

Foot type robot motion control method and system based on deep reinforcement learning
A technology of robot motion and reinforcement learning, applied in the direction of program control manipulators, manipulators, manufacturing tools, etc., can solve problems such as difficulty in handling high-dimensional objects, complex design process, limited adaptability to model uncertainty and environmental unknowns, etc. Achieve the effect of reducing workload and moving smoothly and quickly
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

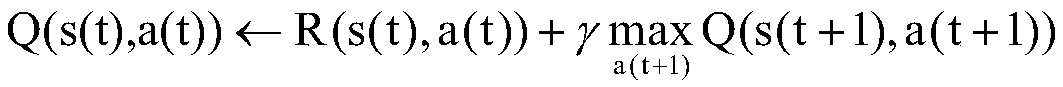
Examples
Embodiment Construction
[0020] Exemplary embodiments of the present disclosure will be described in more detail below with reference to the accompanying drawings. Although exemplary embodiments of the present disclosure are shown in the drawings, it should be understood that the present disclosure may be embodied in various forms and should not be limited by the embodiments set forth herein. Rather, these embodiments are provided for more thorough understanding of the present disclosure and to fully convey the scope of the present disclosure to those skilled in the art. It should be noted that, in the case of no conflict, the embodiments of the present invention and the features in the embodiments can be combined with each other. The present invention will be described in detail below with reference to the accompanying drawings and examples.
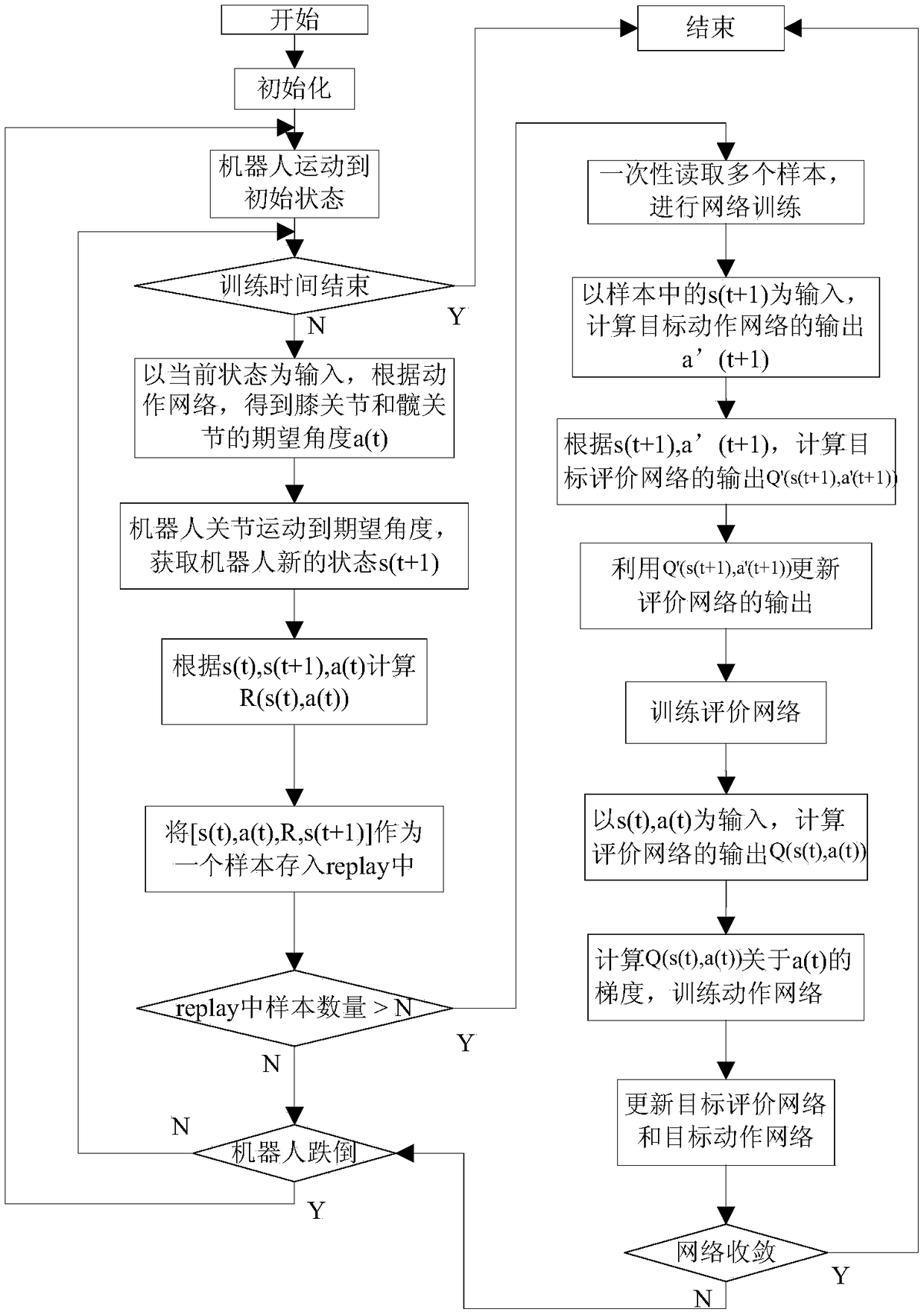
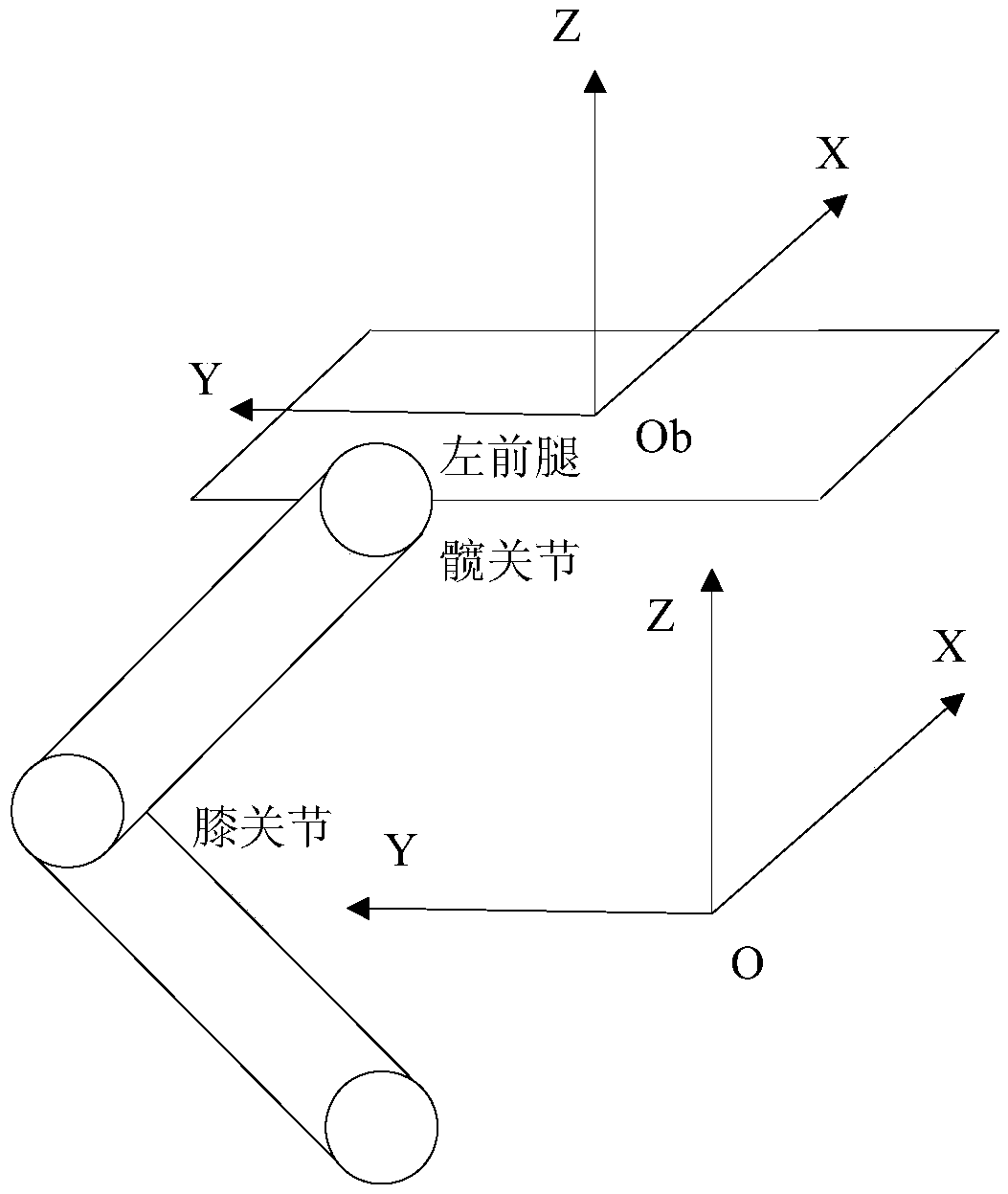
[0021] figure 1 It is a flow chart of the motion control method of a legged robot based on deep reinforcement learning provided by an embodiment of the prese...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More