

A two-stream video classification method and device based on cross-modal attention mechanism
A video classification and attention technology, applied in the field of computer vision, can solve problems such as difficult to quickly and accurately locate key objects, "moving objects" without modeling methods, and less research, to achieve improved video classification accuracy, improved classification accuracy, and better The effect of compatibility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

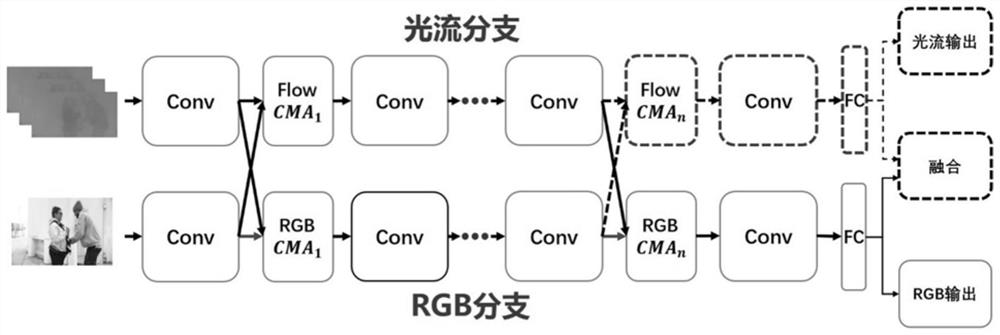
Examples
Embodiment Construction
[0035] In order to make the above objects, features and advantages of the present invention more comprehensible, the present invention will be further described in detail below through specific embodiments and accompanying drawings.
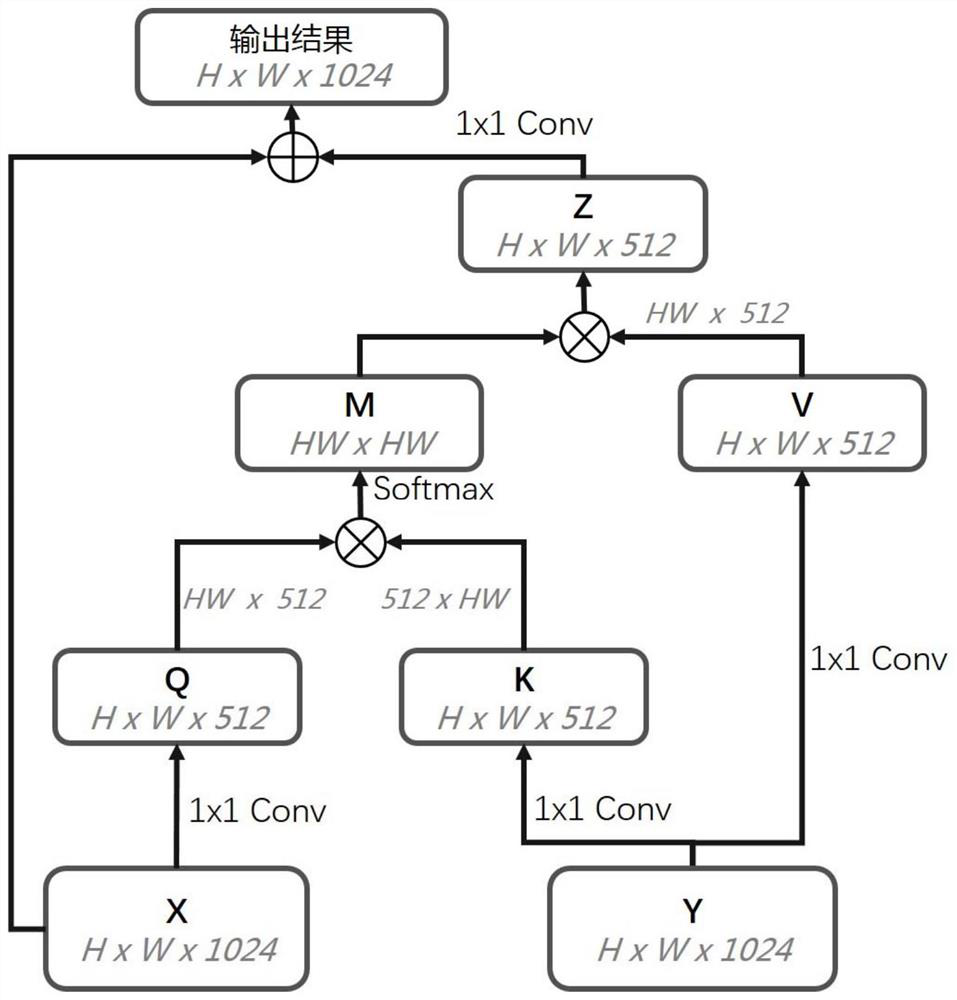
[0036] 1. Configuration of cross-modal attention module
[0037] The cross-modal attention module can handle input of any dimension, and can ensure that the shape of the input and output is consistent, so it has excellent compatibility. Taking the 2-dimensional configuration as an example, Q, K, and V are respectively obtained by 1x1 2-dimensional convolution operation (for 3-dimensional models, the convolution here is 1x1x1 3-dimensional convolution operation), in order to reduce computational complexity and save In GPU space, the above convolution operation performs dimensionality reduction in the channel dimension while obtaining Q, K, and V. In order to further simplify the operation, a max-pooling operation can be performed before the convolu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More