Iterative data equilibrium optimization method for Spark parallel computing framework
A parallel computing and iterative technology, applied in the field of big data processing and high-performance computing, can solve the problems of insufficient accuracy, lack of versatility, and delayed job completion time, so as to improve overall performance and achieve overall balance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
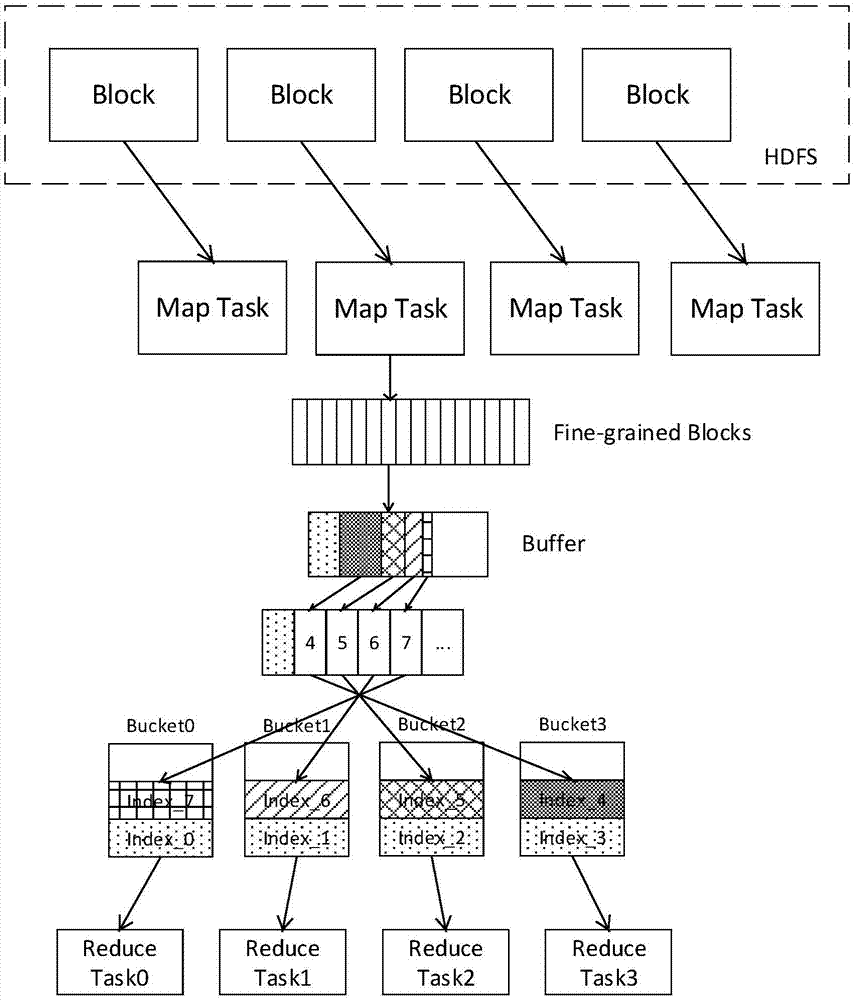
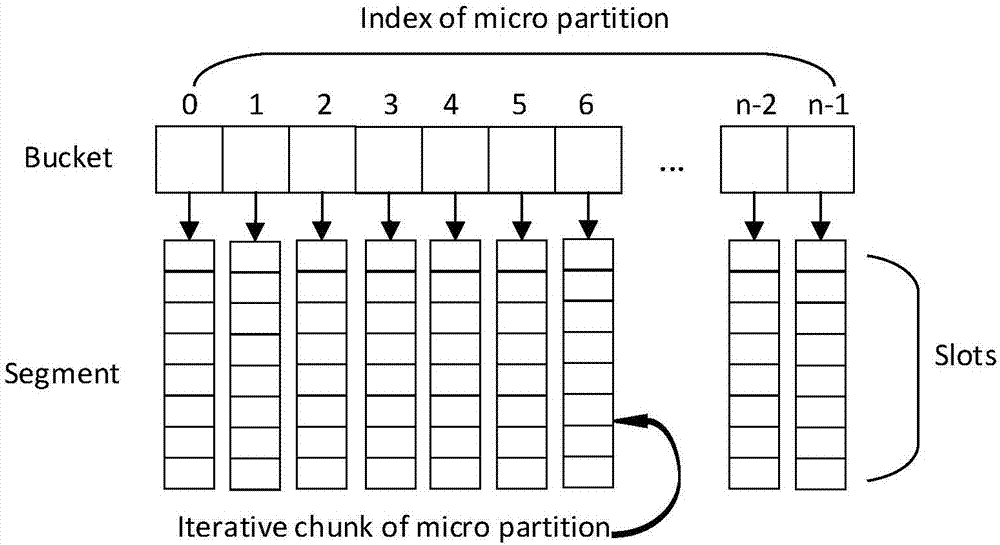
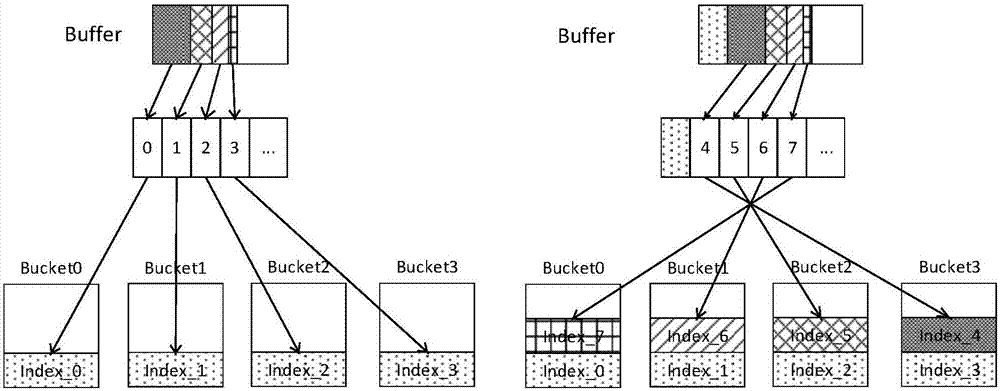
[0054] Taking the classic big data-oriented WordCount program as an example, combined with Figure 1 ~ Figure 3 , to further describe the specific embodiment of the present invention:
[0055] Assume that the WordCount program wants to count the words of the contents of 4 blocks and distribute them to 4 nodes. There are 2 rows of data in each block, and the data content of each block is as follows:
[0056] Block1:
[0057] Spark is a fast and Spark is a general-purpose engine for large-scale data processing.
[0058] Spark runs programs faster than Hadoop MapReduce in memory and ondisk.
[0059] Block2:
[0060] Spark performance is impacted by many soft system, hardware and dataset factors.
[0061] Spark can run both by itself, or over several existing cluster managers.
[0062] Block3:
[0063] Big Data can be defined as large data sets are being generated from different sources.
[0064] The use of the MapReduce and Spark are two approaches perform data analytics. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com