

Multi-source data aggregation sampling method and system based on big data environment
A multi-source data and big data technology, applied in the field of big data, can solve the lack of research on semi-structured and unstructured data preprocessing, the inability to integrate large-scale heterogeneous data sources, and the inability to well meet user needs, etc. problems, to avoid the loss of effective information, reduce storage resources and network bandwidth, and reduce or eliminate noise data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0072] In order to further understand the invention content, features and effects of the present invention, the following embodiments are exemplified, and detailed descriptions are included with the accompanying drawings.
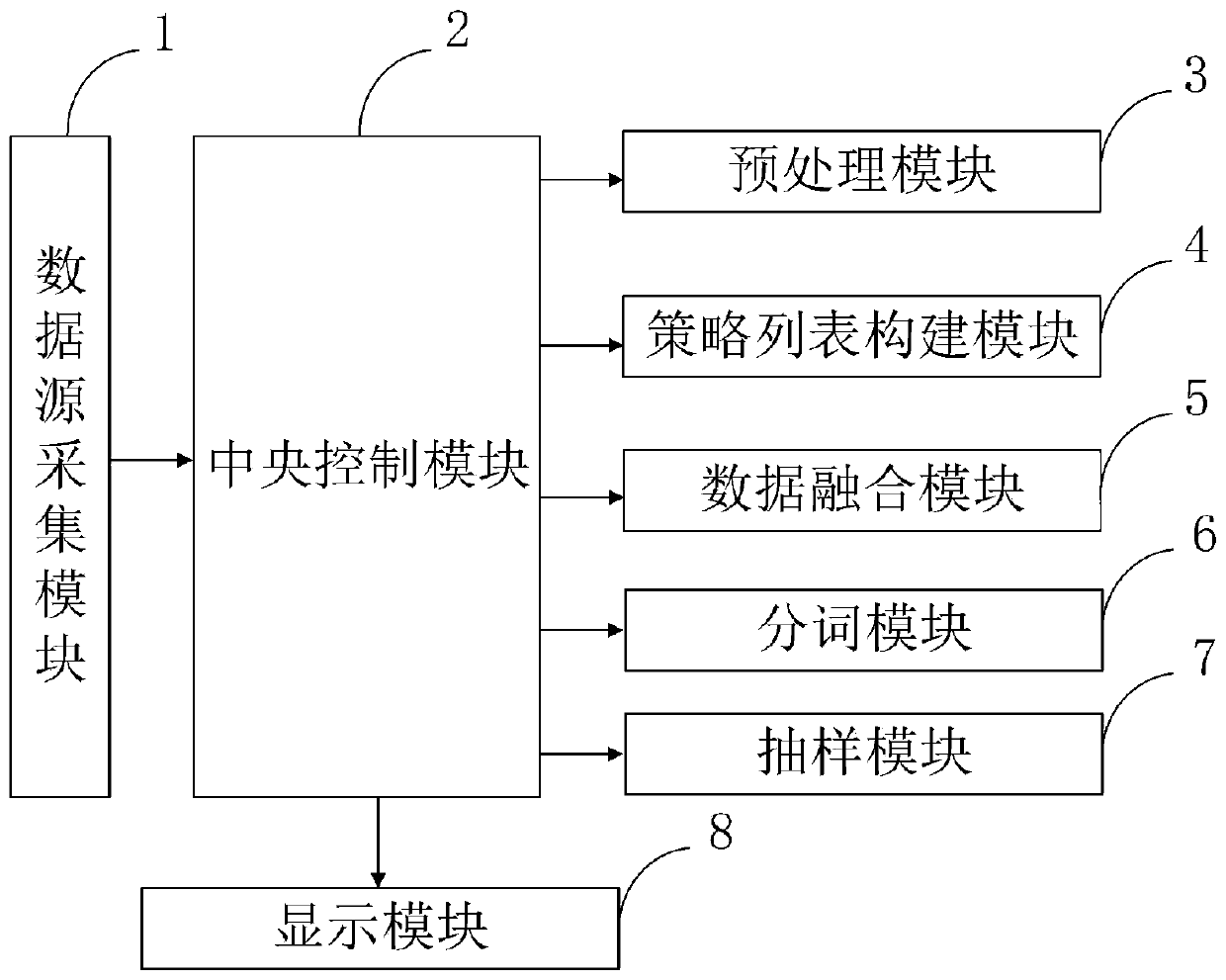
[0073] The structure of the present invention will be described in detail below in conjunction with the accompanying drawings.
[0074] Such as figure 1 As shown, the multi-source data aggregation sampling method based on the big data environment provided by the present invention comprises the following steps:
[0075] S101, collect multiple original data sources through the data source collection module, each original data source includes a data source name and at least one associated field;
[0076] S102, the central control module uses the data processing program to clean, identify and remove redundant operations on the collected data sources through the preprocessing module;
[0077] S103, using the construction program to obtain the original policy l...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More