

Voice synthesis method and system
A technology of speech synthesis and speech synthesis, applied in the field of speech synthesis methods and systems, which can solve the problems of unnatural speech, error accumulation, and consumption of computing resources, etc., to achieve the effect of saving resources and reducing errors
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
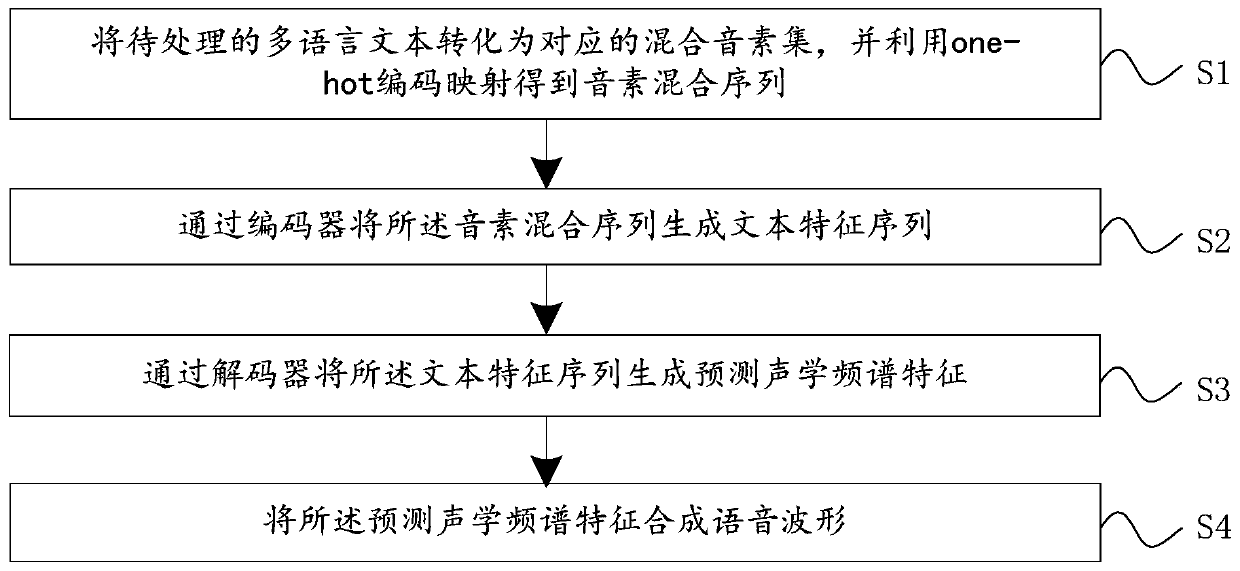
[0052] see figure 1 , figure 1 It is a flowchart of a speech synthesis method provided by an embodiment of the present invention; including:
[0053] S1. Convert the multilingual text to be processed into a corresponding mixed phoneme set, and use one-hot coding mapping to obtain a phoneme mixed sequence;
[0054] S2. Using an encoder to generate a text feature sequence from the phoneme mixture sequence;
[0055] S3. Generating the text feature sequence through a decoder to predict acoustic spectrum features;
[0056] S4. Synthesize the predicted acoustic spectral feature into a speech waveform.
