

Audio scene recognition method and system combining deep neural network and topic model
A deep neural network and topic model technology, applied in biological neural network models, neural learning methods, character and pattern recognition, etc., to avoid processing problems, improve analysis accuracy, and improve classification and recognition capabilities.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
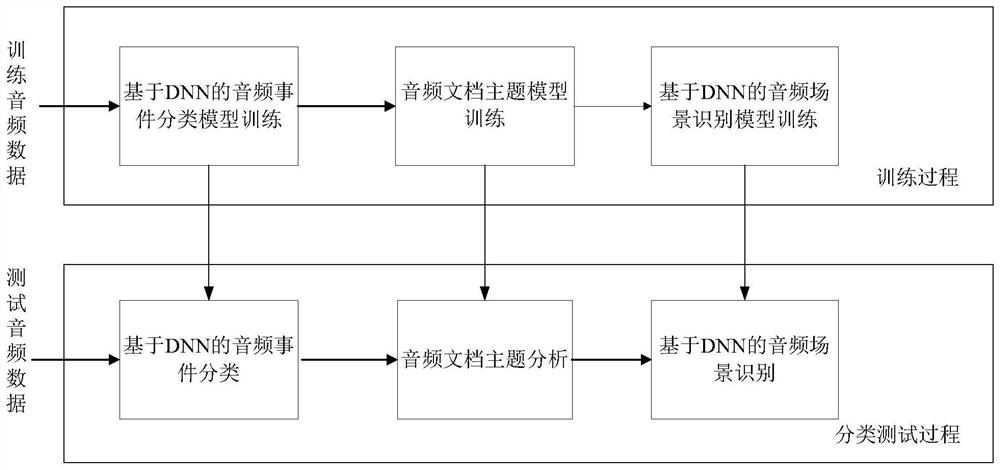
[0097] Embodiment 1: as figure 1 As shown, the audio scene recognition method proposed by the present invention is mainly divided into two modules: a training process and a classification test process. Among them, the training process includes DNN-based audio event classification model training, audio document topic model training, and DNN-based audio scene recognition model training. The classification test process includes DNN-based audio event classification, audio document topic analysis, and DNN-based audio scene recognition. Each part will be introduced in detail below.
[0098] First introduce the training process:
[0099] (1) DNN-based audio event classification model training
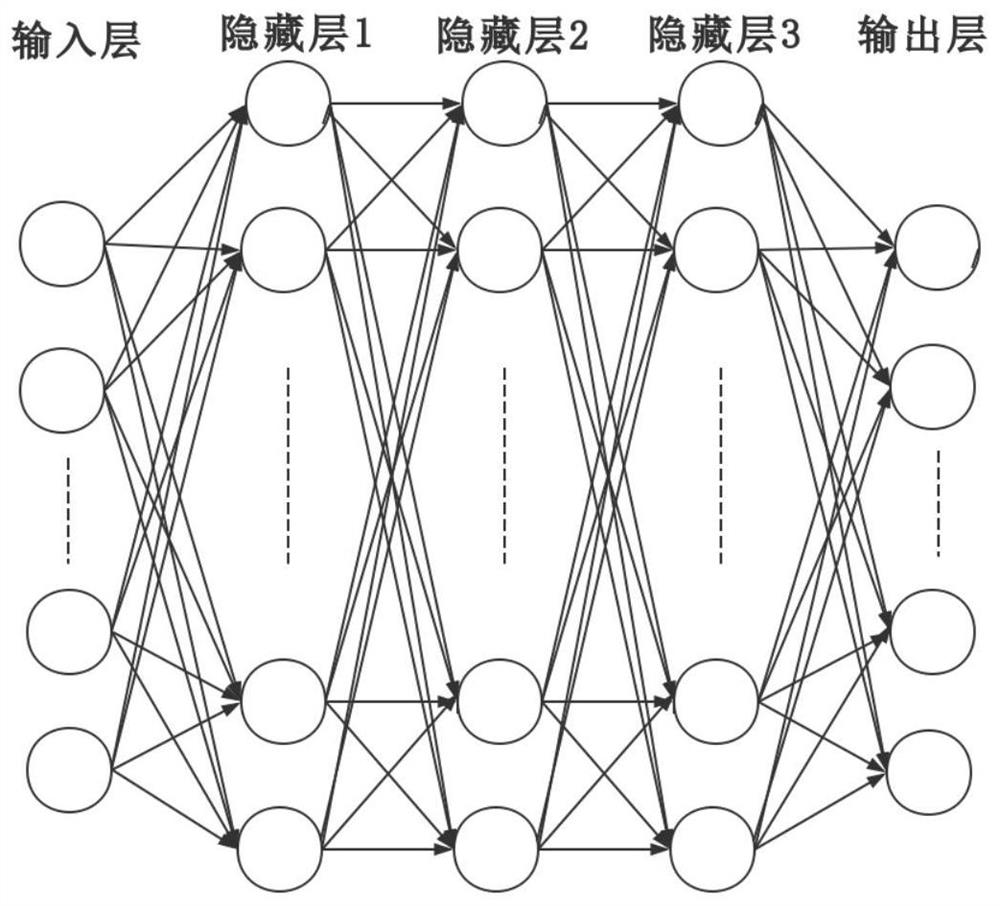
[0100]The training data in the training set consists of two parts: audio clips of audio events, and audio scene documents. The DNN-based audio event classification model is trained with audio clips of clean audio events. First, the audio clip of the pure audio event is divided into frames...
Embodiment 2
[0115] Embodiment 2: the present disclosure also provides an audio scene recognition system combining a deep neural network and a topic model;
[0116] An audio scene recognition system combining deep neural networks and topic models, including:
