

Industrial process data clustering method for density peak clustering
An industrial process and density peak technology, which is applied in the direction of instruments, calculations, character and pattern recognition, etc., can solve the problems that the number of cluster centers cannot be automatically determined, the optimal cluster center cannot be determined, and the accuracy of cluster results is low. , to achieve good applicability, reduce the amount of calculation, and achieve the effect of high classification accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
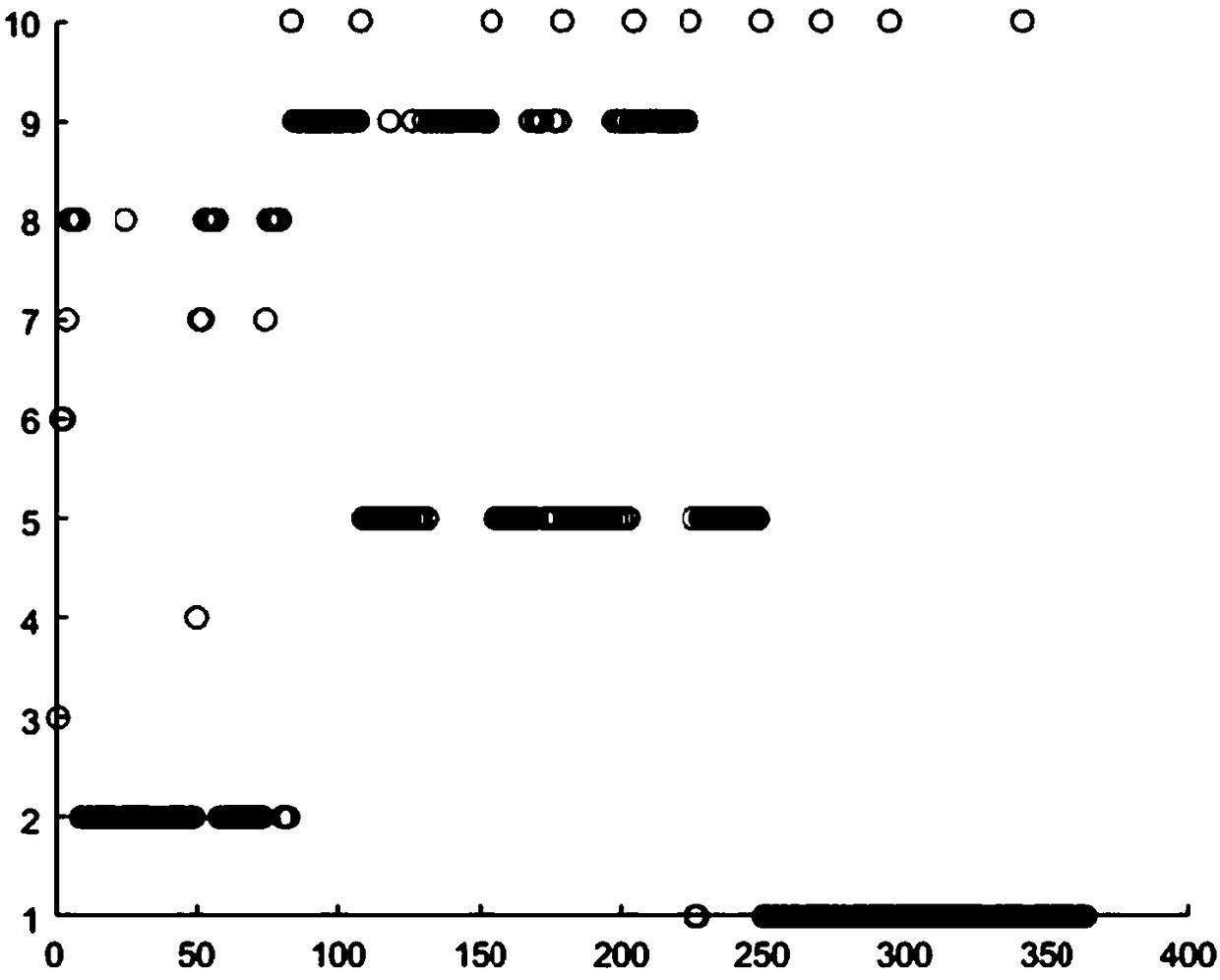
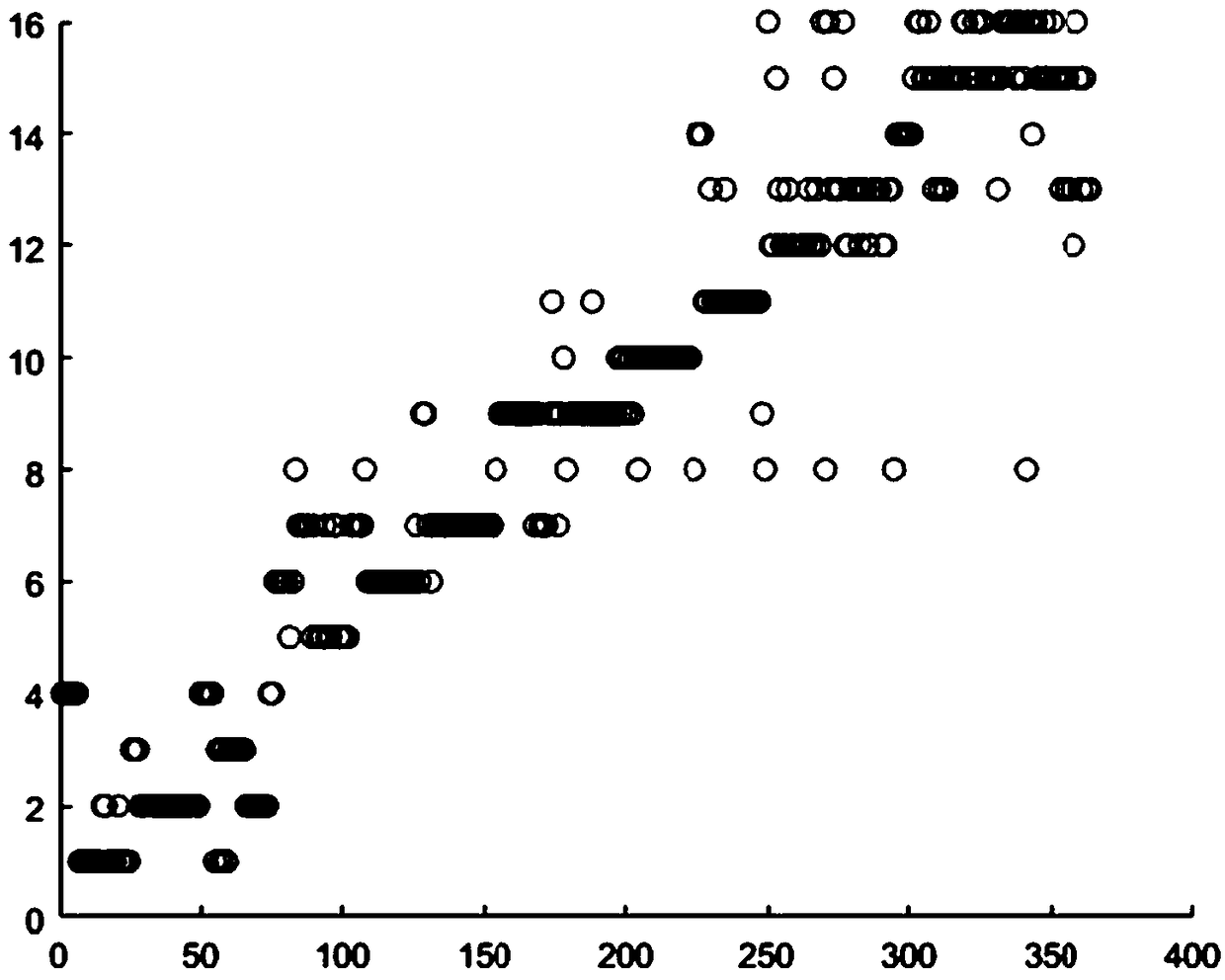
[0053] Embodiment 1 adopts the industrial process data clustering method based on the improved Density Peaks Clustering (DPC: Density Peaks Clustering) provided by the present invention, and verifies through the industrial process of semiconductors. Table 1 shows 16 different modalities and Correspondence table for industrial process data.
[0054] Table 1
[0055] modal
Data points corresponding to the modality
1
1-24
2
25-49
3
50-73
4
74-82
5
83-107
6
108-132
7
133-153
8
154-178
9
179-203
10
204-223
11
224-248
12
249-269
13
270-294
14
295-318
15
319-340
16
341-364
[0056] The verification data used in Embodiment 1 of the present invention comes from the data of the semiconductor industry process, and the modern semiconductor production line is composed of hundreds of continuous batch processing stages. Each stage ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More