

A bilingual word embedding-based cross-language text similarity assessment technique
A text similarity and cross-language technology, applied in natural language data processing, semantic analysis, instrumentation, etc., can solve problems such as difficult multi-task, multi-label specification, multi-language learning, and inability to fully express semantic associations
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0041] The main processing procedure of the present invention will be described in more detail below in conjunction with the accompanying drawings.
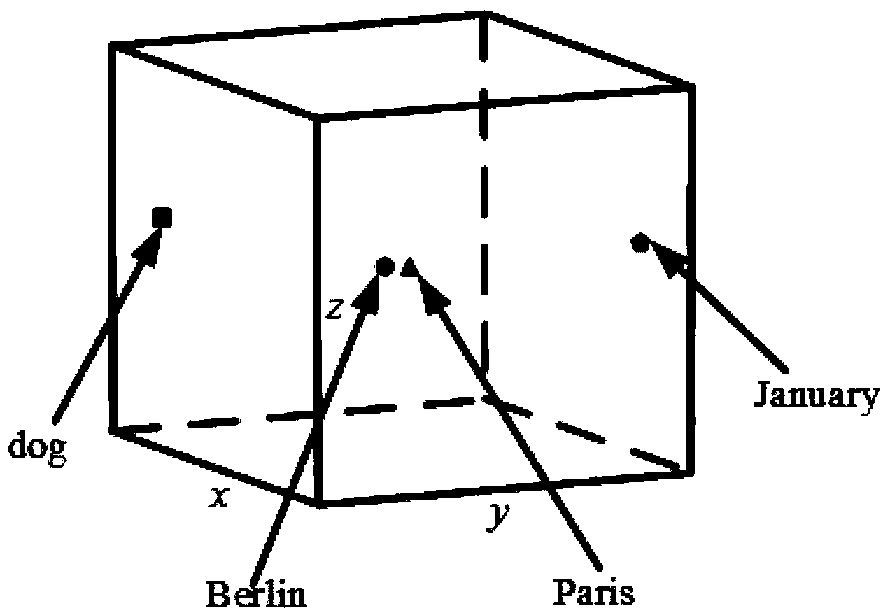
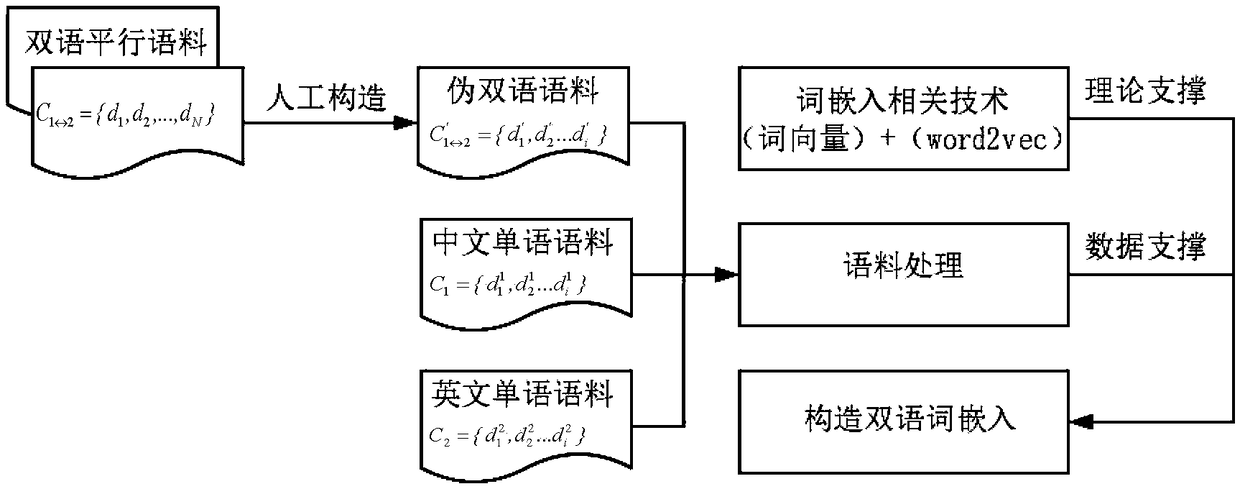
[0042] The invention describes a cross-language text similarity evaluation technology based on bilingual word embedding. Use natural language processing technology to perform preprocessing operations such as word segmentation and de-staying words on the text, and use words as text units to learn word vector representations and build bilingual word embedding models. Through this model, word embedding representations shared by bilinguals can be generated, and the spatial distance between words can be used to measure the semantic similarity between them. Based on word vector correlation theory and Skip-Gram model, word vector training is carried out on artificially constructed pseudo-bilingual corpus. Second, in order to make the generated word embedding space as complete as possible, a monolingual corpus is also used as a suppleme...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More