

Visual question and answer fusion enhancement method based on multi-modal fusion
A multi-modal and visual technology, applied in the fields of natural language and computer vision, can solve the problem that the answer features do not play, ignore, and cannot play a huge role in the answer information, and achieves the improvement of accuracy, accuracy and diversity. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0022] In order to make the above objects, features and advantages of the present invention more comprehensible, the present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
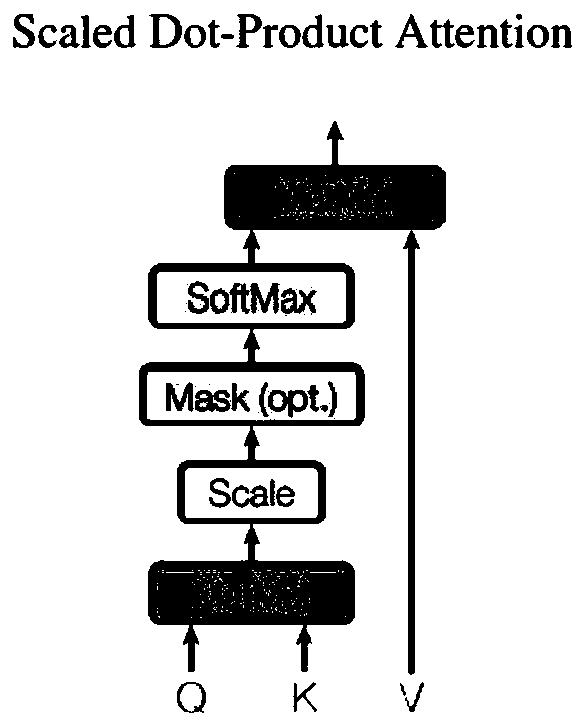
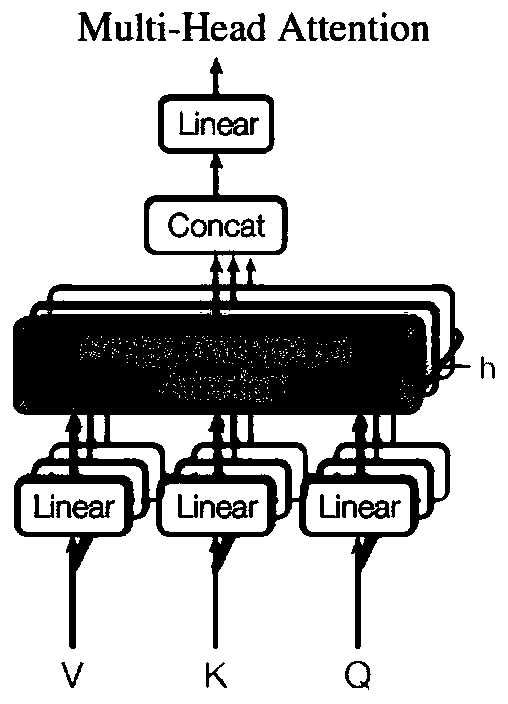
[0023] The multi-modal fusion-based visual question-and-answer fusion enhancement method proposed by the present invention, such as Figure 1-4 shown, including the following three steps:
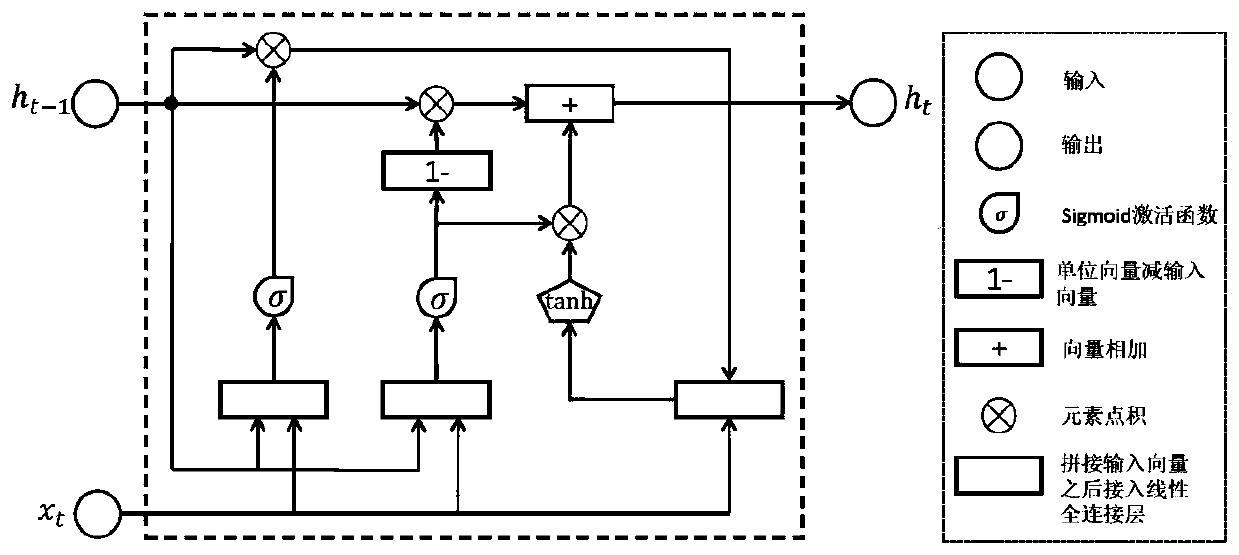
[0024] Step 1. Use the GRU (Gated Recurrent Unit) structure to construct a time series model, obtain the feature representation learning of the problem, and use the output of the bottom-up attention model extracted from Faster R-CNN as the feature representation of the image. In the present invention, each word in the sentence is sequentially input into the GRU model in sequence, and the GRU output of the last word in the sentence can represent the entire sentence.
[0025] Such as figure 1 As shown, there are two gates in the GRU, one is the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More