

Video description method based on multi-feature fusion
A technology of multi-feature fusion and video description, applied in the field of video description
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
[0056] Embodiment: combine below Figure 1 to Figure 8 The video description method based on multi-feature fusion provided by the present invention is specifically described as follows:
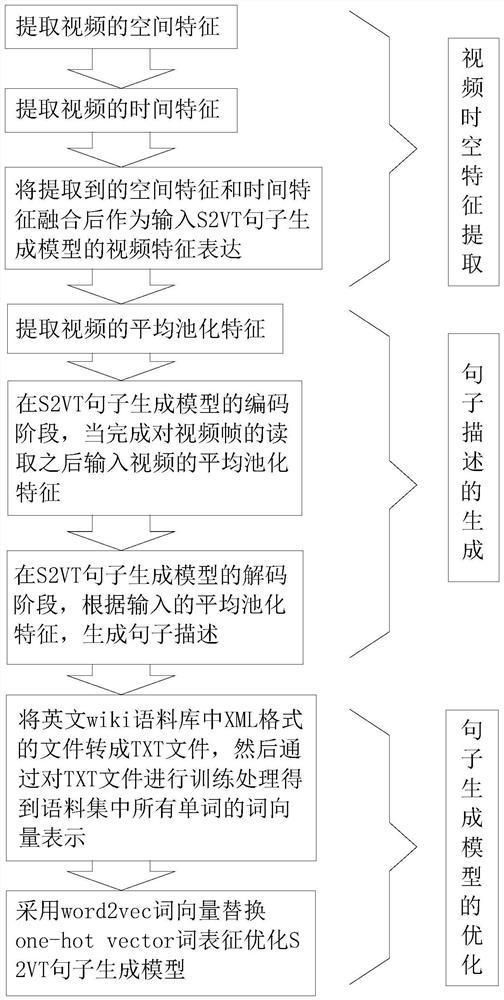
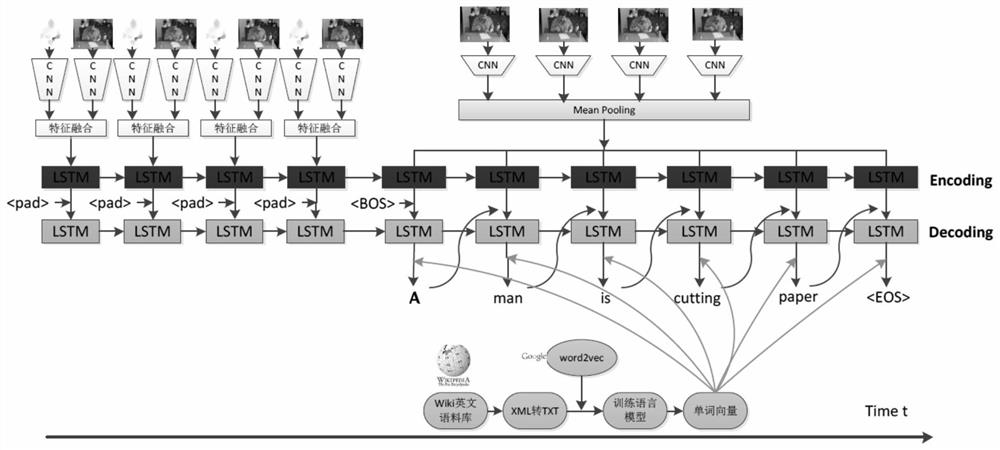
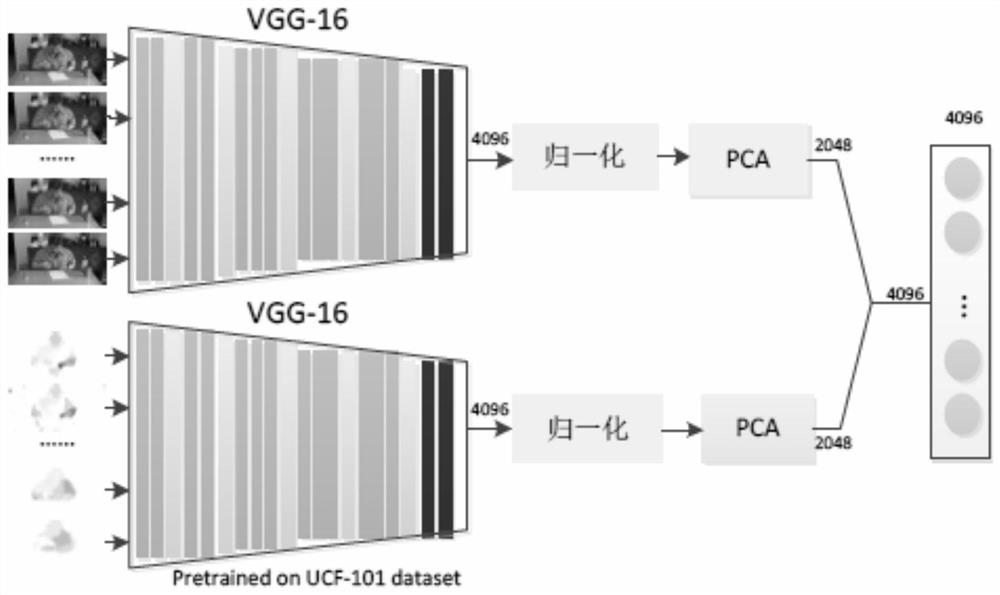
[0057] The overall flowchart and frame diagram of the inventive method are respectively as figure 1 and figure 2 As shown, the deep spatio-temporal features of videos are extracted by fusing traditional CNN features and SIFT stream features. Then, according to the extracted features, the S2VT sentence generation model with integrated features is used to generate corresponding sentence descriptions. Finally, the word2vec word vector is used to replace the one-hot vector word representation to optimize the sentence generation model.
[0058] In this embodiment, BLEU and METEOR are used to evaluate the video description method and performance, and the data set used in the demonstration experiment is: MSVD (Microsoft Research Video Description), also known as Youtube2Text. MSVD is c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More