

Audio data generating method and system for voice synthesis
A technology for audio data and speech synthesis, applied in speech synthesis, speech analysis, instruments, etc., can solve problems such as compression, reduce computing delay, improve speed, and ensure the accuracy of acoustic feature prediction.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] In order to make the object, technical solution and advantages of the present invention clearer, the embodiments of the present invention will be further described in detail below in conjunction with the accompanying drawings.
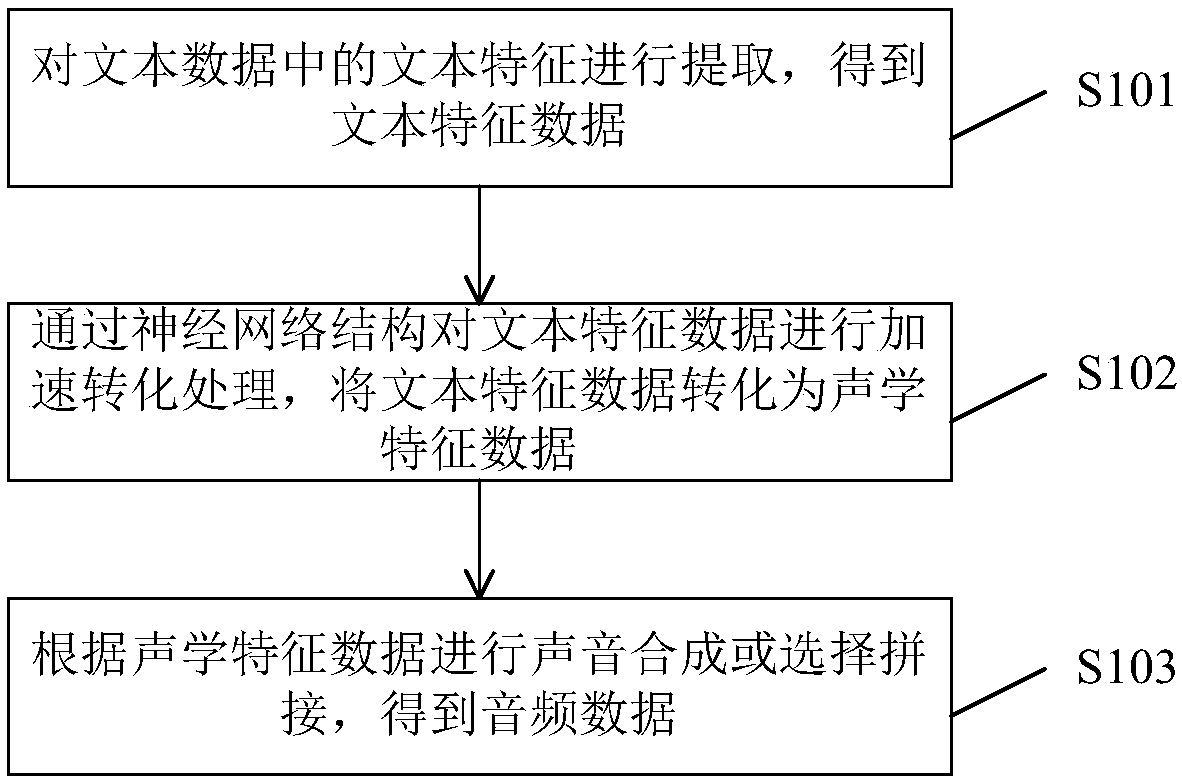
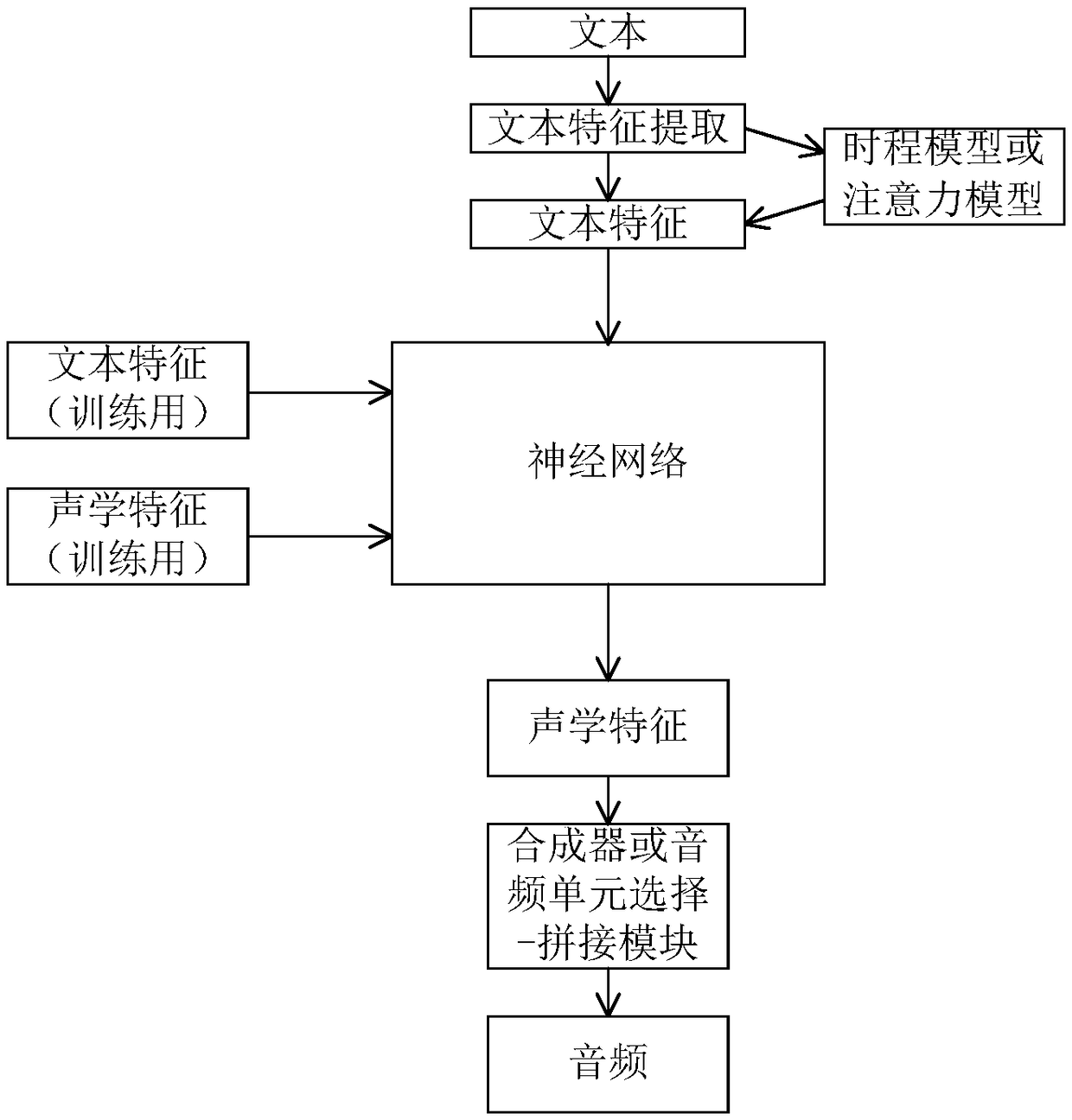
[0036] figure 1 A flowchart of a method for generating audio data for speech synthesis according to an embodiment of the present invention is shown.
[0037] Such as figure 1 As shown, in step S101, text features in the text data are extracted to obtain text feature data. In one embodiment of the present invention, the text features include: one or a combination of phonetic symbols, intonation, sentence sentence or prosodic marking, syntactic dependency tree, participle marking, part-of-speech tagging, semantic weight and word vector.
[0038] In addition, the manner of obtaining the text feature data may be a natural language processing algorithm (NLP, Natural Language Processing). Natural language processing algorithms can perform word segm...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More