

Reinforced learning path planning algorithm based on potential field
A technology of reinforcement learning and path planning, applied in the field of reinforcement learning path planning algorithm based on potential field, which can solve problems such as difficult planning, large amount of calculation, and increased calculation amount of algorithm
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
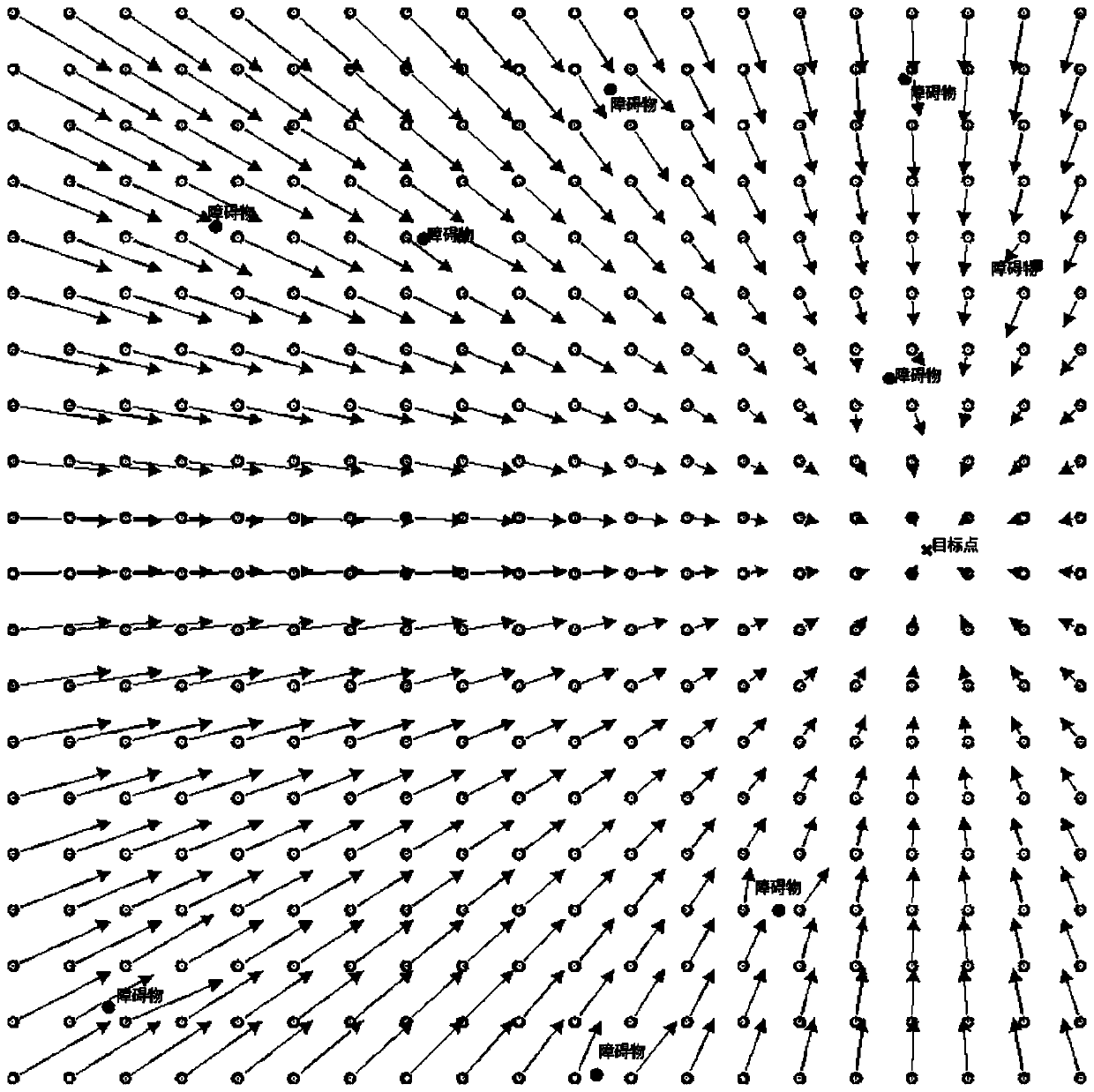
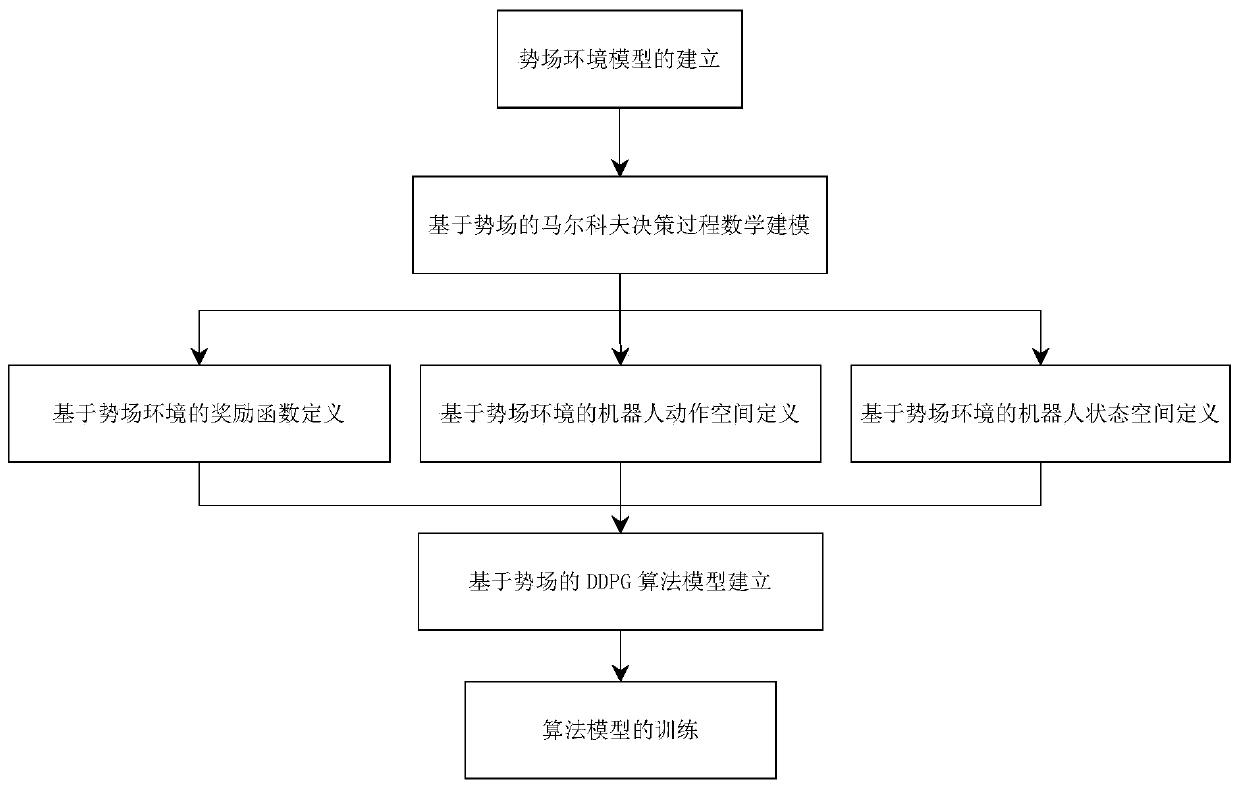
[0036] According to the number n and position of obstacles in the environment and sports waste Use the artificial potential field method to define the environment model, and define the repulsive potential field at the obstacle i according to the above-mentioned repulsive potential field and gravitational potential field formulas The gravitational potential field U at the target position a (P);
