

Data stream clustering method and device based on density peak value
A data stream clustering and density peak technology, applied in the field of data processing, can solve problems such as clustering performance degradation, achieve the effects of reducing impact, quickly clustering data streams, and ensuring freshness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
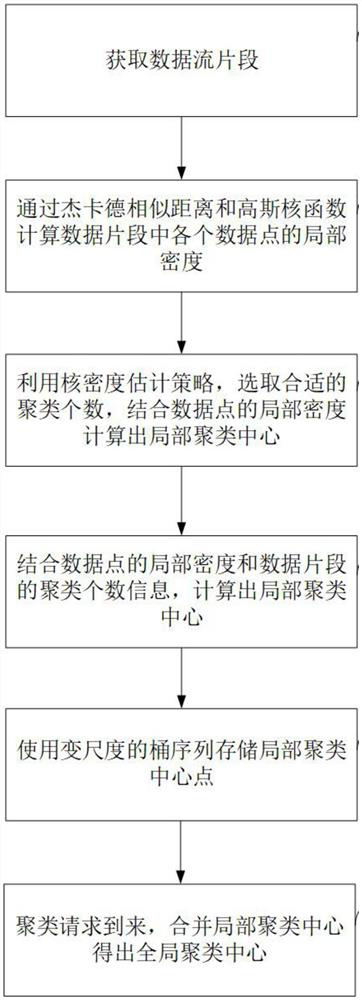
[0053] see figure 1 , figure 1 It is a flowchart of a density peak-based data flow clustering method provided by an embodiment of the present invention. The method for clustering data streams based on density peaks includes the following steps:
[0054] A method for clustering data streams based on density peaks, comprising the following steps:
[0055] Obtain data source information, access data source, and obtain data flow;
[0056] Preprocessing the data stream to obtain data fragments;
[0057] The density calculation is performed on the data points in the data segment through the density formula combining the Jaccard similarity distance and the Gaussian kernel function to obtain the local density of the data points;
[0058] Search the range of cluster numbers through a heuristic strategy, combine the local density of the data points to select the optimal cluster center, and obtain the local cluster center information;
[0059] Using variable-scale bucket structure t...
Embodiment 2
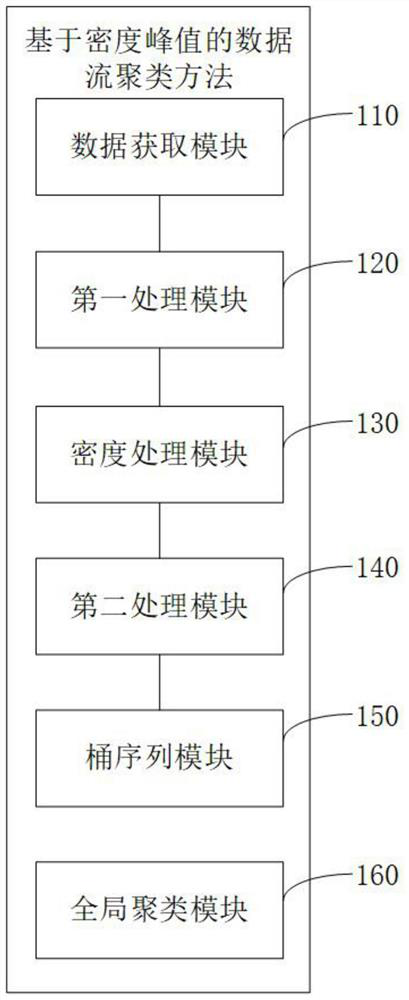
[0080] Based on the same inventive concept, the present invention also proposes a data stream clustering device based on density peaks, please refer to figure 2 , figure 2 A structural block diagram of an apparatus for clustering data streams based on density peaks provided by an embodiment of the present invention. The device for clustering data streams based on density peaks includes:
[0081] A data acquisition module 110, configured to access a data source and acquire a data stream;
[0082] The first processing module 120 is configured to preprocess the data stream to obtain data fragments;
[0083] The density calculation module 130 is used to calculate the density of the data points in the data segment through the density formula combining the Jaccard similarity distance and the Gaussian kernel function to obtain the local density of the data points;
[0084] The second processing module 140 is used to search the range of the number of clusters through a heuristic ...
Embodiment 3
[0093] The embodiment of the present invention also provides a data stream clustering device based on a density peak algorithm, including a processor and a storage medium;
[0094] The storage medium is used to store instructions;
[0095] The processor is configured to operate according to the instructions to perform the steps of the method in Embodiment 1:
[0096] Obtain data source information, access data source, and obtain data flow;
[0097] Preprocessing the data stream to obtain data fragments;
[0098] The density calculation is performed on the data points in the data segment through the density formula combining the Jaccard similarity distance and the Gaussian kernel function to obtain the local density of the data points;
[0099] Search the range of cluster numbers through a heuristic strategy, combine the local density of the data points to select the optimal cluster center, and obtain the local cluster center information;
[0100] Using variable-scale bucket...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More