

Method for memory estimation and configuration optimization in distributed data processing system
一种分布式数据、配置优化的技术,应用在电数字数据处理、资源分配、多道程序装置等方向,能够解决算子数量少、内存预估应用局限性等问题,达到通用性强的效果
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
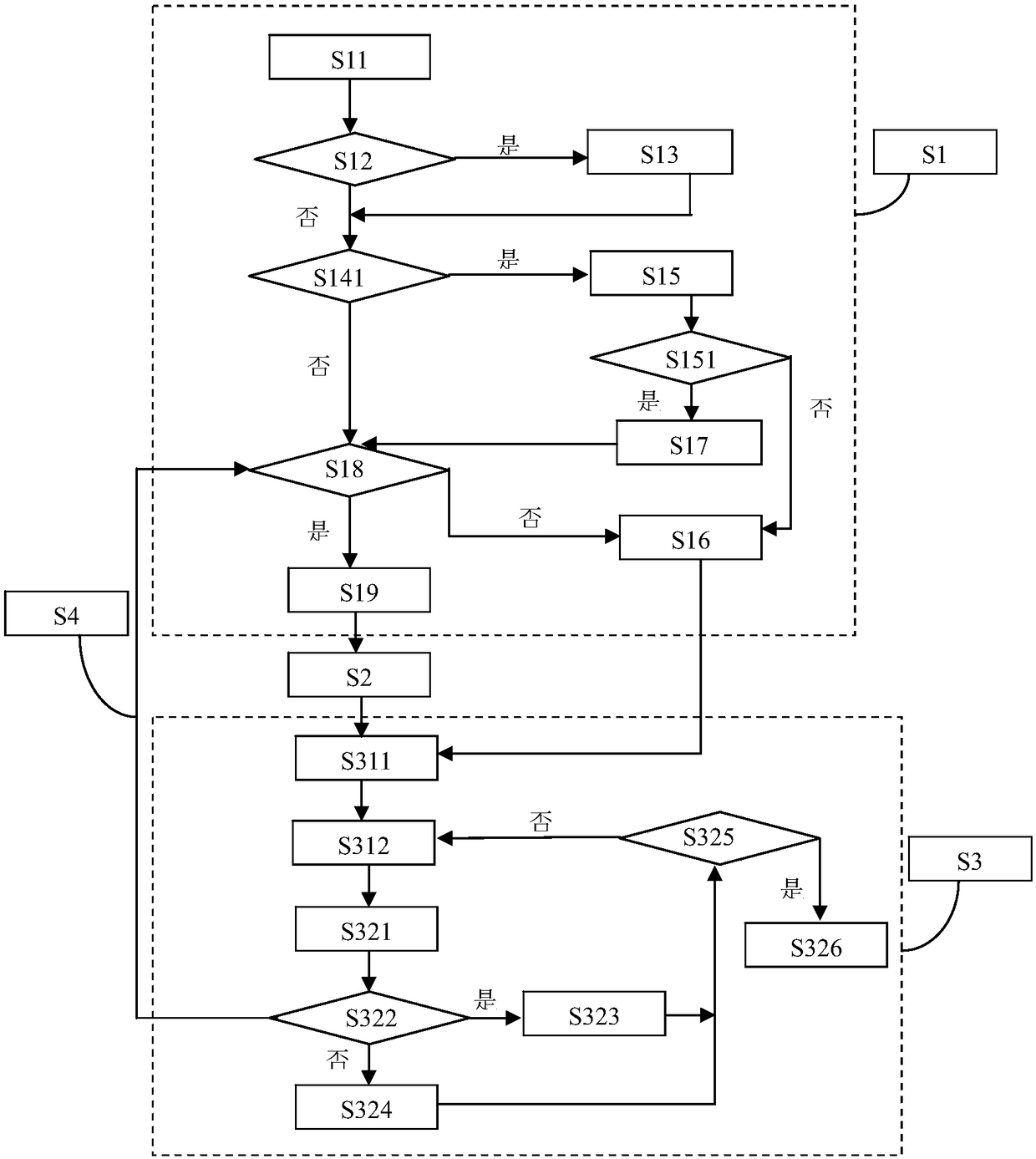
[0044] This embodiment provides a method for memory estimation and configuration optimization in a distributed data processing system. A method for memory estimation and configuration optimization in a distributed data processing system at least includes:
[0045] S1: Match the data program flow that has been analyzed and processed for the conditional branch and / or loop body of the program code in the application jar package with the data feature library and estimate the memory upper limit of at least one stage based on the successful matching result,
[0046] S2: optimize the configuration parameters of the application program,
[0047] S3: Collect the static and / or dynamic features of the program data during the running process of the optimized application and make persistent records.
