

Method and device for improving Spark operation efficiency
An efficiency and process technology, applied in the field of big data analysis and processing, can solve problems such as insufficient use of data, consumption of network IO, serial submission of tasks, or insufficient parallelism, so as to improve operating efficiency and increase parallelism Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0056] The preferred embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. It should be understood that the preferred embodiments described below are only used to illustrate and explain the present invention, and are not intended to limit the present invention.
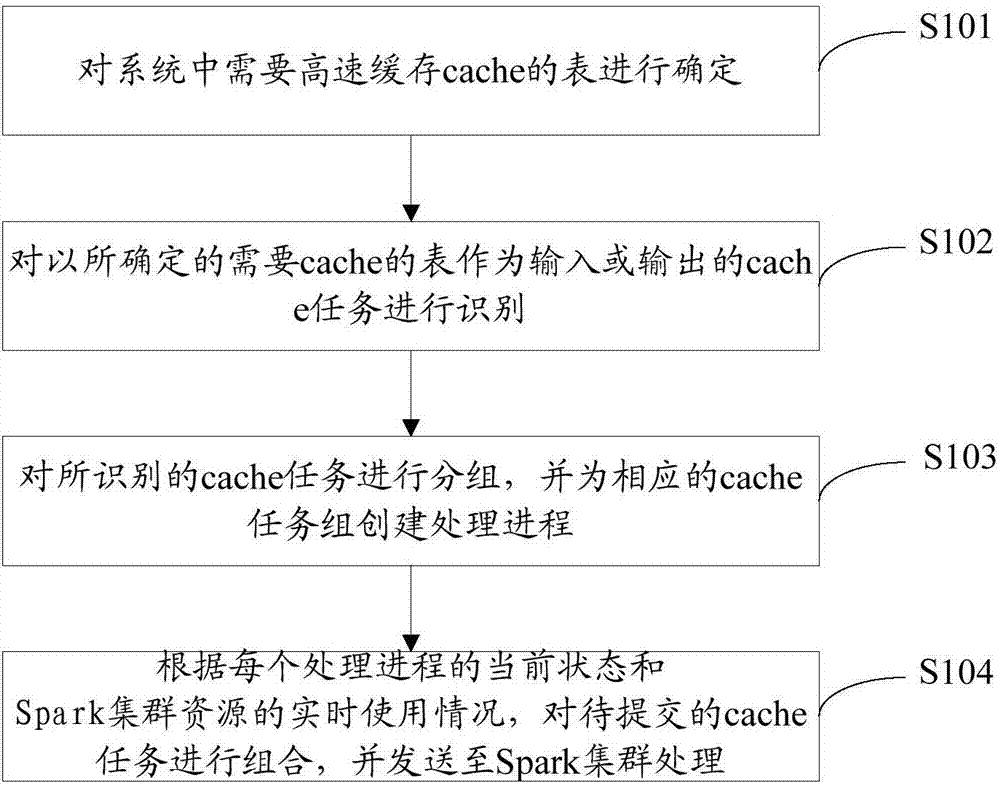
[0057] figure 1 is a block diagram of a method for improving Spark performance provided by an embodiment of the present invention, such as figure 1 As shown, the steps include:
[0058] Step S101: Determine the tables that need to be cached in the system.
[0059] Determine the table that needs to be cached according to the out-degree of the table, the number of records in the table cache, and the ready time difference between multiple cache tasks in the table; and / or determine the table of the custom cache type as the table that needs to be cached.
[0060] Step S102: Identify the cache task that takes the determined table that needs to be cached (refe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More