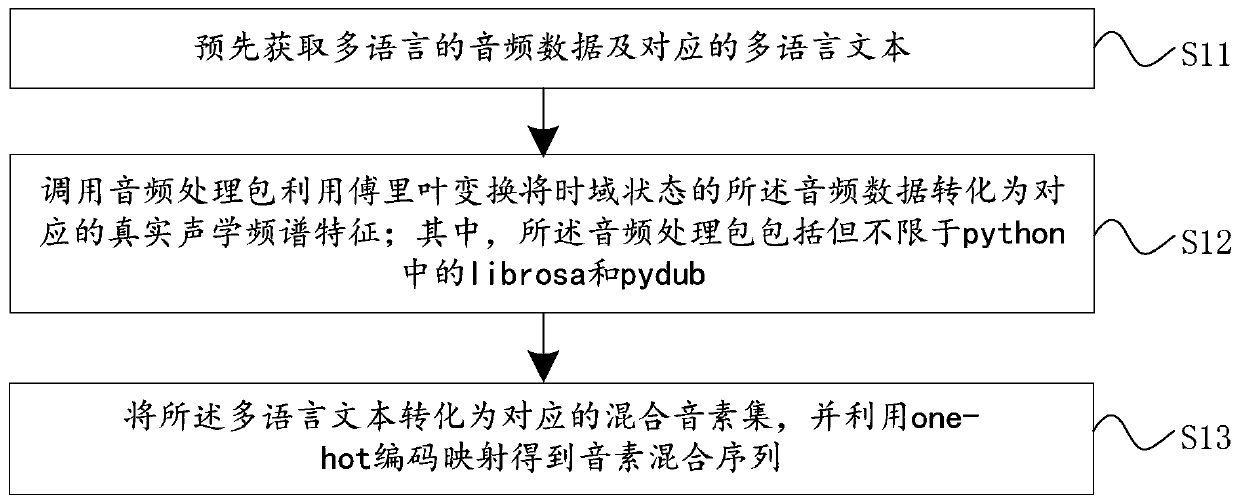
[0057] Specifically, in step S1, before converting the multilingual text to be processed into a corresponding mixed phoneme set, word segmentation, polyphonic characters and punctuation processing need to be performed on the multilingual text to be processed. In the embodiment of the present invention, the mixed phoneme set is a set of mixed phonemes corresponding to the multilingu...
Embodiment 2
[0092] see Figure 5 , Figure 5 It is a structural block diagram of a speech synthesis system provided by an embodiment of the present invention; comprising:
[0093] The preprocessing unit 1 is used to convert the multilingual text to be processed into a corresponding mixed phoneme set, and use one-hot coding mapping to obtain a phoneme mixed sequence;
[0094] An encoder unit 2, configured to generate a text feature sequence from the phoneme mixed sequence through an encoder;
[0095] Decoder unit 3, used to generate predicted acoustic spectrum features from the text feature sequence through a decoder;
[0096] A speech waveform synthesizing unit 4, configured to synthesize the predicted acoustic spectral features into a speech waveform.
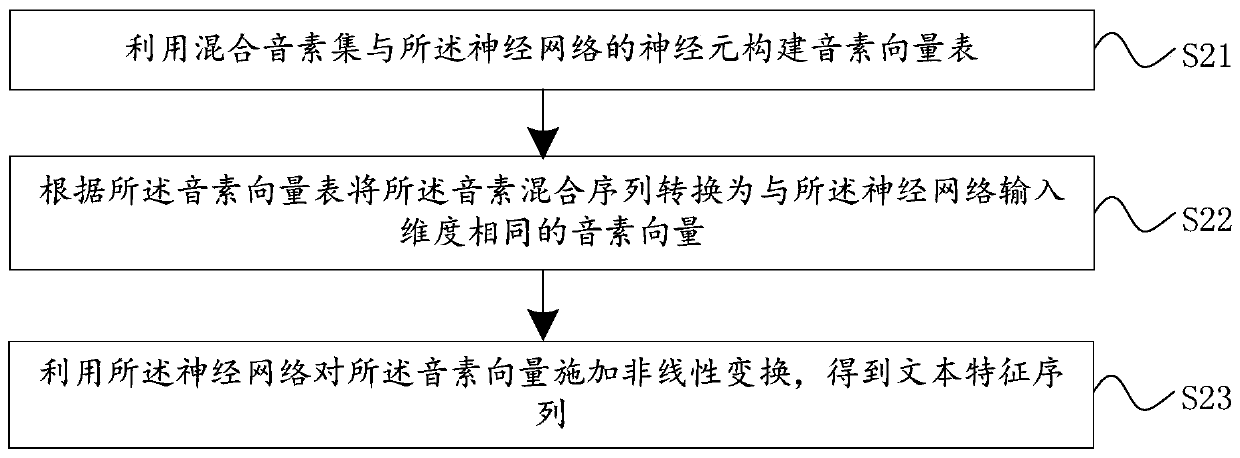
[0097] Preferably, the encoder is trained by a neural network; wherein the neural network includes at least one of a convolutional neural network and a recurrent neural network; then, the encoder unit 2 is specifically used for:
[00...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More