

BPE-Learn acceleration method for sub-word segmentation
A sub-word and vocabulary technology, applied in the field of BPE-Learn acceleration for sub-word segmentation, can solve the problems of GPU resource waste, consume a lot of time, and do not allow data segmentation statistics, so as to improve GPU usage and shorten statistics time. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0036] The present invention will be further elaborated below in conjunction with the accompanying drawings of the description.
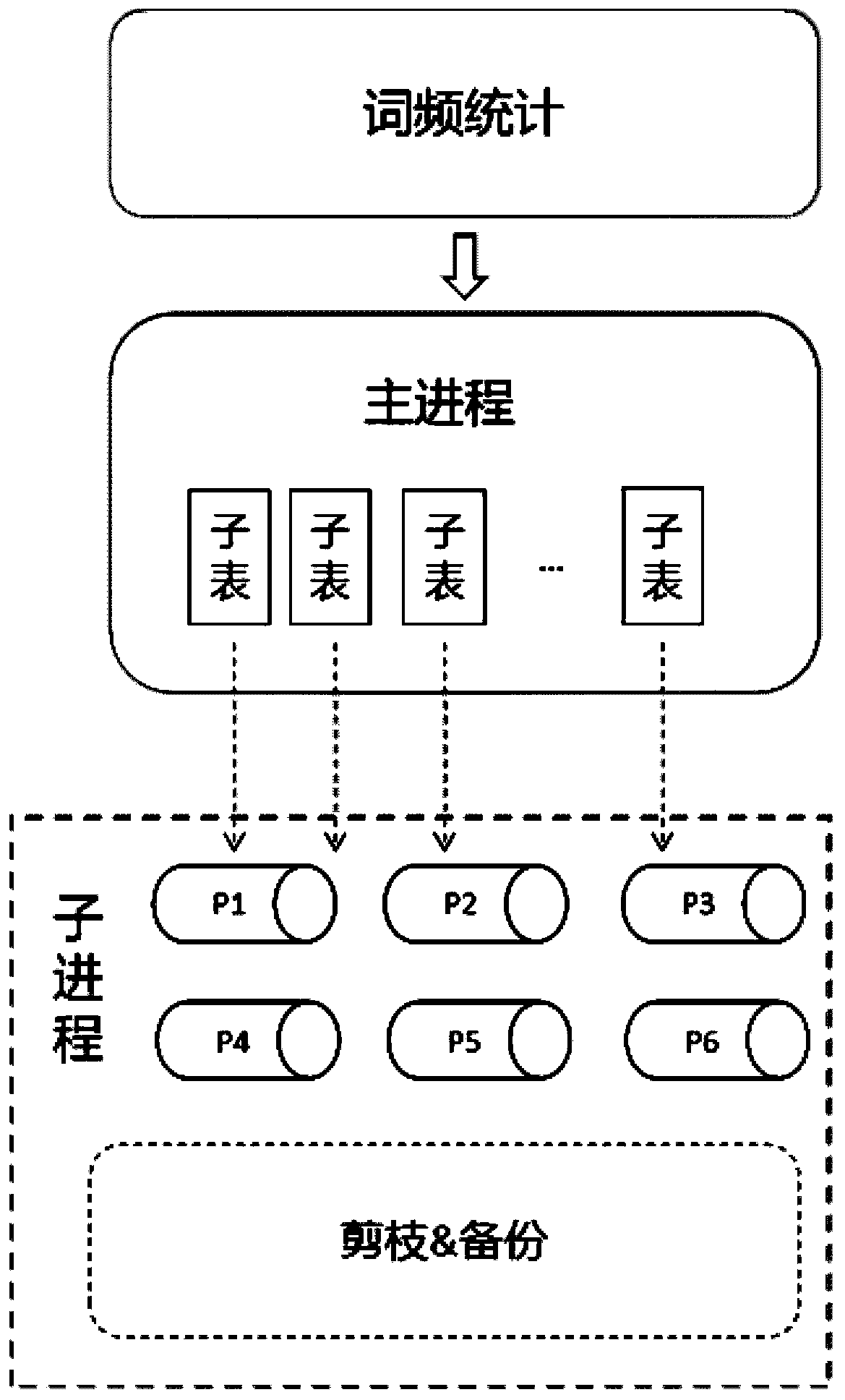
[0037] The present invention proposes a BPE-Learn acceleration method oriented to subword segmentation, uses multi-process statistics and an interactive mode to accelerate the BPE-Learn algorithm, and solves the serious time-consuming problem of subword segmentation in neural machine translation training.
