

Emotion reason mining method based on dependency syntax and generalized causal network
A technology that relies on syntax and causal networks, and is applied in the direction of network data retrieval, network data query, and other database retrieval, etc. It can solve problems such as error in analysis results, expansion needs to be improved, and limited scope of use, etc., to achieve the effect of improving the matching degree
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
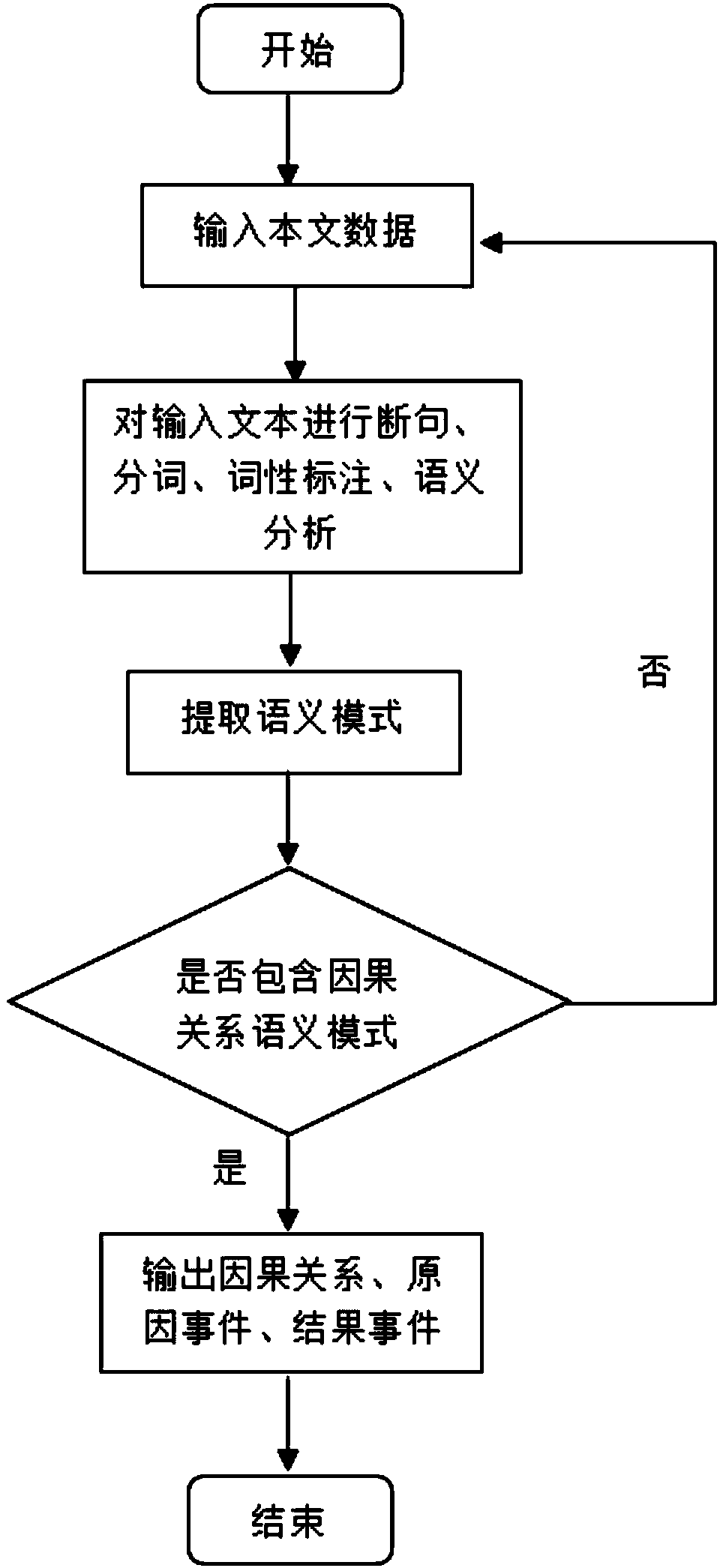
[0037] The emotional cause mining method based on dependency syntax and generalized causal network proposed in this paper is mainly used to discover the causal relationship of texts and find out the rules of its operation. When digging for emotional causes, follow the steps described below.
[0038] figure 1 It is a flow chart of the present invention for extracting causality based on dependency syntax.
