

Big-data parallel computing method and system based on distributed columnar storage
A distributed columnar and parallel computing technology, applied in the field of big data processing, can solve problems such as slow computing speed, reduce time consumption, improve data query efficiency, and ensure real-time query analysis.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0037] The present invention will be further described below in conjunction with specific examples.
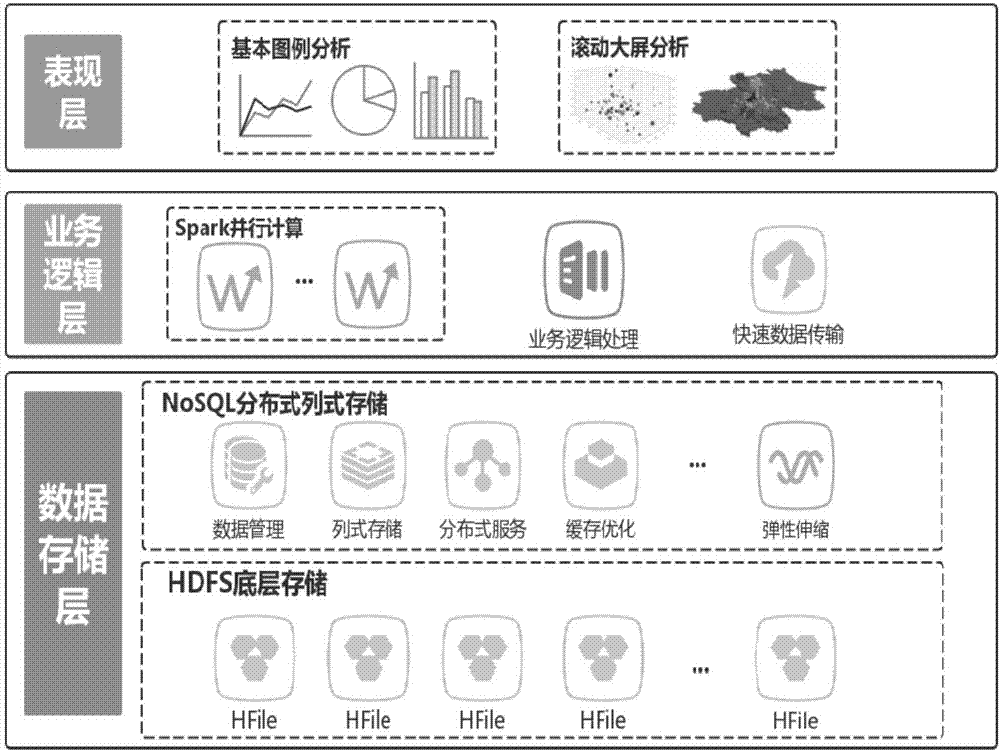
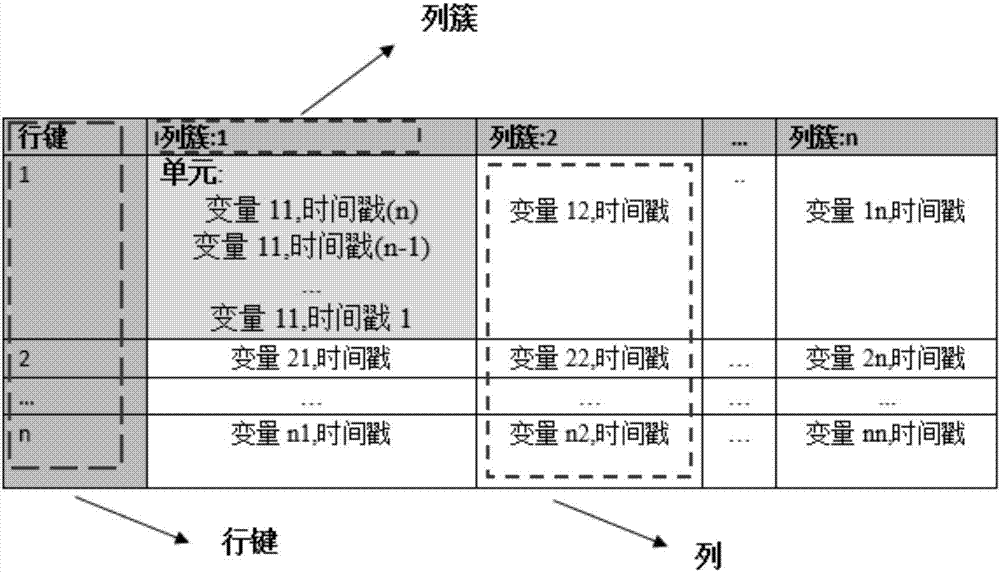
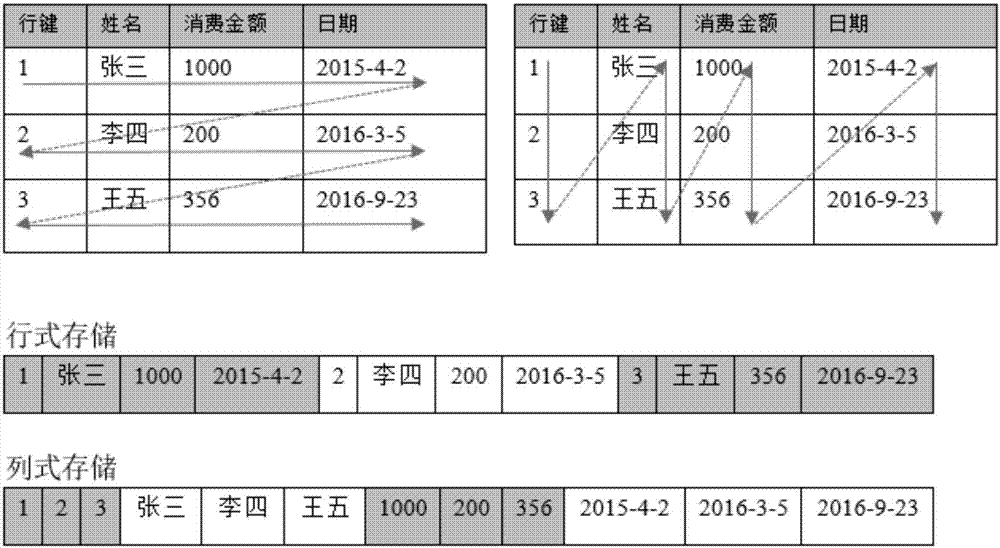
[0038] The large data parallel computing method and system based on distributed columnar storage provided by this embodiment fully utilizes the processing performance of the cluster cloud server memory query and the advantages of columnar storage, and avoids the need to directly read HDFS file system data when querying. The resulting delay problem and the redundant data transmission problem caused by row storage greatly improve the data reading efficiency. In addition, the solution uses a Spark-based parallel computing framework on top of NoSQL-based columnar storage to further improve the efficiency of real-time query analysis through parallel computing. At the same time, due to the scalability of distributed clusters, the distributed architecture can meet the elastic and scalable requirements of massive data storage. The hierarchical structure of this program is as follows ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More