

Multi-modal emotion recognition method based on fusion attention network
An emotion recognition and multi-modal technology, applied in character and pattern recognition, special data processing applications, instruments, etc., can solve problems such as not considering the importance of state information, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

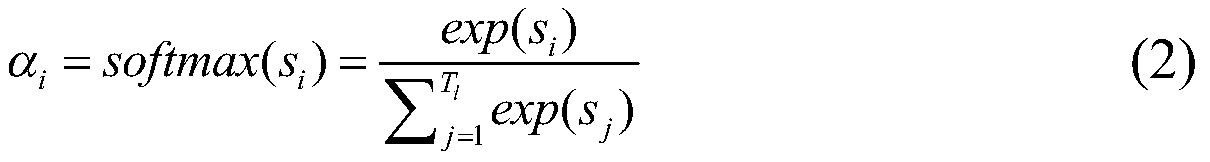
Examples
Embodiment Construction
[0026] The present invention will be further described below in conjunction with drawings and embodiments.
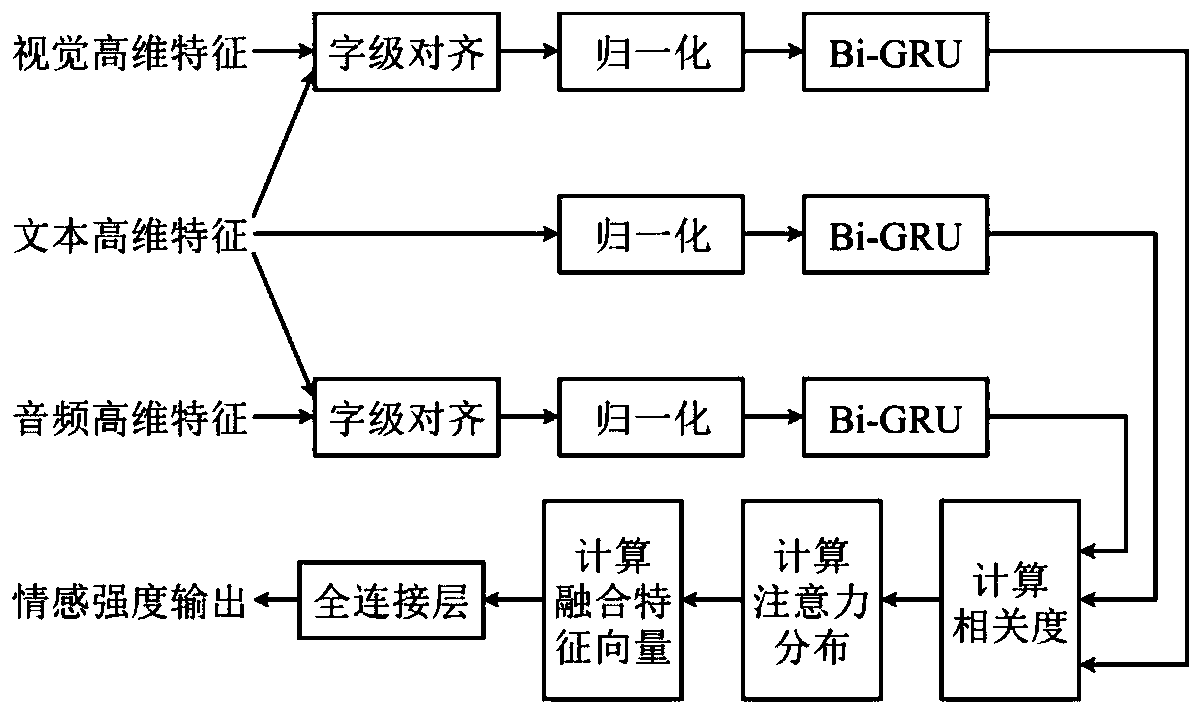
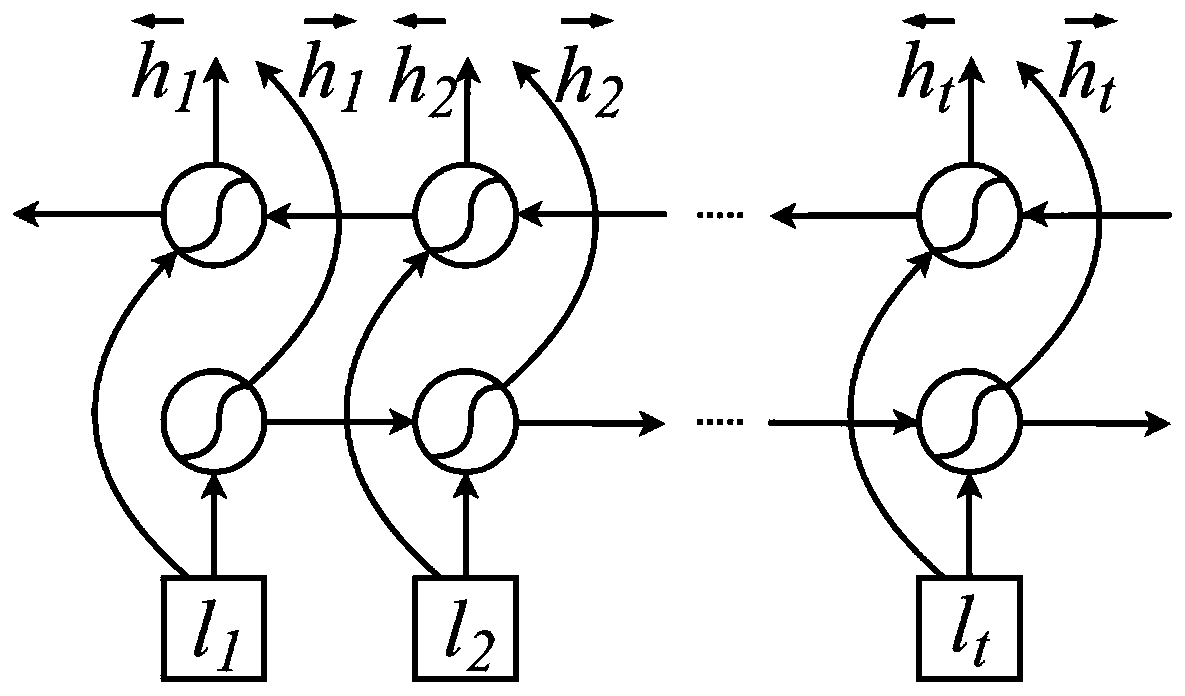
[0027] refer to figure 1 and figure 2 , a multimodal emotion recognition method based on a fusion attention network, comprising the following steps:
[0028] Step 1, extracting high-dimensional features of the three modalities of text, vision and audio, the process is:
[0029] Extract text features as where T l is the number of words in the opinion speech video, in this embodiment, T l =20,l t Represents 300-dimensional Glove word embedding vector features; FACET visual features are extracted using the FACET facial expression analysis framework as Among them, T v is the total number of frames of the video, and the p visual features extracted at the jth frame are In this embodiment, p=46; use the COVAREP acoustic analysis framework to extract the COVAREP audio features as Among them, T a is the segmented frame number of the audio, and the q acoustic featur...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More