[0039] The first step: Use the existing crawler framework webmagic to crawl the news data of Tianya website as the input data of this method. The crawling method is mainly divided into three steps. First, according to the seed link, extract the target link and put it in the queue to be crawled; then parse and extract the required information from the page, where webmagic will use the Jsoup component to parse the html page; finally process Data, the extracted data is stored in file format or stored in databases and search engine index libraries, etc.
[0040] The second ste...
Embodiment 2
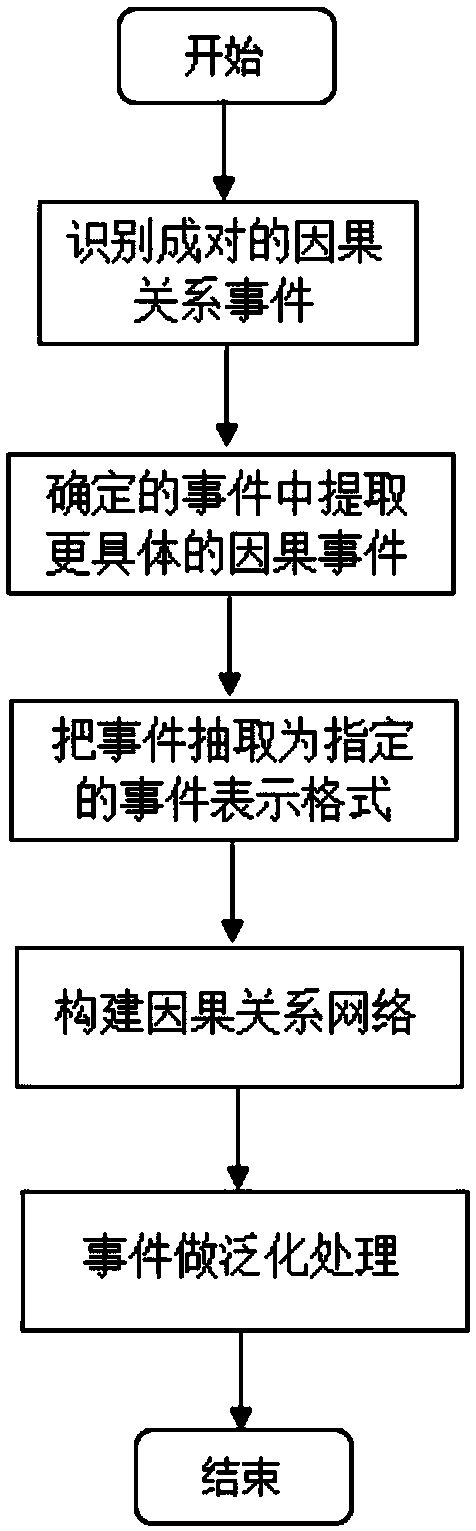
[0050] The emotional cause mining method based on dependency syntax and generalized causal network can not only be applied to the field of emotional cause mining, but also be applied to analyze the causes of major events. Provide guidance and suggestions for the government to control the public opinion trend of major events.
[0051] Step 1: Use the existing crawler framework webcollector to crawl the news data of Sina website. webcollector is a JAVA crawler framework (kernel) that does not require configuration and is convenient for secondary development. A powerful crawler can be implemented with only a small amount of code. First, customize the request header. In some crawling tasks, some websites have a strong anti-crawling mechanism and require login, and there may be other requests. At this time, you need to customize the request header to encapsulate the cookie information after login. The method is very simple, you can easily customize the request header by rewriting ...
Embodiment 3
[0062] The first step is to use the existing crawler framework to crawl news data as the input data of this method. The existing mainstream crawler frameworks include Heritrix, jspider, webmagic, etc., because webmagic is a Java stand-alone crawler, which meets the experimental requirements and is easy to operate, so we use the webmagic crawler framework.
[0063] The second step is to segment the input text data according to the punctuation marks. This process is mainly realized by using the existing tokenizers. The mainstream tokenizers include word tokenizers, Ansj tokenizers, and Stanford tokenizers. Because Stanford The accuracy of the tokenizer is high, so we use the Stanford tokenizer to divide each sentence into a series of words; then use Stanford's CTB to tag each word with part of speech. Finally, the semantic analysis of the sentence is performed using the Stanford parser.
[0064] The third step is to extract semantic patterns from the text according to the binar...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More