

A Spark cluster parallel computing-based traffic jam point discovery method
A technology of traffic congestion and method discovery, applied in computing, computer components, execution paradigms, etc., can solve problems such as easy to fall into local optimal solutions, low precision, and high time complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0091] The specific embodiments of the present invention will be further described below in conjunction with the accompanying drawings, but the present invention is not limited.
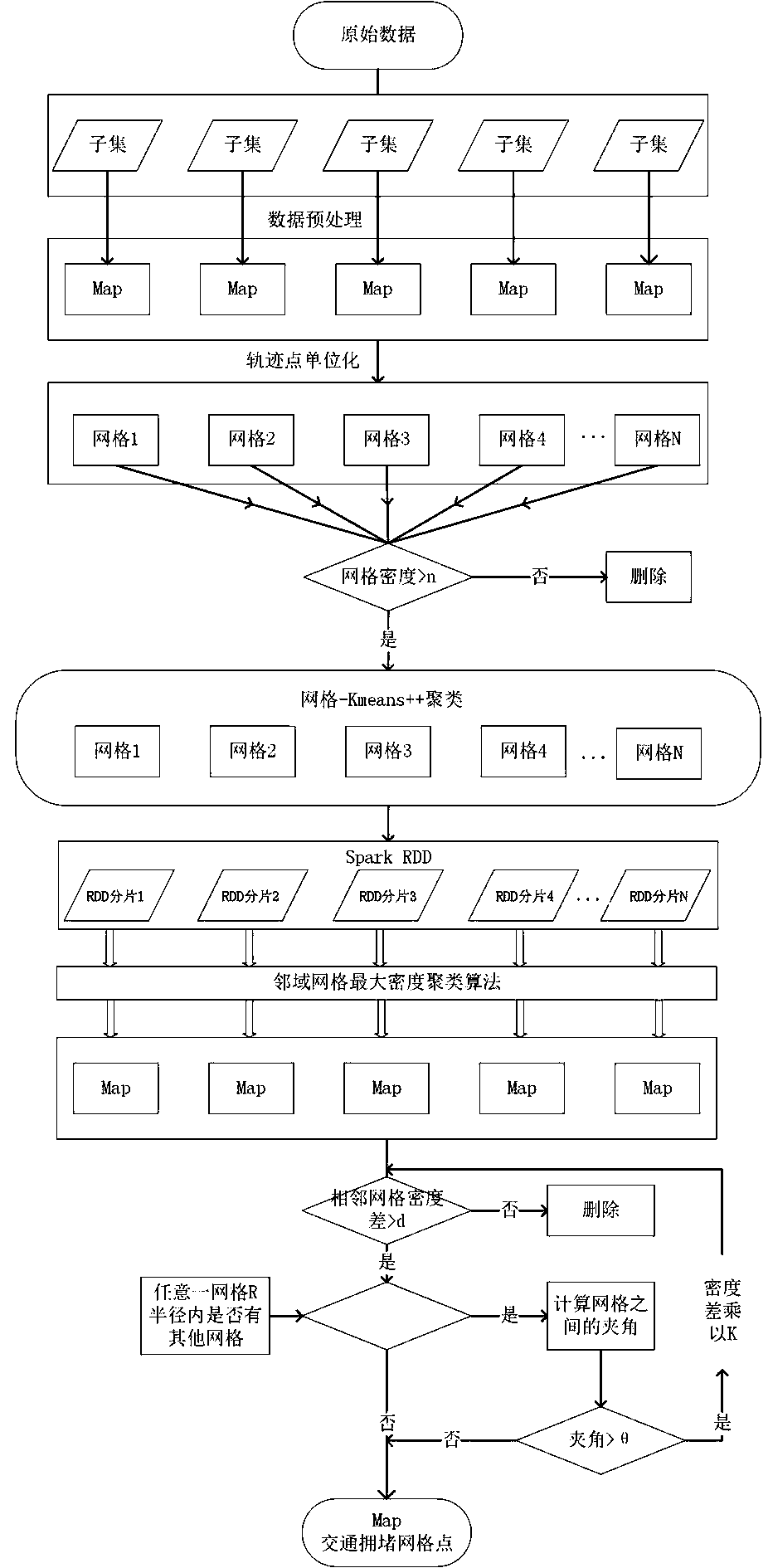
[0092] figure 1 A method for discovering traffic congestion points based on spark cluster parallel computing is shown, including the following steps:
[0093] (1) The preprocessing of massive data, including complementing the error between track points and the redundancy of track points within a period of time in the region, the specific process is as follows:
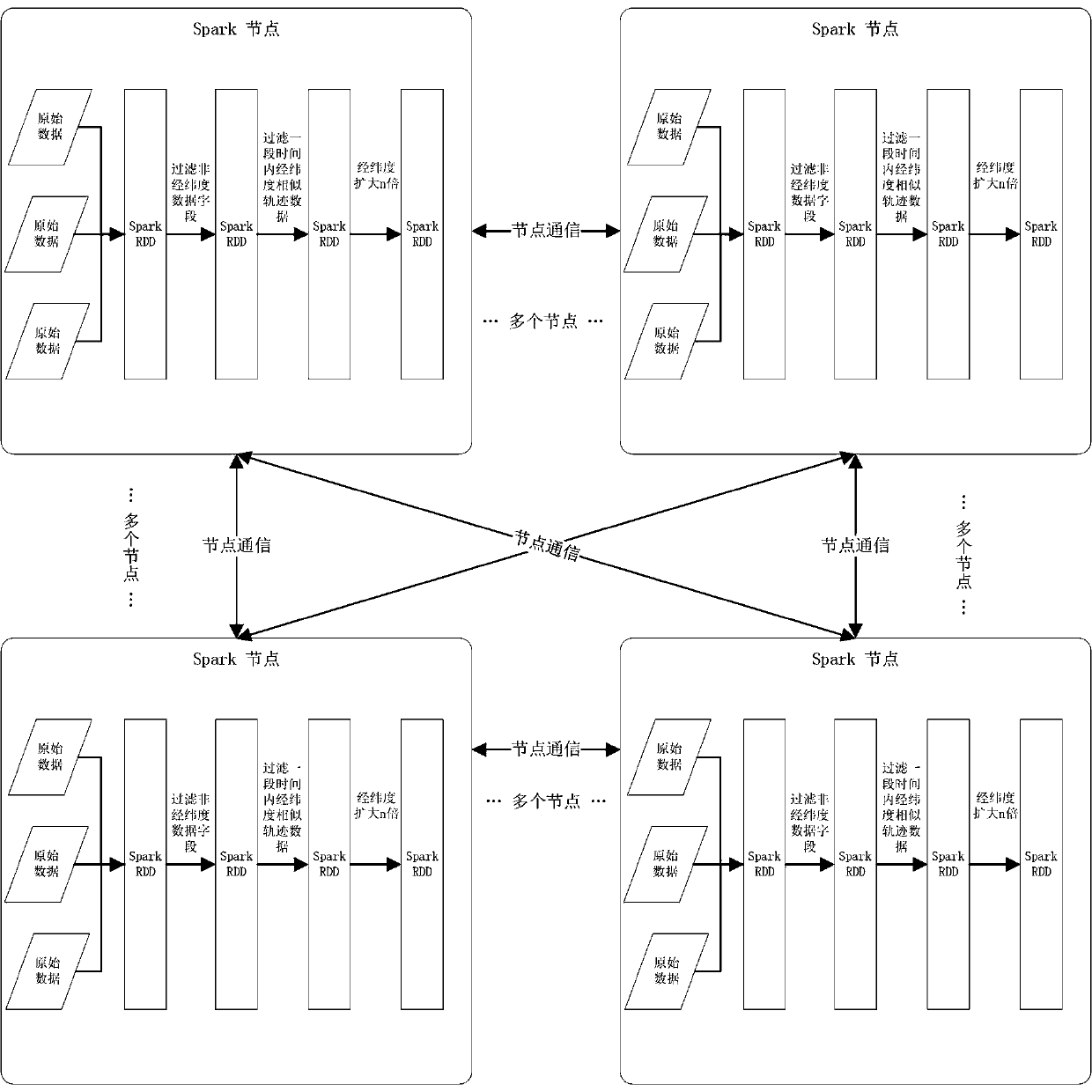
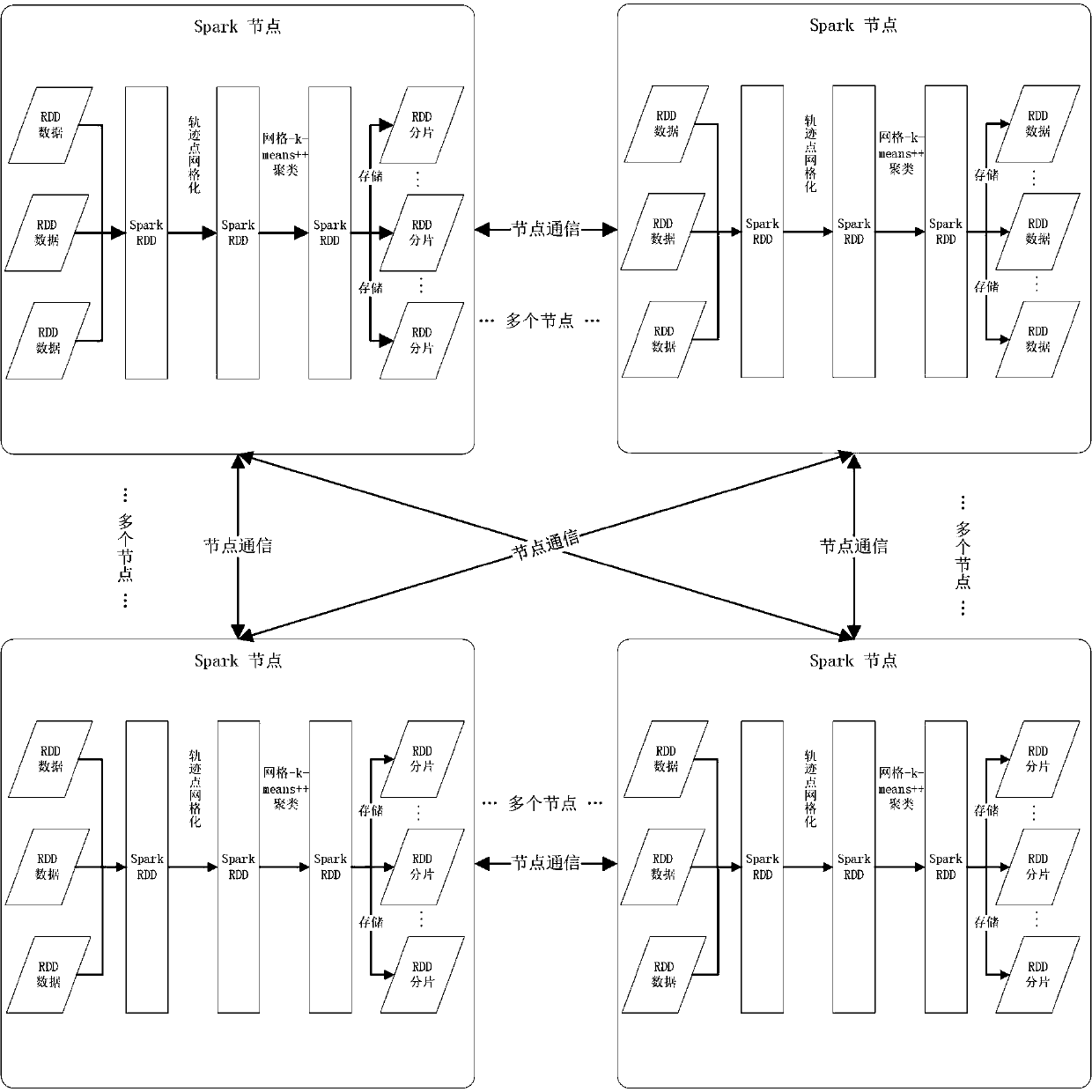
[0094]Scan all data sources, extract the data into the RDD of the Spark cluster to obtain the data set U; divide the data, distribute the divided data to the nodes to obtain the data set {U1, U2, U3...Un}, each node puts The dataset collection is assigned to the Map function, and an interception function is called in the Map function to intercept the last three data fields of each piece of data to obtain the timestamp T, longitude value Long...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More