

Large-scale document similarity detection method
A detection method and similarity technology, applied in the field of computer algorithms, can solve problems such as insufficient accuracy and low efficiency, and achieve the effects of high accuracy, high execution efficiency, and improved execution efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

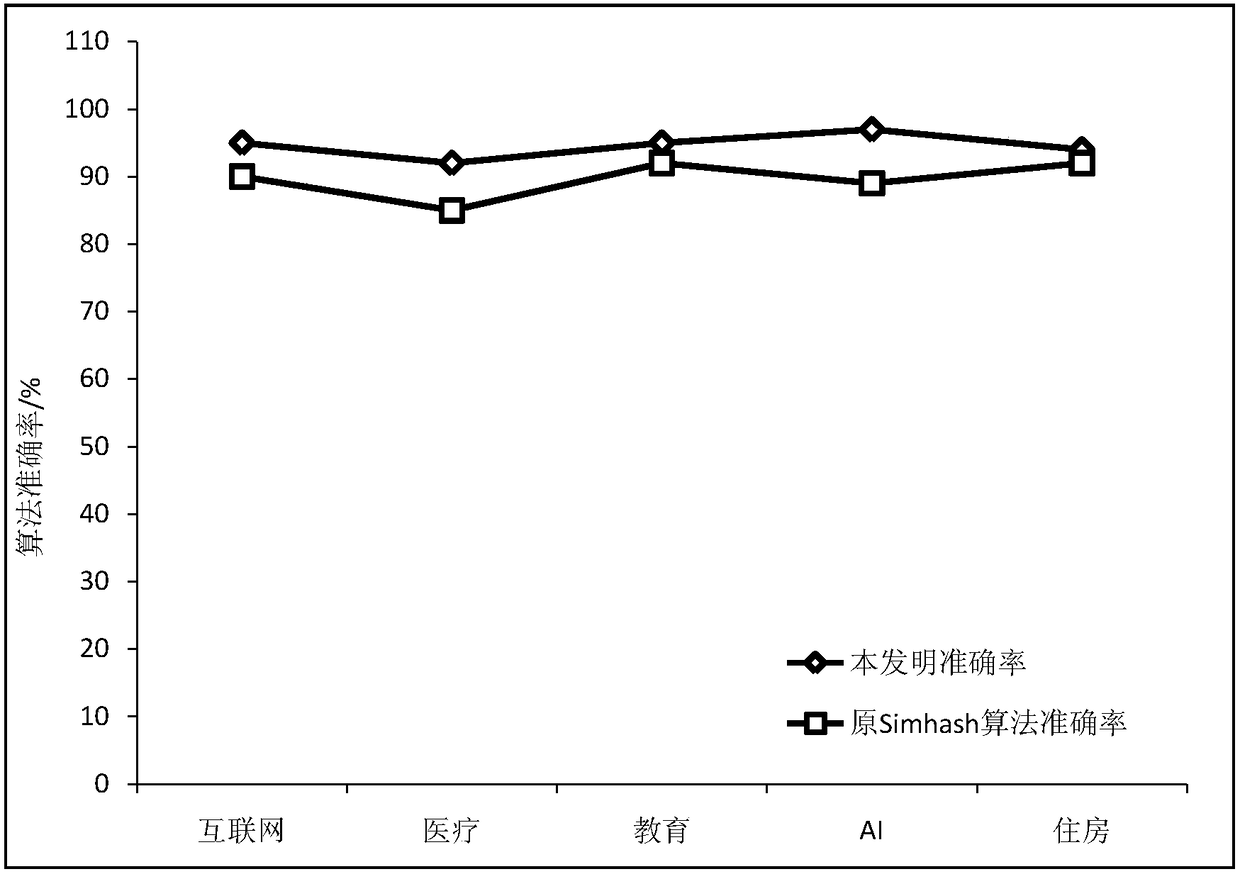
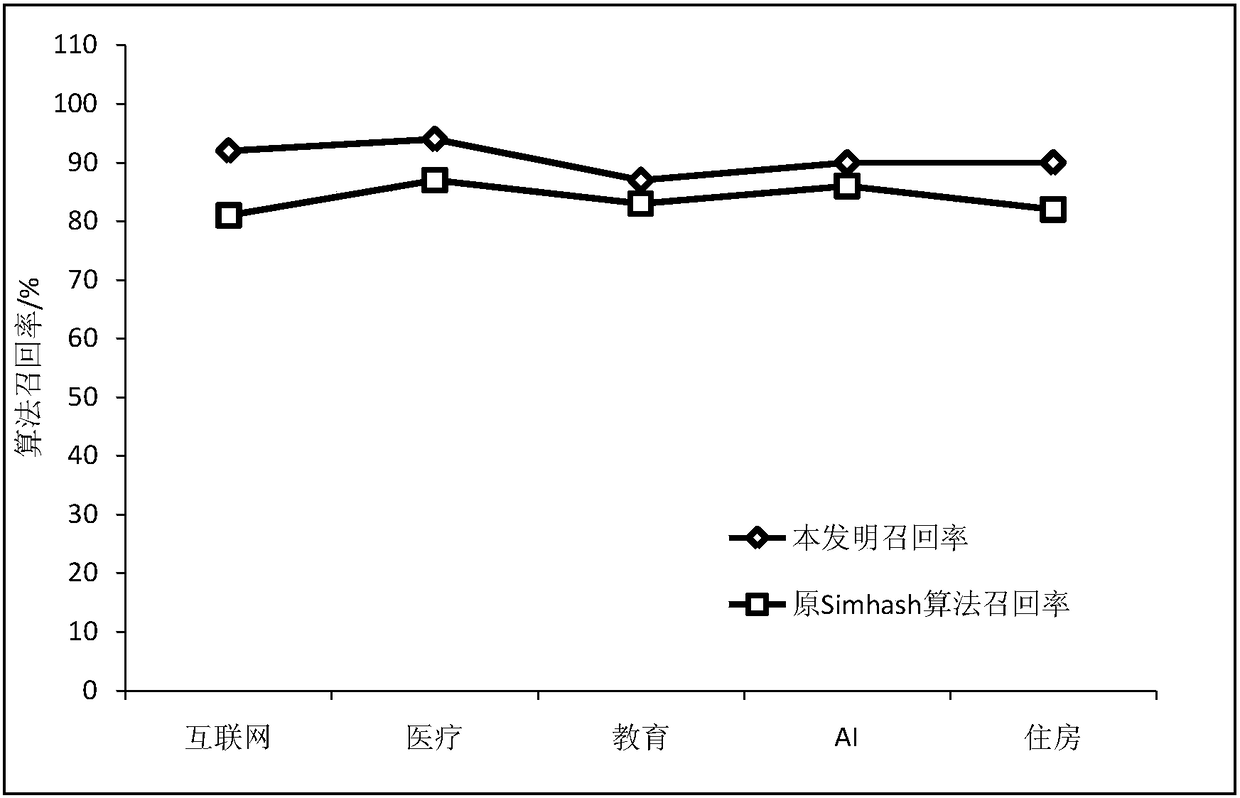
Examples
Embodiment Construction
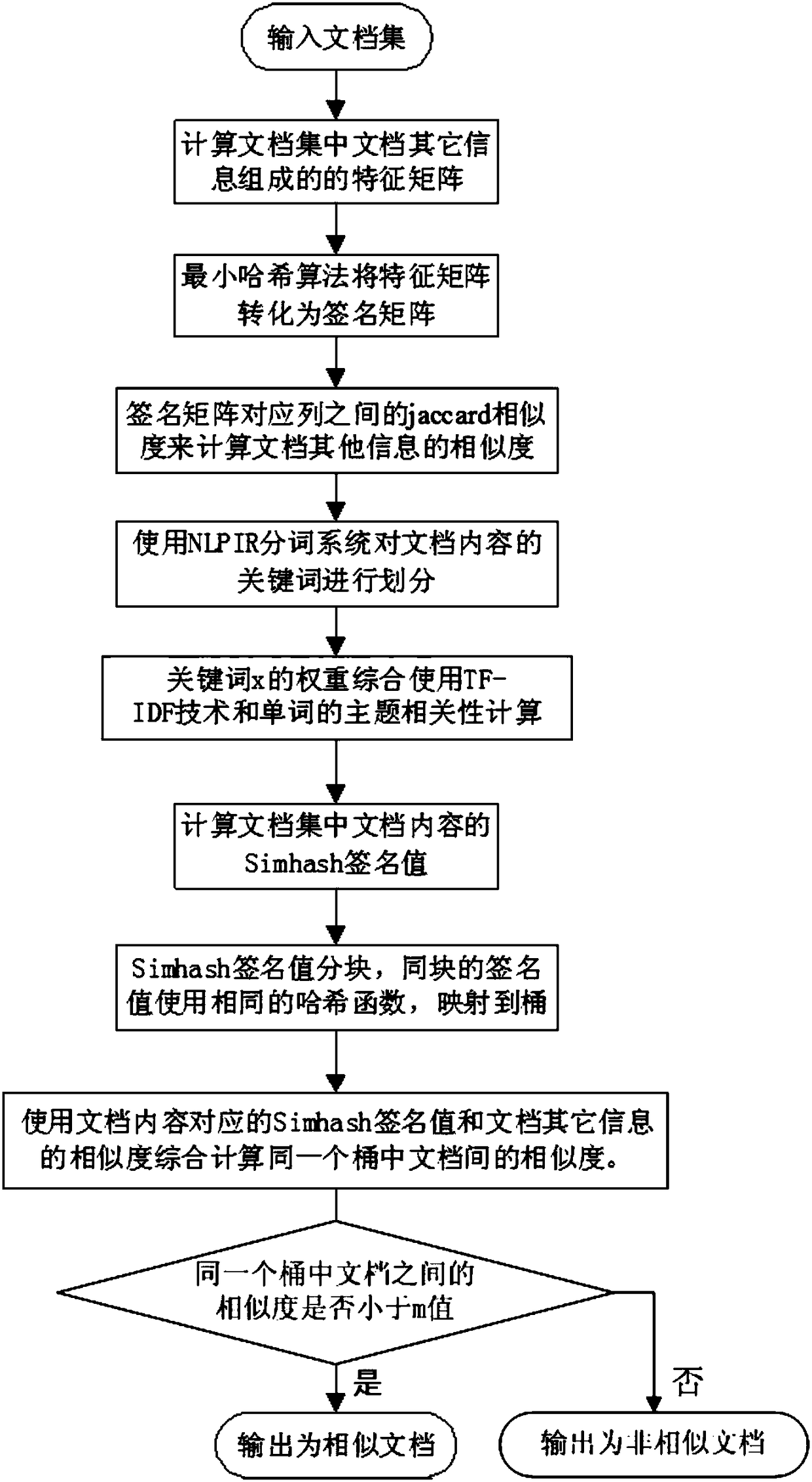
[0039] In order to describe in more detail the load balancing method executed between the service nodes of the server cluster proposed by the present invention. to combine figure 1 , as detailed below.
[0040] A large-scale document similarity detection method, comprising the following steps:
[0041] S1. Input a document set, and calculate the similarity of other information of the documents in the document set.
[0042] S2. The content of each document in the document set corresponds to a signature S initialized to 0 and a length of f, and an f-dimensional vector V initialized to 0.
[0043] S3. Use the NLPIR word segmentation system to perform word segmentation processing on the document content, filter out modal particles and auxiliary words, and remove interference symbols to convert the document content into a set of feature words.
[0044] S4. The weight of the feature word x uses TF-IDF technology and the topic correlation calculation of words comprehensively, and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More