[0038] like figure 2 Shown, BPE-Learn algorithm acceleration of the present invention comprises the following steps:
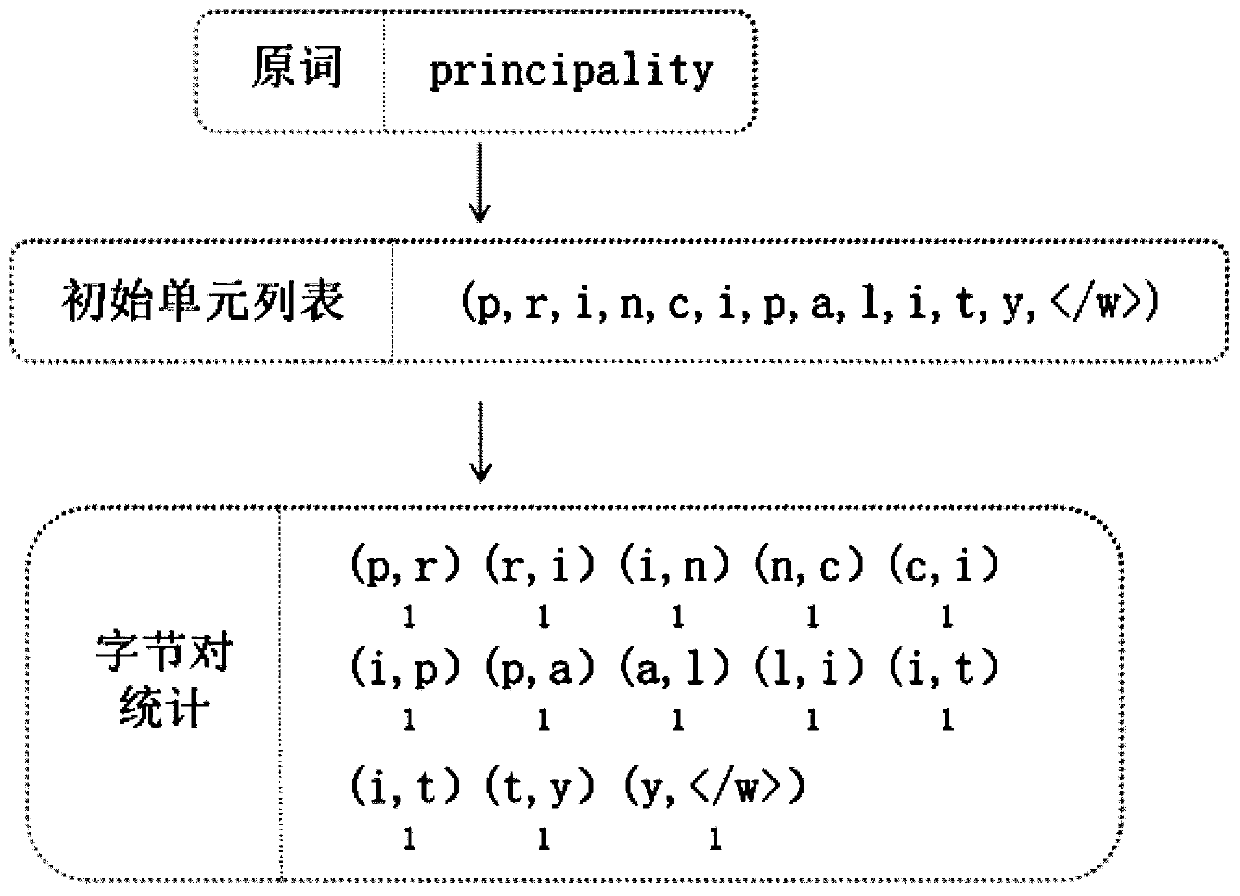
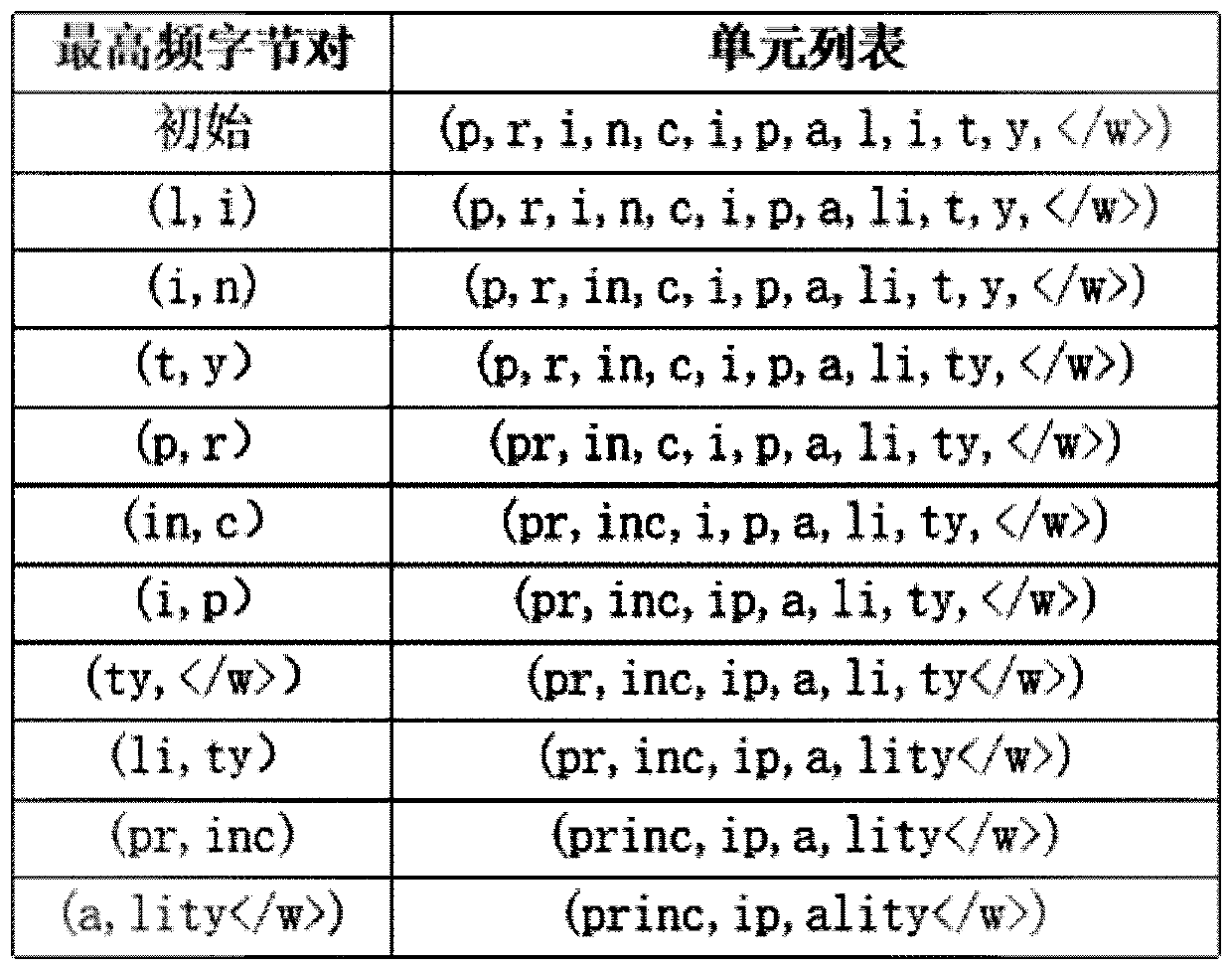
[0039] 1) Read in the training data, segment the data according to spaces, count the number of times each word appears in the corpus, and record it as a vocabulary;
[0040] 2) Divide the vocabulary into N sub-tables, create an independent sub-process for each sub-table for byte pair statistics, and assign a communication queue to each sub-process for interaction with the main process;
[0041] 3) In the sub-process, the chara...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More