Embodiment approach
[0048] According to a preferred embodiment, the method also includes:
[0049] S4: Estimate the memory upper limit of at least one stage again based on the feedback results of the static features and / or dynamic features of the program data and optimize the configuration parameters of the application program.
[0050] The present invention can solve the defects of the existing memory estimation for specific application limitations: because the present invention adopts the data feature collection strategy, based on the small number of Spark operators, the data is formed in the memory through the processing operations of each operator Data change flow, each change can be regarded as a dynamic feature of the data. These dynamic characteristics can be shared by the next new application submission, that is, the data changes in the new application can become predictable. Moreover, the more historical applications submitted on the same data, the more dynamic characteristics of the da...
Embodiment 2
[0083] This embodiment is a further improvement on Embodiment 1, and repeated content will not be repeated here.
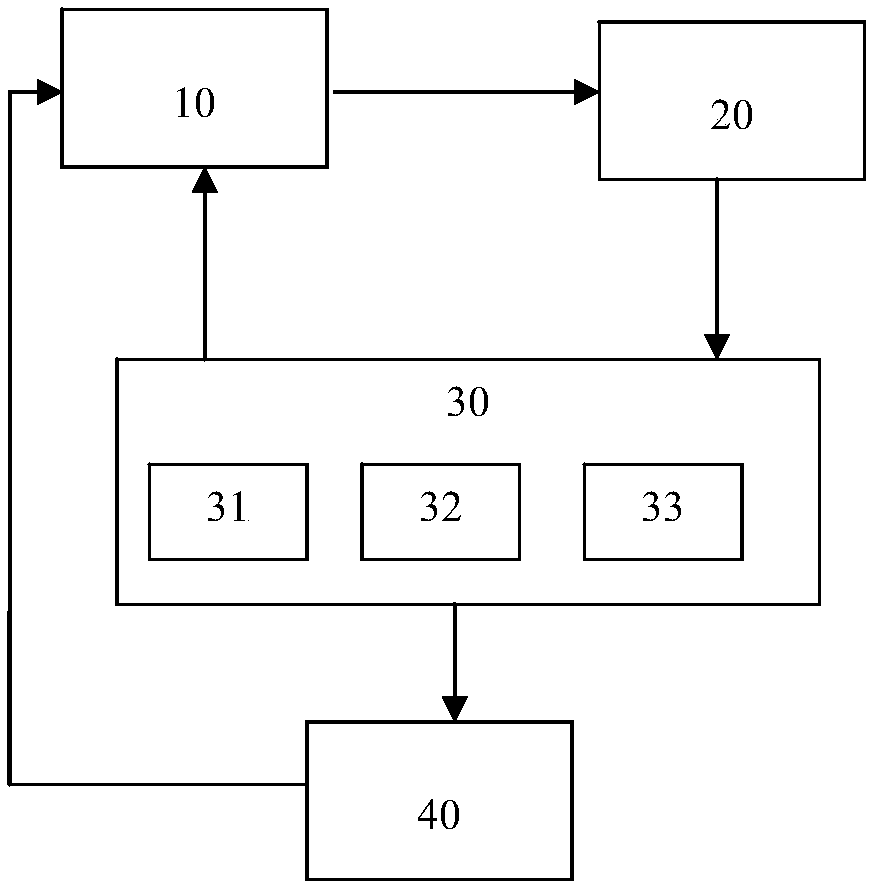
[0084] The present invention also provides a memory estimation and configuration optimization system in a distributed data processing system, such as figure 2 shown.
[0085] The memory estimation and configuration optimization system of the present invention at least includes a memory estimation module 10 , a configuration optimization module 20 and a data characteristic collection module 30 .
[0086] The memory estimation module 10 matches the data program flow analyzed and processed by the conditional branch and / or loop body of the program code in the application jar package with the data feature library stored in the data feature recording module, and based on the successful matching result Estimate the memory limit for at least one stage. Preferably, the memory estimation module 10 includes one or more of an ASIC, a CPU, a microprocessor, a server, and a ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More