[0002] In recent years, although there have been few reports of errors in
clinical diagnosis and treatment, any form of
medical diagnosis cannot completely avoid misdiagnosis even with the assistance of the most advanced equipment. Therefore, one of the goals of clinical diagnosis research is to explore the occurrence of misdiagnosis. Laws and preventive measures to reduce the probability of misdiagnosis and increase the rate of diagnosis, thereby promoting the development of the medical field
At present, due to the limitation of medical resources in China, in the
medical consultation environment, the attending doctor has no way to accurately and comprehensively understand the symptoms and signs of each patient during the consultation. Therefore, a set of evidence-based medical auxiliary diagnosis
system is developed to improve It is of great value to improve the diagnosis and
treatment level of doctors, improve the medical awareness of patients, and optimize the pre-hospital services of both doctors and patients.
At present, some
medical diagnosis, guidance, case
quality control and other systems on the market are based on the analysis of electronic medical records, and extract the patient's chief complaint, history of present illness, examination, family history and other
data information vectorization, and based on the above vectors, the disease forecasting, and the forecasting methods are mainly divided into two types, namely writing artificial forecasting rules and using conventional
machine learning models, such as naive ES and
logistic regression, and there are more or less shortcomings in the above technologies, for example, from Vectorized information such as patient complaints, current
medical history, examinations, and symptoms extracted from family history has up to tens of thousands of dimensions, and due to the limitation of vector length, existing methods have adopted different selection methods, which cannot make good use of this information make accurate judgments
[0003] First of all, from the artificial rules of the existing technology, it is necessary to manually specify the association rules between the information vector and the disease, and also extract the main influencing factors of each disease, but the weight of these influencing factors depends on the subjective judgment of the person who made the judgment. The results may not be accurate and cannot reflect the actual situation of the patient well. The dimensions of information such as the symptoms of the patient increase. Thousands of kinds, when sorting the probability of diseases, the manual rules are too one-sided and cannot take into account the overall situation. Not only that, but the efficiency of sorting the rules by manual rules is also extremely low
