

Text similarity matching model compression method and system for knowledge distillation
A text similarity and matching model technology, applied in the field of text matching, can solve the problems of small calculation, calculation speed bottleneck, complex model, etc., to achieve the effect of improving accuracy and avoiding the decrease of calculation speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0046] The preferred embodiments of the present invention will be described below in conjunction with the accompanying drawings. It should be understood that the preferred embodiments described here are only used to illustrate and explain the present invention, and are not intended to limit the present invention.
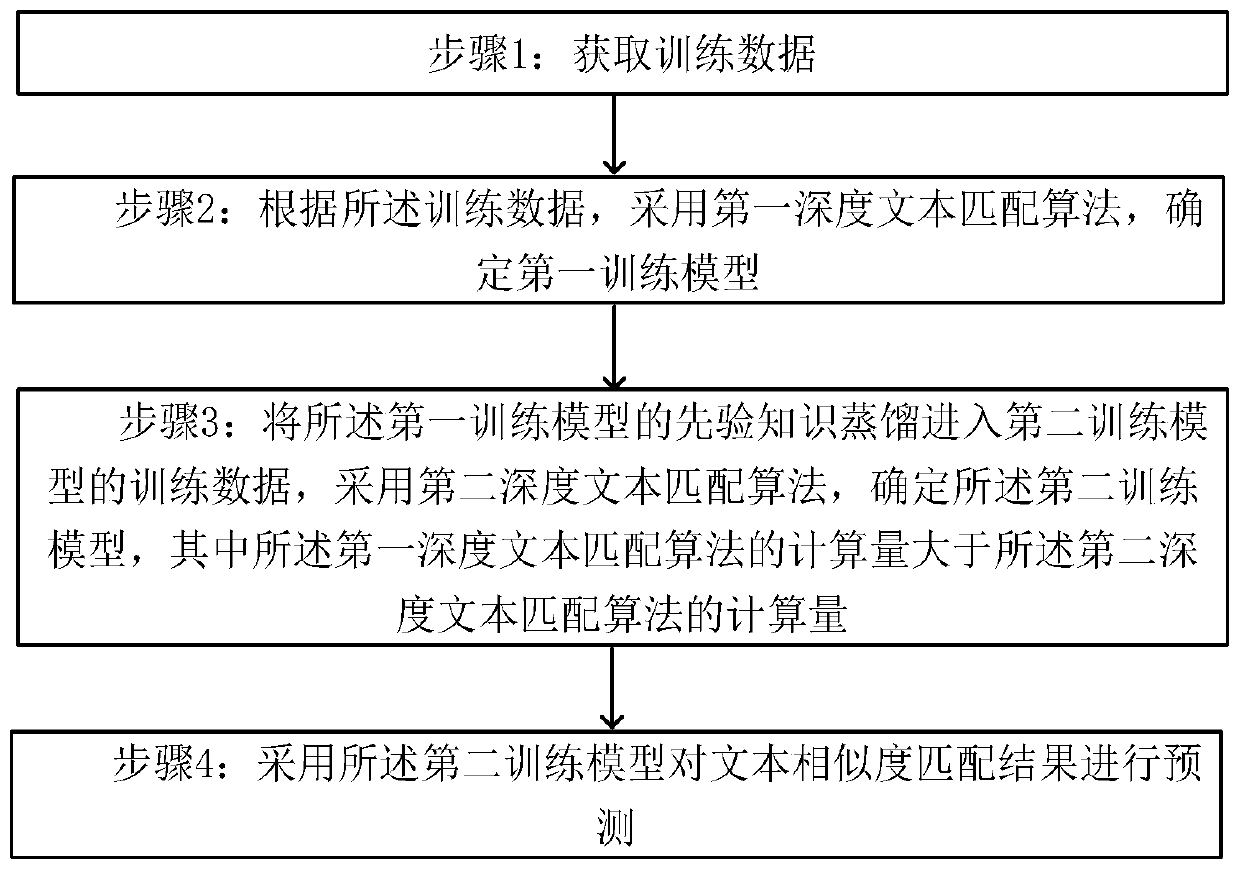
[0047] The embodiment of the present invention provides a text similarity matching model compression method of knowledge distillation, such as figure 1 As shown, the method performs the following steps:
[0048] Step 1: Obtain training data;
[0049] Step 2: According to the training data, using the first deep text matching algorithm to determine the first training model;
[0050] Step 3: Distill the prior knowledge of the first training model into the training data of the second training model, and use the second deep text matching algorithm to determine the second training model, wherein the first deep text matching algorithm The calculation amount is greater th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More