[0117] The audio event classification model training module uses training audio event fragments to train an audio event classification model based on a deep neural network;
[0118] The characterization vector extraction module of the training audio scene document inputs the training audio scene document into the trained audio event classification model based on the deep neural network, and outputs the characterization vector of the training audio scene document;
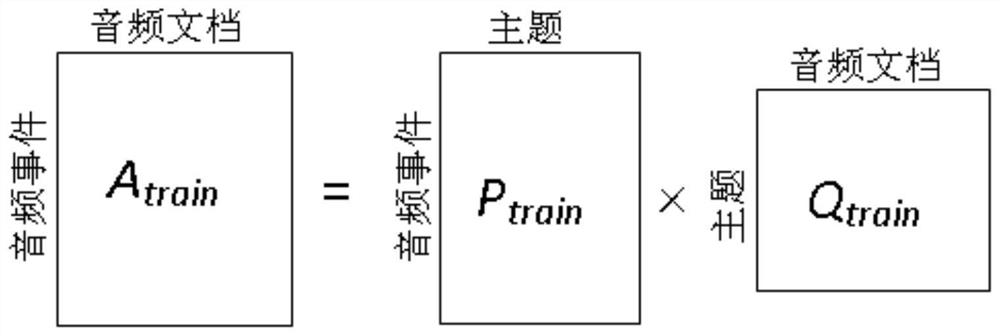
[0119] The topic distribution vector extraction module of the training audio scene document uses the representation vector of the training audio scene document to train the topic model, and outputs the topic distribution vector of the audio scene document after training; ...
Embodiment 3
[0124] Embodiment 3: The present disclosure also provides an electronic device, including a memory, a processor, and computer instructions stored in the memory and run on the processor. When the computer instructions are executed by the processor, each operation in the method is completed , for the sake of brevity, it is not repeated here.
[0125] It should be understood that in the present disclosure, the processor may be a central processing unit CPU, and the processor may also be other general-purpose processors, digital signal processors DSP, application-specific integrated circuits ASICs, off-the-shelf programmable gate arrays FPGAs, or other available Program logic devices, discrete gate or transistor logic devices, discrete hardware components, and more. A general-purpose processor may be a microprocessor, or the processor may be any conventional processor, or the like.
[0126] The memory may include read-only memory and random access memory, and provide instructions...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More