Secondly, from the perspective of existing
machine learning models, there are mainly the following problems. First, conventional models have limited application condition assumptions and limited learning capabilities, and the application cannot achieve sufficient accuracy; for example , Naive Bayes assumes that there is no correlation between input features, and it is unrealistic to assume that there is no correlation between symptoms, inspections, etc., so the result of the model also loses precision; the second point, generalized
linearity such as
logistic regression The model retains the assumption of correlation between symptoms, but is limited by the learning ability of the model. The interaction between features needs to be manually specified by the user of the model. In the feature space of tens of thousands of dimensions, meaningful interaction needs to be found. A lot of labor is difficult to achieve in practice; the third point is that the learning efficiency of the model is low
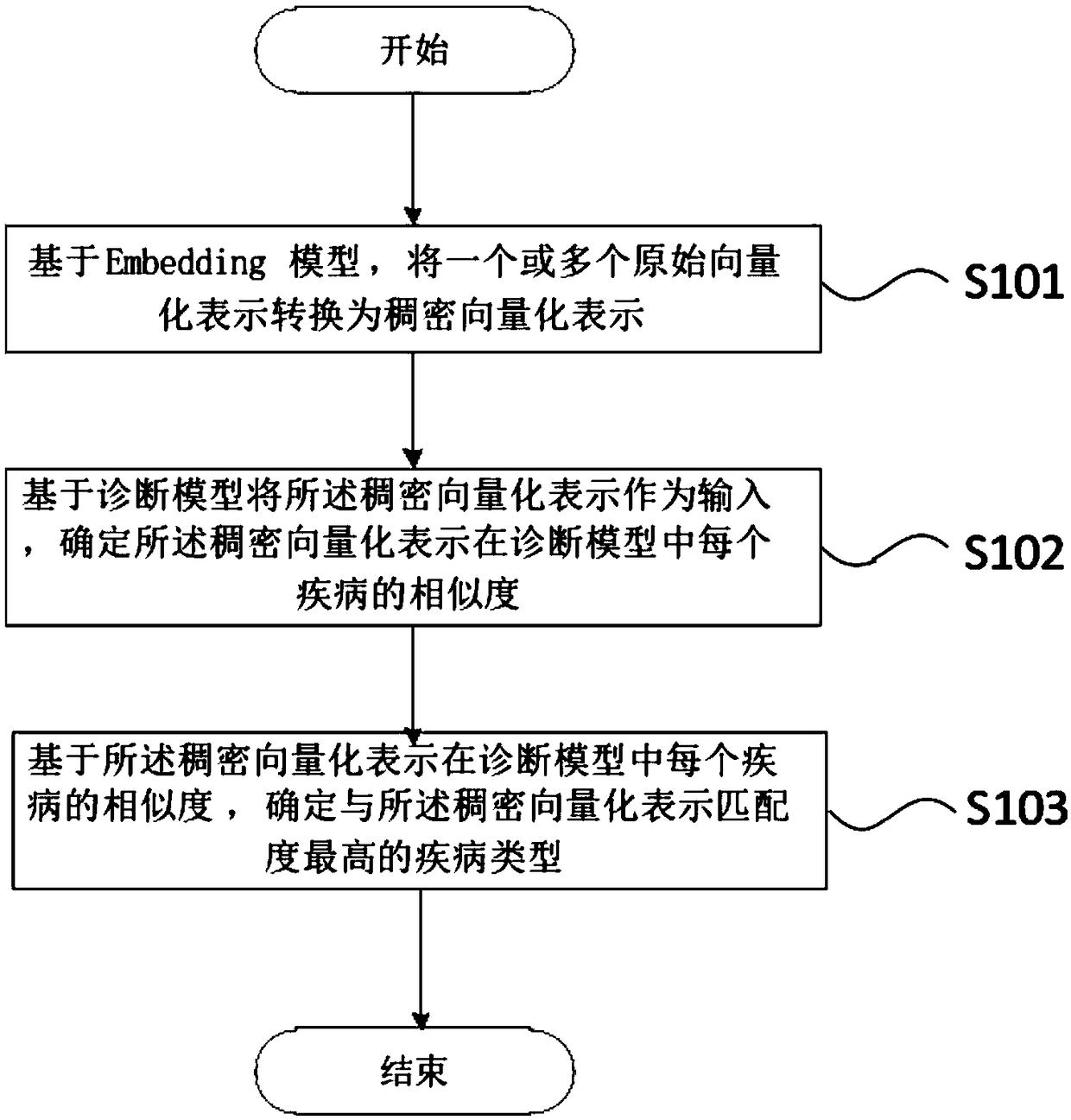
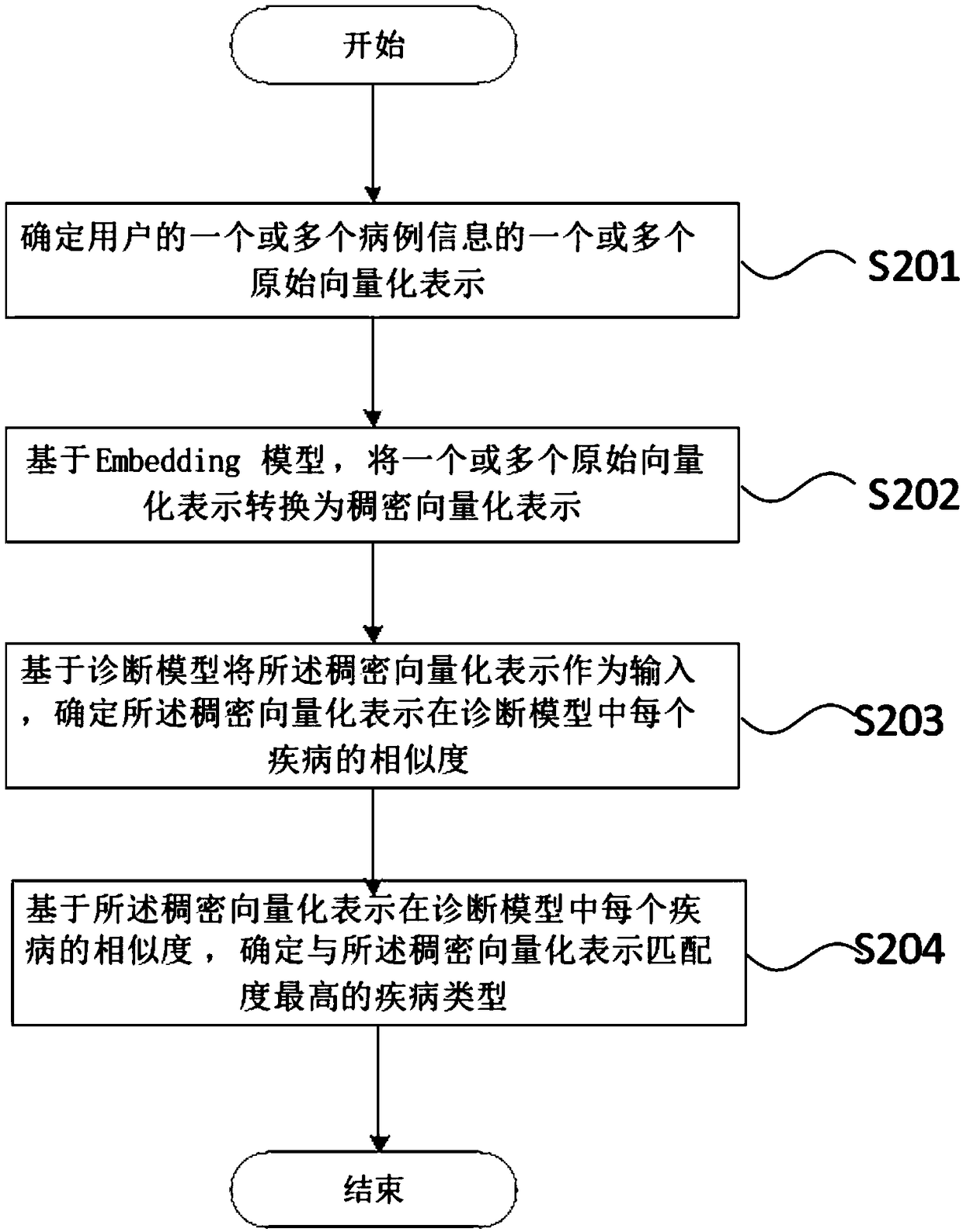
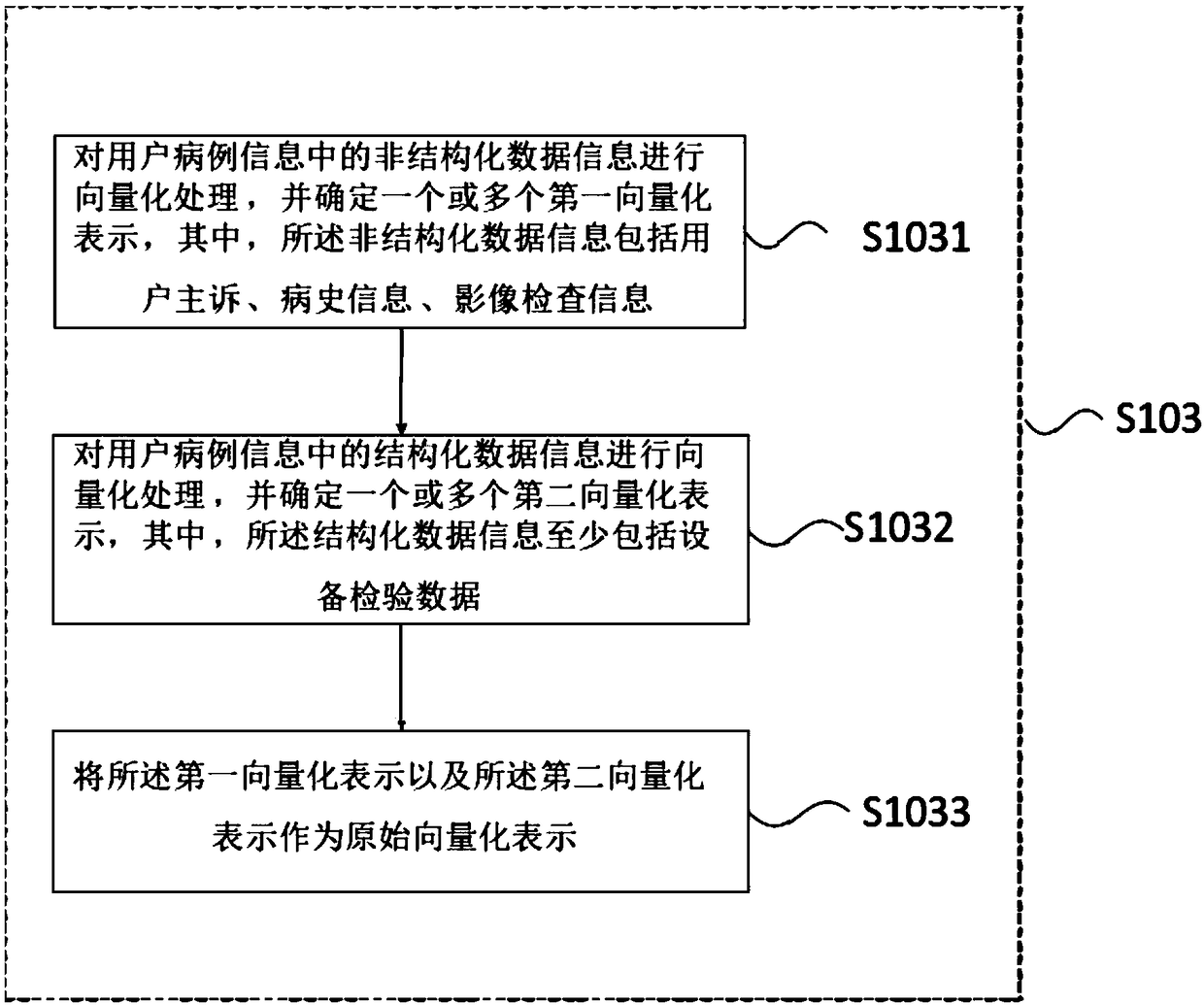
[0004] At present, there is no specific method on the market that can effectively solve the above problems, especially a control method and control device for disease prediction based on eigenvectors.



 Login to View More
Login to View More  Login to View More
Login to View More