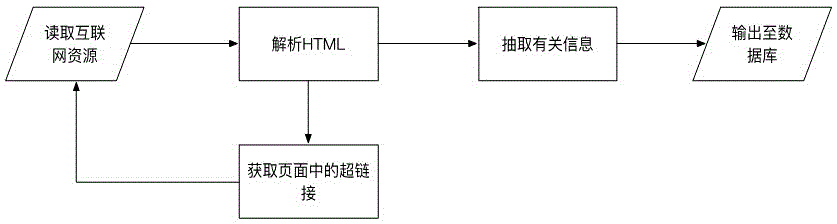
[0027] The present invention will be further described below in conjunction with the accompanying drawings and embodiments, but the present invention is not limited to the scope of the described embodiments. This embodiment provides a heterogeneous webpage-oriented data collection and labeling method taking educational and non-educational data as an example, such as figure 1 shown, including the following steps:
[0028] In the data collection stage of this embodiment, Scrapy, a web crawler framework based on Python, is used to collect educational and non-educational data on the Internet. Scrapy provides a fast, high-level screen scraping and WEB scraping framework for crawling WEB sites and extracting structured data from pages. Use this framework to develop crawler applications simply and quickly, and extract corresponding data into the database for various purposes, such as: data mining, information processing, etc.
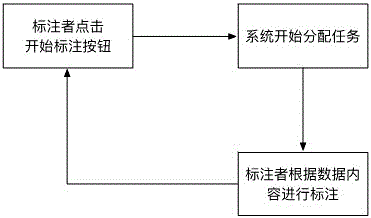
[0029] In the data labeling stage of this example, the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More