[0037] Define the path planning problem under the potential field as a reinforcement learning problem, define the Markov decision-making process according to the above-mentioned state function formula, action function formula, and reward function formula, and use the DDPG algorithm to optimize the decision-making process;
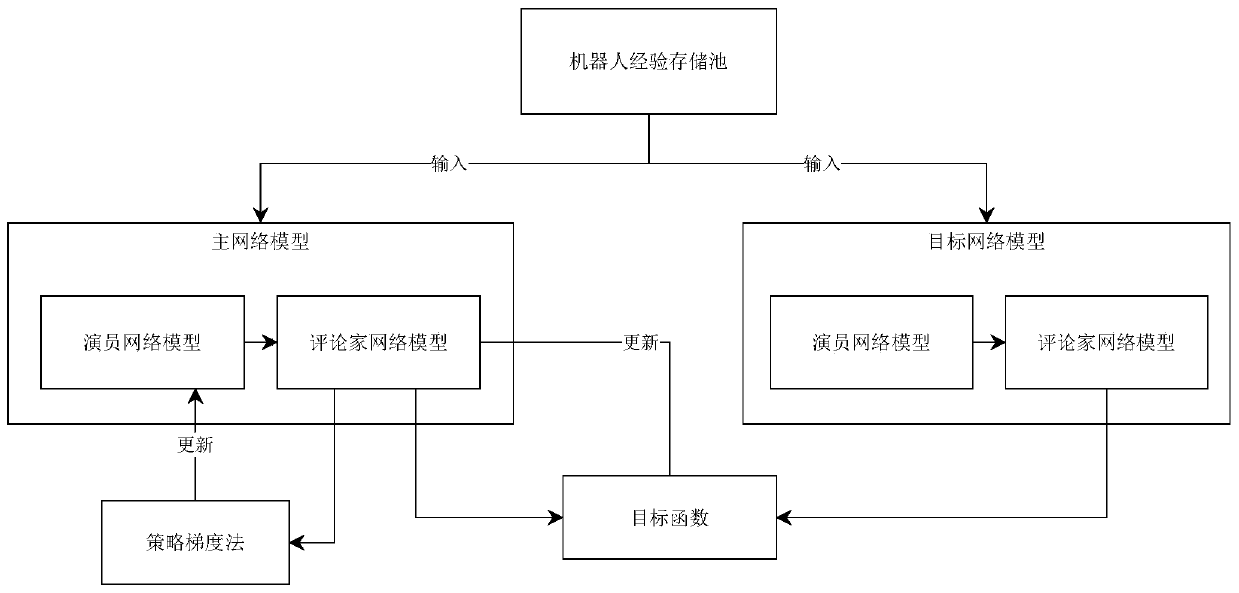
[0038] Establish the main network model and target network model in the DDPG reinforcement learning algorithm. The main network model updates parameters according to the gradient, and the target network updates parameters in the form of soft update. The two net...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More